
Каждый разработчик и дата-аналитик с закрытыми глазами напишет SQL-запрос с регулярными выражениями для поиска данных по шаблону в реляционной базе. А вот в NoSQL-СУБД такая простая задача реализуется довольно сложно. Как написать регулярное выражение в Apache HBase и запустить его на исполнение в CLI-интерфейсе shell-оболочки этого хранилища данных. Что такое...
Сбалансированная изоляция данных в мультиарендном кластере Apache HBase: опыт Flipkart

Для практического обучения дата-инженеров и архитекторов Big Data систем сегодня рассмотрим трудности изоляции и распределения в кластере Apache HBase и способы их обхода. С какими проблемами изоляции и сбалансированного распространения данных столкнулись инженеры индийской e-commerce компании Flipkart при организации мультиарендного кластера Apache HBase и как их решили. Изоляция данных и...
Миграция с Apache HBase в TiDB: кейс Pinterest

Хотя Apache HBase обладает массой достоинств, такими как строгая согласованность на уровне строк при больших объемах запросов, гибкая схема, доступ к данным с малой задержкой и интеграция с Hadoop, эта NoSQL-СУБД имеет ряд недостатков: чрезмерная сложность и дороговизна эксплуатации, отсутствие вторичных индексов и ACID-транзакций. Поэтому инженеры фотохостинга Pinterest приняли решение...
Большая проблема маленьких файлов в Apache Hadoop HDFS

Мы уже писали, что технологии Big Data ориентированы на работу с большими данными, а не множеством маленьких. Сегодня рассмотрим подробнее, почему Apache Hadoop, Spark и основанные на HDFS NoSQL-СУБД Hive и HBase плохо работают с большим количеством маленьких файлов, а также как это исправить. Почему HDFS плохо работает со множеством...
Отказоустойчивое распределение данных в Apache HBase

Сегодня рассмотрим компоненты и механизмы обеспечения отказоустойчивости Apache HBase. Что делать, когда региональный сервер выходит из строя и как процедура ServerCrashProcedure перераспределяет регионы данных на другие рабочие сервера в кластере Apache HBase. А также разберем, какие параметры конфигурации следует настроить администратору кластера для наиболее эффективного выполнения процессов записи и восстановления...
Как реализуются ACID-свойства транзакций в Apache HBase
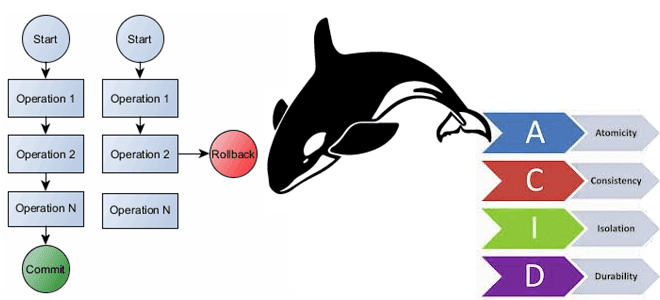
В этой статье для обучения архитекторов, дата-инженеров и аналитиков данных рассмотрим, как поддерживаются транзакции в Apache HBase и почему к ACID-свойствам также добавляется характеристика видимости обновлений. Насколько атомарны и консистентны мутации данных внутри строки HBase, почему сканирование не полностью согласовано и как разрешить устаревшие чтения или путешествия во времени в...
10 лучших практик для повышения эффективности Apache HBase
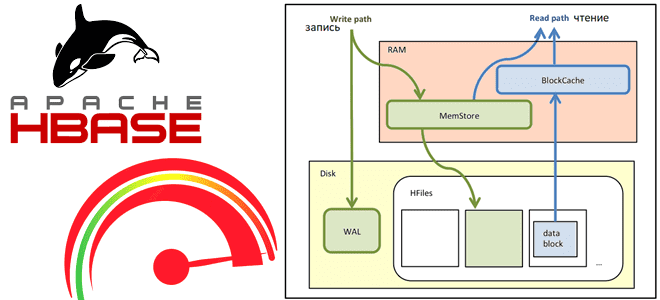
Сегодня рассмотрим, как выполняются операции чтения и записи в Apache HBase, а также с помощью каких приемов можно их ускорить. Как рассчитать оптимальное количество регионов в таблице, зачем отключать версионирование, почему размер ключа строки должен быть небольшим и еще 7 полезных лайфхаков для администратора HBase-кластера. Оптимизация записи данных в Apache...
Детективная история про SCR-конфигурации HDFS в региональных серверах Apache HBase

В этой статье для обучения дата-инженеров и администраторов кластера Apache HBase разберем, почему региональные сервера могут работать некорректно при высокой нагрузке и при чем здесь SCR-конфигурация файловой системы Hadoop. Что такое Short-Circuit Read в HDFS и почему оно может снижать скорость потокового чтения в приложениях Spark Streaming. Постановка задачи: проблема...
Как повысить эффективность кластера Apache HBase: YCSB-тестирование региональных серверов
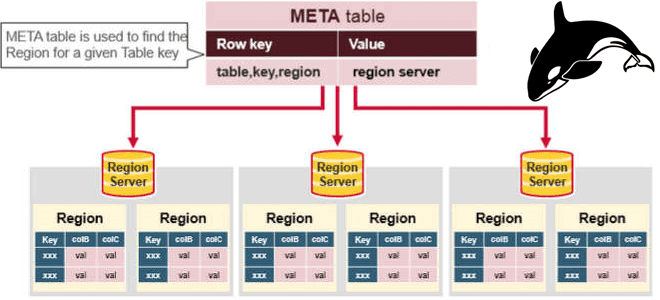
Сегодня затронем тему администрирования кластеров Apache HBase и рассмотрим, приносит ли реальную пользу совместное размещение нескольких региональных серверов (RegionServer) на одном узле кластера. Сравнительный анализ по тестам YCSB-бенчмарка. Регионы и сервера Apache HBase Напомним, Apache HBase является популярной колоночной NoSQL-СУБД, которая работает поверх распределенной файловой системы HDFS и обеспечивает возможности...
Обнаружение мошенничества при скимминге банковских карт c Apache Kafka, Flink и HBase

Пример выявления финансового мошенничества при скимминге банковских карт в банкоматах с помощью технологий Big Data. Как Apache Kafka, Flink и HBase помогут обнаружить злоумышленников в режиме реального времени. Что такое скимминг, как это работает и чем опасно Скимминг является одним из частых видов мошенничества с банковскими картами, представляющий собой считывание...