
Хотя Apache Pig сегодня не самый актуальный инструмент для аналитики больших данных в экосистеме Hadoop, дата-инженеру полезно знать его основные принципы работы и ключевые отличия от Hive. Также рассмотрим, чем Hive отличается от Pig в качестве средства SQL-on-Hadoop. Что такое Apache Pig Apache Pig – это высокоуровневый процедурный язык для...
Зачем вам WebHCat – REST API к HCatalog в Apache Hive
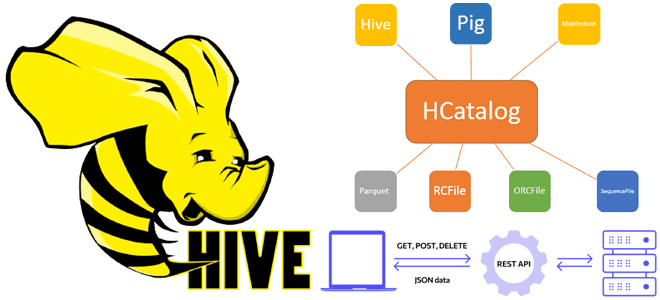
Сегодня рассмотрим, что такое WebHCat в Apache Hive и как этот REST API позволяет взаимодействовать с HCatalog, используя стандартные HTTP-методы. Еще разберем, какие DDL-команды Hive и HiveQL не поддерживает HCatalog, а также что полезного может быть в лог-файлах Templeton. Принципы работы компонента WebHCat как REST-сервиса Apache Hive Будучи NoSQL-хранилищем класса...
Apache Hive 4.0.0-alpha-2: что нового?

16 ноября 2022 года вышел 2-ой альфа-релиз Apache Hive 4.0.0. Какие ошибки в нем исправлены и что за новые функции, важные для дата-инженера и администратора кластера Hadoop, появились. А перед этим вспомним основные принципы работы Apache Hive. Принципы работы Apache Hive Apache Hive является популярным инструментом стека SQL-on-Hadoop, позволяя обращаться...
Как запустить службу внешнего хранилища метаданных Apache Hive в AWS EKS

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...
Как перейти от Apache Hive к Iceberg: стратегии миграции данных

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...
Блеск и нищета каталогов метаданных для Data Lake: преимущества Apache Iceberg над Hive

Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...
ETL-конвейер передачи данных из MySQL в Hive с Apache NiFi

Сегодня разберем, как автоматизировать наполнение озера данных на HDFS через загрузку таблиц из реляционной базы MySQL в Hive с помощью Apache NiFi. Какие процессоры NiFi следует использовать и зачем предварительно разделять таблицу Apache Hive. Пример ETL-конвейера на процессорах Apache NiFi Apache NiFi часто используется дата-инженерами в качестве средства автоматизации и...
От Apache Hive к Iceberg и Spark: модернизация озера данных в Airbnb
Рассмотрим, как дата-инженеры Airbnb делятся своим опытом перевода корпоративного Data Lake на Apache HDFS в облачное объектное хранилище AWS S3. Почему пришлось переводить аналитические нагрузки с Apache Hive на Iceberg и Spark, и какие результаты это принесло. Предыстория: Data Lake на HDFS и Apache Hive Будучи крупнейшей онлайн-площадкой для размещения...
Абсолютно безопасно: 3 security-кита в Apache Hive

В этой статье для обучения дата-инженеров и администраторов SQL-on-Hadoop рассмотрим способы обеспечения информационной безопасности и защиты данных от несанкционированного доступа в Apache Hive. Классический security-набор: аутентификация, авторизация и шифрование. Авторизация и аутентификация в Apache Hive Будучи популярным инструментом стека SQL-on-Hadoop, Apache Hive поддерживает все механизмы обеспечения информационной безопасности, поддерживаемый базовой...
Быстрая индексация данных в HDFS, Hadoop и Spark с библиотекой Dione от PayPal
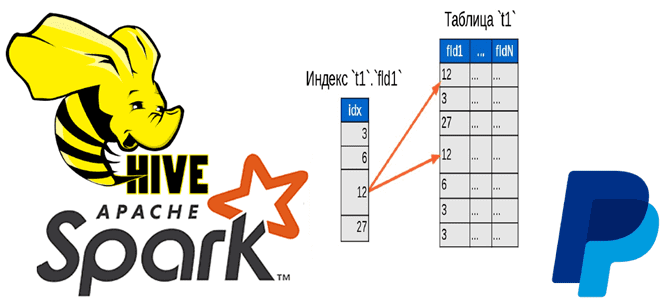
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...