
18 марта 2024 года вышел очередной релиз Apache Flink. Знакомимся с его главными новинками и разбираемся, чем они полезны для потоковой обработки больших данных: ключевые изменения выпуска 1.19 для разработчика stateful-приложений. Динамическая настройка параллелизма Выпуск Apache Flink 1.19 можно назвать значимой вехой, поскольку он не только включает новые функции, улучшения...
Потоковая обработка данных из PostgreSQL с Flink SQL на платформе Ververica Cloud

Как с помощью Flink SQL организовать потоковую агрегацию данных из таблицы PostgreSQL: знакомство с API таблиц в Ververica Cloud на практическом примере. API таблиц Ververica Cloud: создаем внешние источники и приемники данных Как я недавно рассказывала, немецкая фирма Ververica создала высокопроизводительный облачный сервис для обработки данных в реальном времени на...
4 модели потоковой парадигмы обработки данных
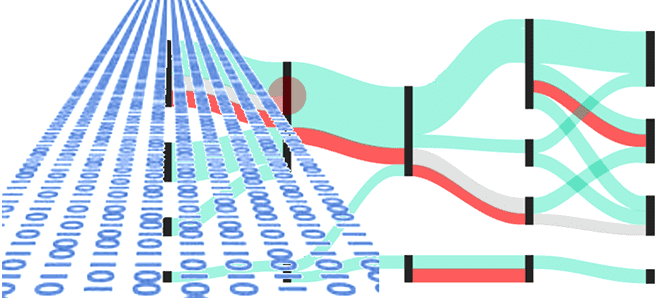
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink. Еще раз о разнице потоковой и пакетной парадигмы обработки данных Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных....
Планирование заданий в Apache Flink: 4 реализации планировщика
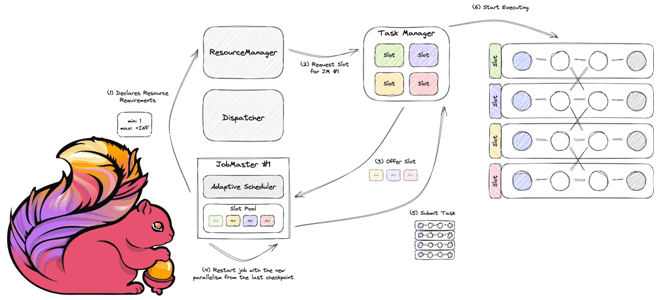
Как работает планировщик заданий в Apache Flink, чем разные реализации Scheduler отличаются друг от друга, и каковы преимущества адаптивных планировщиков. Как Apache Flink планирует выполнение заданий клиентской программы Архитектура Apache Flink, которую мы рассматривали здесь, включает несколько компонентов. Одним из них является планировщик заданий, которые отправляются клиентским приложением в диспетчер...
Зачем Ververica Cloud заменила RocksDB на GeminiStateBackend для stateful-приложений Apache Flink

Что такое Ververica Runtime Assembly, чем GeminiStateBackend лучше RocksDB и еще несколько отличий коммерческого облачного решения от открытого Apache Flink. Что такое Ververica Cloud и при чем здесь Apache Flink Технологии с открытым исходным кодом развиваются намного быстрее при поддержке крупных корпораций. Например, компания Confluent продвигает Apache Kafka, Astronomer –...
Обратное давление в потоковой передаче событий
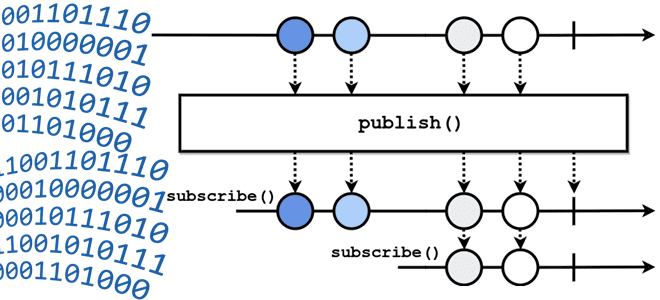
Что означает термин backpressure и зачем создавать обратное давление в streaming-системах: разбираемся с методами управления пропускной способностью потоковой передачи событий на примере Apache Kafka, Flink, Spark и NiFi. Что такое обратное давление: backpressure в конвейерах потоковой обработки данных Понять, как работает сложная концепция, проще всего на простых примерах. Это общее...
Что нас ждет в Apache Flink 2.0: обзор главных фич мажорного релиза

В конце декабря принято строить планы на следующие 12 месяцев. Посмотрим, что разработчики Apache Flink обещают реализовать в релизе 2.0, который должен выйти к концу 2024 года. Внедрение многоуровневой системы хранения состояний В Apache Flink 2.0 будет улучшена система управления хранилищем состояния путем перехода к полностью разделенной архитектуре хранения и...
Еще одна архитектура данных: Streamhouse с Apache Paimon
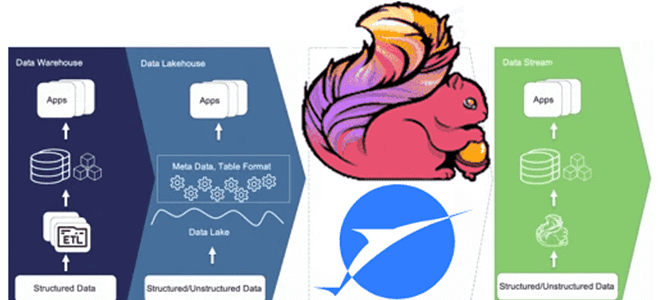
Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon. Что такое архитектура данных Streamhouse Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость...
Что обеспечивает высокую доступность приложений Apache Flink
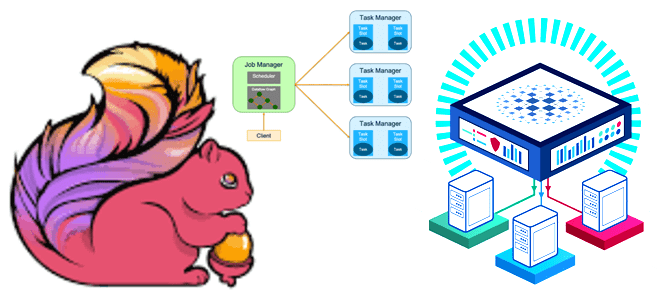
Как работает Flink-приложение, из каких компонентов состоит распределенный кластер и как сделать его отказоустойчивым. Архитектура и принципы работы высокой доступности Apache Flink. Архитектура Flink-приложения: ключевые компоненты и связь между ними Перед тем, как погружаться в средства обеспечения высокой доступности Flink-приложения, вспомним базовые принципы его работы. Сам по себе Apache Flink...
Возможности Apache Flink для разработчика: 3 API фреймворка
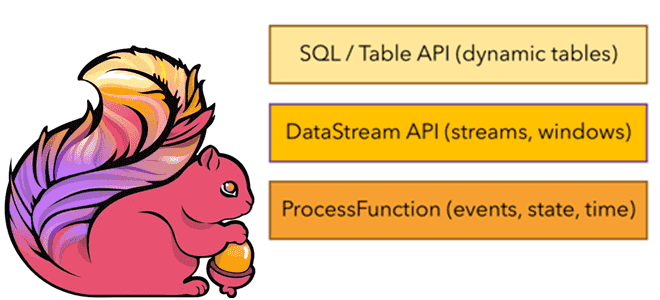
Какие возможности Apache Flink предоставляет разработчику и как их использовать: краткий обзор существующих API и потоковых примитивов. Потоковые примитивы и низкоуровневый API Будучи популярным фреймворком для stateful-вычислений над неограниченными и ограниченными потоками данных, Apache Flink предоставляет несколько API на разных уровнях абстракции и предлагает специальные библиотеки для различных сценариев. На...