
В прошлый раз мы говорили про виды таблиц для быстрой работы с Big Data в Apache Hive. Сегодня поговорим про создание пользовательских функций и их применение в Hive. Читайте далее про особенности создания и применения UDF для работы с Big Data в распределенной платформе Apache Hive.
Что такое пользовательские функции в Hive: особенности создание и применения
Пользовательские функции (User Defined Functions, UDF) — это функции для работы с данными, которые не являются встроенными и создаются пользователем для выполнения специализированных (индивидуальных) задач и получения желаемого результата. Для того, чтобы создать пользовательскую функцию в Hive, необходимо определить собственный (невстроенный) класс, который наследуется от встроенного класса UDF. Например, следующий код на языке Java отвечает за создание класса, который используется для определения пользовательской функции в Hive:
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.*;
@Description ()
public class ExanpleUDF extends UDF{
}
Как видно из кода, при создании UDF-класса, используется аннотация @Description(), которая отвечает за описание UDF-функции (имя и описание).
Работа с пользовательскими функциями в Hive: несколько практических примеров
Для того, чтобы создать UDF-функцию для работы с Hive, необходимо настроить базовую конфигурацию, подгрузив необходимые Hive-библиотеки. В качестве сборщика проектов можно использовать Apache Maven, так как он имеет возможность напрямую подгружать все необходимые библиотеки из нужных источников. Это освобождает разработчика от необходимости вручную загружать и устанавливать необходимые библиотеки для работы с конкретными инструментариями (например, Hive, Spark, Kafka) в проекте. В первую очередь для работы с Hive необходимо установить maven-зависимости (чтобы подгрузить актуальную версию инструментария для работы с Hive). Следующий код на языке разметки XML отвечает за настройку Hive-зависимостей в файле pom.xml [1]:
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.3</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> <scope>provided</scope> </dependency> </dependencies>
После сборки проекта необходимо создать класс, определяющий UDF-функцию. В качестве примера можно создать функцию, которая принимает строковое значение из таблицы и возвращает его в нижнем регистре. Следующий код на языке Java отвечает за создание класса, который определяет функцию для перевода всех строковых значений Hive-таблицы в нижний регистр [1]:
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.*;
// Описание UDF-функции
@Description(
name="ExampleUDF",
value="Возвращение строковых значений таблицы в нижнем регистре.")
public class ExampleUDF extends UDF {
// Метод, который принимает строковые значения в качестве параметра
public String evaluate(String input) {
// Если значение строки Null, то возвращаемый результат тоже Null
if(input == null)
return null;
// Возвращение строкового результата в нижнем регистре
return input.toLowerCase();}
}
Для того, чтобы использовать созданную функцию, ее необходимо упаковать и скомпилировать. Для этого в командной строке необходимо ввести следующую maven-команду:
mvn compile package
После упаковки и компиляции файл созданной функции необходимо добавить в Hive-репозиторий следующим образом:
ADD JAR wasbs:///example/jars/ExampleUDF-1.0-SNAPSHOT.jar; CREATE TEMPORARY FUNCTION toLower as 'com.microsoft.examples.ExampleUDF';
Приведенный выше фрагмент кода позволяет зарегистрировать в Hive созданную UDF-функцию c именем toLower. Для того, чтобы использовать эту функцию, необходимо ее вызвать через SQL-запрос в редакторе Hive следующим образом [1]:
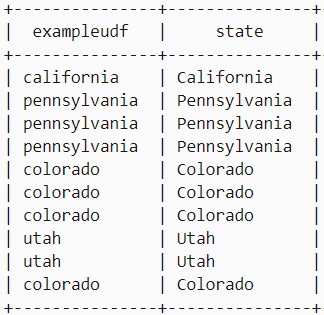
SELECT toLower(state) AS ExampleUDF, state FROM hivesampletable LIMIT 10;
Этот запрос отображает название стран из колонки state в нижнем регистре.
Таким образом, благодаря поддержке пользовательских функций, Apache Hive позволяет пользователям работать с данными, не ограничивая их в методике обработки больших массивов данных, что делает его весьма полезным средством для работы с Big Data.
Больше подробностей про применение Apache Hive в проектах анализа больших данных вы узнаете на практических курсах по Hive в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
MPA: CLOUDERA IMPALA DATA ANALYTICS
ADQM: ЭКСПЛУАТАЦИЯ ARENADATA QUICKMARTS
ADBR: Arenadata DB для разработчиков
ADB: Эксплуатация Arenadata DB
HBASE: Администрирование кластера HBase
HIVE: Hadoop SQL администратор Hive
NoSQL: Интеграция Hadoop и NoSQL
Источники

