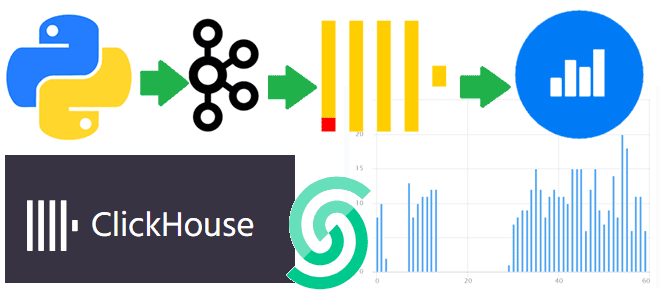
Как связать ClickHouse с Apache Kafka: примеры проектирования и реализации онлайн-аналитики с использованием облачного сервиса колоночной СУБД, брокера сообщений и BI-системы Яндекса. Постановка задачи и проектирование потокового конвейера Для взаимодействия с внешними хранилищами ClickHouse использует специальные механизмы – интеграционные движки таблиц. Вчера я показывала пример интеграции ClickHouse со встроенной key-value...
Новинки Apache Kafka 3.7: обзор свежего релиза

В конце февраля вышел очередной релиз Apache Kafka за номером 3.7. Поддержка JBOD в KRaft-кластерах, новый протокол перебалансировки потребителей, мониторинг метрик клиента на брокере, новинки Streams и Connect, и другие изменения самой популярной платформы потоковой передачи событий для дата-инженера и администратора. Изменения в брокерах, продюсера, контроллерах и Admin Client 27...
Разделять ли топик Apache Kafka: 5 главных соображений
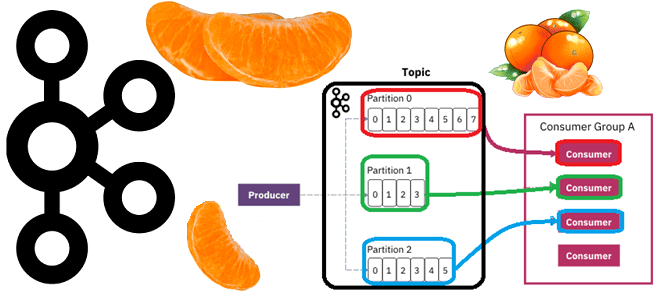
Почему раздел называется единицей параллелизма и как определить оптимальное число разделов в топике Apache Kafka в зависимости от количества потребителей и вариативности их поведения, разницы пропускной способности публикации и потребления сообщений, семантики партиционирования, толерантности к упорядоченности событий и ресурсных возможностей узла кластера. Что учитывать при разделении топика Apache Kafka Хотя...
Плавное завершение работы брокера Apache Kafka и перевыборы лидера

Что такое graceful shutdown в Apache Kafka, когда используется такое плавное завершение работы, при чем здесь синхронизация реплик и как это влияет на плановые операции обслуживания кластера. Как работает механизм Graceful shutdown в Apache Kafka Благодаря множеству внутренних механизмов обеспечения отказоустойчивости, Apache Kafka имеет высокую надежность и позволяет строить нагруженные...
Из Apache Kafka в Elasticsearch: реализуем sink-коннектор и строим дашборд в Kibana
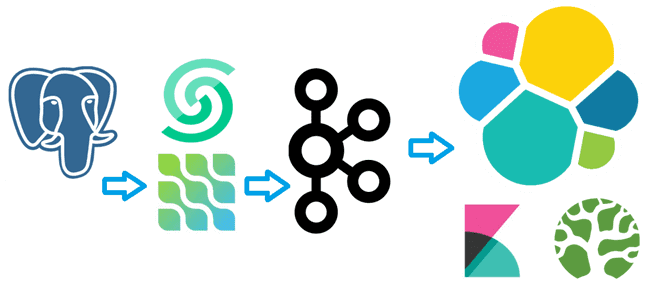
Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven. Постановка задачи и проектирование конвейера Как обычно, в...
Как использовать реестр схем Kafka Confluent: пример Python-продюсера
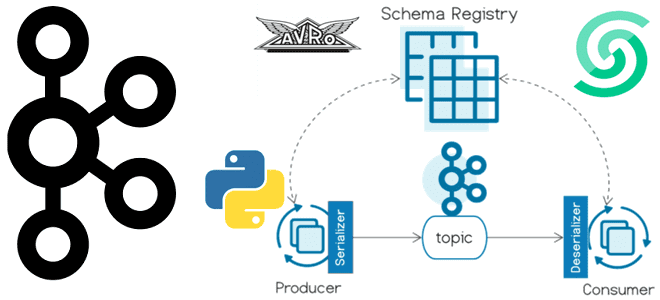
Сегодня я покажу пример использования реестра схем для Apache Kafka на платформе Upstash, API которого полностью совместим со Schema Registry от Confluent. Пишем продюсер на Python, используя библиотеку confluent_kafka. Еще раз о том, что такое реестр схем Kafka и чем он полезен Реестр схем (Schema Registry) – это модуль Confluent...
4 модели потоковой парадигмы обработки данных
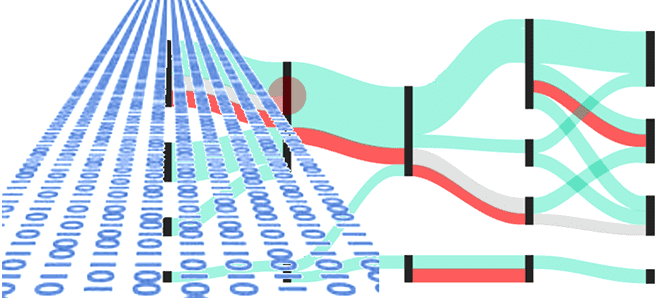
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink. Еще раз о разнице потоковой и пакетной парадигмы обработки данных Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных....
Обратное давление в потоковой передаче событий
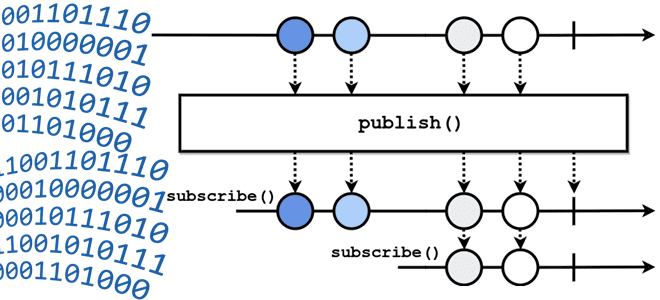
Что означает термин backpressure и зачем создавать обратное давление в streaming-системах: разбираемся с методами управления пропускной способностью потоковой передачи событий на примере Apache Kafka, Flink, Spark и NiFi. Что такое обратное давление: backpressure в конвейерах потоковой обработки данных Понять, как работает сложная концепция, проще всего на простых примерах. Это общее...
4 стратегии мультирегионального развертывания Apache Kafka
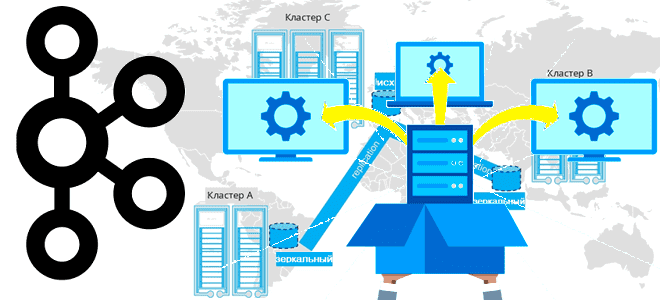
Завершая цикл статей про мультирегиональную репликацию кластеров Apache Kafka, сегодня поговорим про стратегии развертывания топологий, предлагаемых компанией Confluent. Принципы архитектуры, сравнение, сценарии, критерии выбора. Критерии выбора топологии репликации кластера Apache Kafka Для повышения надежности и производительность потоковой обработки данных с использованием Apache Kafka кластера этой платформы рекомендуется располагать в разных...
Реализация CDC из PostgreSQL в Apache Kafka с коннектором Debezium
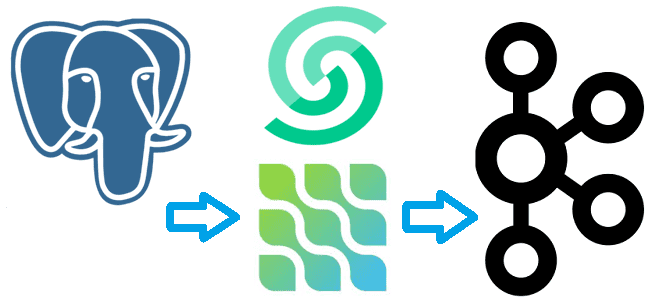
Сегодня я покажу на практическом примере, как реализовать потоковый захват изменения данных из таблицы PostgreSQL и их репликацию в Apache Kafka с помощью Debezium. Создаем и настраиваем свой коннектор на платформе Upstash. Постановка задачи Паттерн захвата измененных данных (CDC, Change Data Capture) является одним из самых распространенных в инженерии данных....