
Мы уже писали, что технологии Big Data ориентированы на работу с большими данными, а не множеством маленьких. Сегодня рассмотрим подробнее, почему Apache Hadoop, Spark и основанные на HDFS NoSQL-СУБД Hive и HBase плохо работают с большим количеством маленьких файлов, а также как это исправить. Почему HDFS плохо работает со множеством...
Материализованные представления в Apache Hive

В рамках обучения аналитиков данных, дата-инженеров и разработчиков распределенных приложений, сегодня поговорим про материализованные представления в Apache Hive. Что это такое, зачем нужно и как реализуется в самом популярном NoSQL-хранилище стека SQL-on-Hadoop. Что такое материализованное представление и зачем это надо в аналитике больших данных: краткий ликбез Аналитика данных включает в...
Сериализация данных в Apache Hive
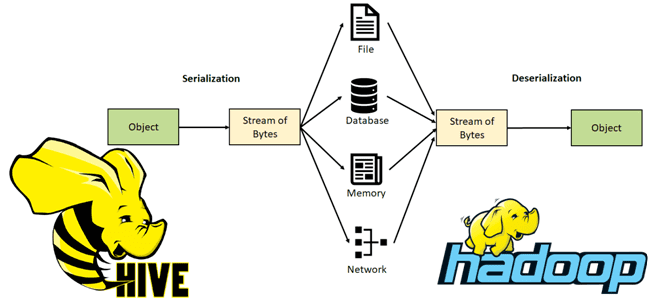
Чтобы добавить еще больше практики в наши курсы для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим тонкости сериализации данных в Apache Hive. Читайте далее, как этот популярный SQL-on-Hadoop инструмент обрабатывает данные из HDFS, что такое SerDe и как написать собственный сериализатор/десериализатор. Сериализация и десериализация данных в Apache Hive В настоящее...
Как LLAP ускоряет выполнение SQL-запросов в Apache Hive

В этой статье для обучения дата-инженеров и аналитиков данных заглянем под капот Apache Hive, чтобы разобраться с механизмов LLAP. Как этот движок повышает производительность популярного SQL-on-Hadoop инструмента, поддерживая длительные процессы на одних и тех же ресурсах для кэширования и аналитической обработки больших данных. Что такое LLAP в Apache Hive и...
5 лайфхаков по Apache Hive для инженера данных и специалиста по Data Science

Сегодня рассмотрим несколько полезных приемов по работе с Apache Hive, которые пригодятся инженеру данных и специалисту по Data Science в проектах аналитики больших данных. Как разделить и сегментировать таблицы, зачем изменять значение конфигурации памяти этапов MapReduce, чем полезна автоматическая обработка асимметрии данных и еще пара лайфхаков для ускорения выполнения SQL-запросов...
Apache Hive 3.1.3: обзор обновлений от 8 апреля 2022

В апреле 2022 года вышел очередной минорный релиз Apache Hive, который работает с Hadoop версии 3. Рассмотрим основные улучшения и исправленные ошибки этого обновления, которые пригодятся дата-инженеру и разработчику распределенных приложений аналитики больших данных. Исправленные ошибки В апрельском выпуске популярного NoSQL-хранилища Apache Hive, которое реализует возможность обращения к данным в...
7 приемов оптимизации SQL-запросов в Apache Hive с движком Tez

Для обучения дата-инженеров и аналитиков данных, сегодня рассмотрим приемы оптимизации SQL-запросов в Apache Hive, выполняемых движком Tez. Каким образом Tez рассчитывает оптимальное количество редукторов, зачем включать индексацию фильтров, как статистика таблицы помогает улучшить план выполнения запросов и что за конфигурации нужно менять. 3 движка выполнения запросов в Apache Hive Напомним,...
Тонкости Map Join в Apache Hive
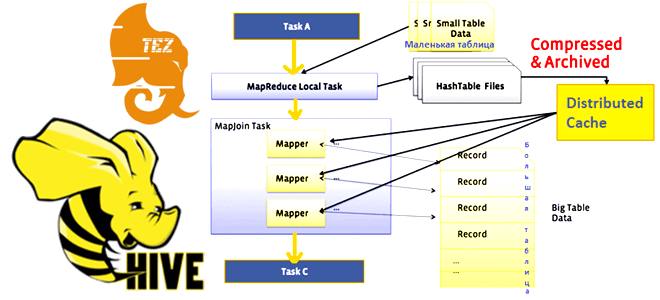
В этой статье для обучения дата-инженеров, аналитиков данных и разработчиков распределенных приложений рассмотрим один из методов оптимизации SQL-запросов в Apache Hive. Что такое оператор MapJoin, в каких условиях и как он работает, чем выгоден для HiveQL-запросов и почему при его выполнении с движком Tez может возникнуть нехватка памяти. Что такое...
Как связать Apache Kafka с Hive: разбор интеграционного коннектора

Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger. Зачем нужна интеграция Apache Hive с Kafka Необходимость связать Apache Hive с Kafka...
Интеграция Apache NiFi и Hive в ETL-конвейере
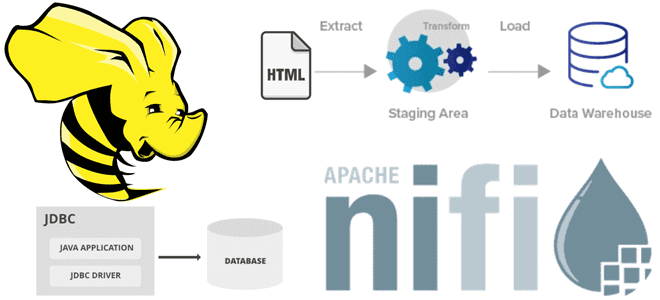
В этой статье для дата-инженеров рассмотрим пример интеграции Apache NiFi c Hive в рамках ETL-конвейера потокового веб-скрейпинга, который будет получать данные с веб-страницы практически без кода, обрабатывать их и загружать в таблицу NoSQL-СУБД в реальном времени. Постановка задачи: ETL-процесс веб-скрейпинга В реальной жизни задача считать данные с веб-сайта для последующей...