
Сегодня разберем тему, особенно полезную для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink: обнаружение сложных цепочек связанных событий в потоковой обработке. Как создать свой шаблон поиска сложных событий с библиотекой FlinkCEP. Комплексная обработка событий или зачем вам CEP Современный data-driven бизнес хочет принимать...
Как развернуть Apache Flink на Kubernetes: 4 способа
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica. Зачем и как выполнить развертывание Apache...
3 проблемы Flink-приложений на Kubernetes и способы их решения

Сегодня рассмотрим, с какими нетиповыми ошибками может столкнуться дата-инженер при работе с Apache Flink, а также как решить эти проблемы. Где и что править, когда сервер BLOB-объектов завис из-за слишком большого количества подключений, почему не хватает памяти при развертывании Flink-приложений в кластере Kubernetes и как ускорить инициализацию заданий. Особенности работы...
Мониторинг Flink-приложений: метрики JVM и RocksDB
Мы уже рассматривали важность мониторинга приложений Apache Flink и говорили про метрики отслеживания задержки обработки данных в потоковых заданиях. Сегодня заглянем под капот этого фреймворка и разберем, какие показатели работы JVM, а также RocksDB особенно важны для дата-инженера и разработчика распределенных приложений. Метрики JVM во Flink-приложениях Напомним, основным языком разработки...
Мониторинг задержки в приложениях Apache Flink
Недавно мы говорили про непрерывный мониторинг Flink-приложений и подробно рассмотрели метрики состояния и пропускной способности. В продолжение этой важной для разработчиков и дата-инженеров темы, сегодня рассмотрим, как идентифицировать временную задержку обработки данных. Пользовательские метрики задержки в потоковых приложениях Для потоковых приложений, которые обрабатывают события в режиме, близком к реальному времени,...
Мониторинг приложений Apache Flink: метрики и инструменты
Специально для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink, рассмотрим наиболее важные системные показатели, а также инструменты мониторинга этих метрик. Мониторинг Flink-приложений: особенности и метрики В общем случае мониторинг приложений гарантирует, что ПО обрабатывает данные и выполняет запрошенные действия ожидаемым образом. Непрерывное отслеживание...
3 режима восстановления и форматы точек сохранения в Apache Flink 1.15

Недавно мы писали про главные новинки свежего релиза Apache Flink 1.15, особенно важные с точки зрения обучения разработчиков распределенных приложений и дата-инженеров. Сегодня рассмотрим подробнее, зачем в этом выпуске введены дополнительные режимы восстановления потоковых stateful-заданий из моментальных снимков, когда и какой режим использовать, а также как выбрать формат точки сохранения...
Табличное хранилище Apache Flink
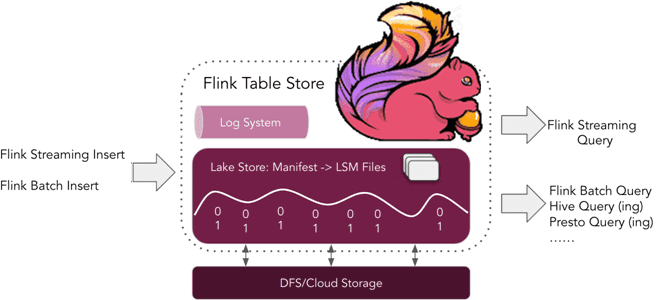
Что такое табличное хранилище Apache Flink, зачем это нужно и почему оно пока не рекомендуется для применения в реальных проектах. Краткий обзор Apache Flink Table Store 0.1.0 для дата-инженеров и разработчиков распределенных приложений. Что такое Flink Table Store и зачем это нужно Уже более полугода, с релиза 1.14, выпущенного в...
Новинки Apache Flink 1.15: краткий обзор

Весна богата на новые релизы: в начале мая 2022 года вышел Apache Flink 1.15. Рассказываем, что нового в свежем выпуске: краткий обзор самых полезных фич для разработчика распределенных приложений, а также интересные изменения, исправления ошибок и улучшения для дата-инженера. Scala под капотом и спецификация REST API по стандарту OpenAPI Apache...
Управление перемешиванием данных во время выполнения Flink-приложений
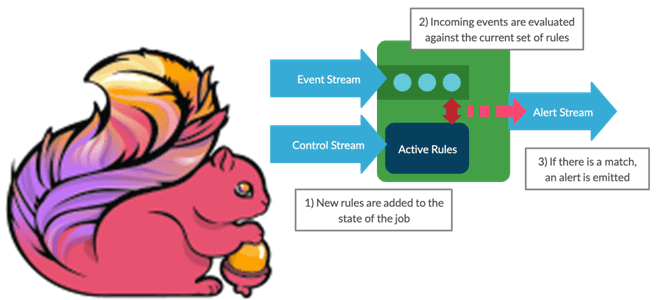
Мы уже писали про динамическое изменение правил фильтрации без перезапуска Flink-приложений. В продолжение этой темы в рамках продвижения нашего нового курса по потоковой обработке данных помощью Apache Flink, сегодня рассмотрим, как избежать неравномерного распределения данных во время выполнения программы. Больше 3-х не собираться: бизнес-правила и динамика разделения данных Перекос или...