
Вчера мы говорили про важные обновления Apache Kafka 2.8.0, помимо долгожданного KIP-500, который позволяет избавиться от Zookeeper для синхронизации метаданных в распределенном кластере с помощью встроенного Quorum Controller. Сегодня рассмотрим, какие KIP’ы нового релиза коснулись одного из основных инструментов разработчика Apache Kafka – библиотеки Streams для создания распределенных приложений потоковой...
Не только KIP-500: 15 важных улучшений Apache Kafka 2.8.0

KIP-500, который позволяет наконец-то избавиться от Zookeeper в кластере Apache Kafka, заменив его Quorum Controller – далеко не единственное важное обновление в релизе 2.8.0. Сегодня рассмотрим, какие еще улучшения реализованы в новой версии главной Big Data платформы потоковой обработки событий, выпущенной в апреле 2021 года. Apache Kafka 2.8.0: новинки главных...
Проблема межкластерных транзакций в Apache Kafka и способы ее решения
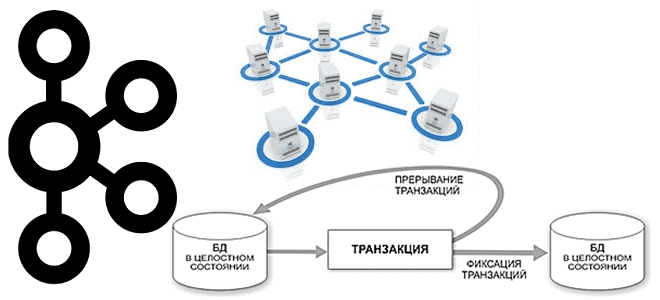
Продолжая говорить про обучение разработчиков и администраторов Apache Kafka, сегодня разберем сложности семантики строго однократной доставки сообщений (exactly once) в случае нескольких экземплярах, находящихся в разных кластерах. Читайте далее, что не так с межкластерными транзакциями, какие KIP’ы связаны с этой проблемой и при чем здесь MirrorMaker. Что не так с...
Оптимизация хранения сообщений в топиках Apache Kafka: зачем и как упаковывать, сжимать и менять форматы
Сегодня рассмотрим важную тему из курсов для разработчиков и администраторов Apache Kafka: как сэкономить место на диске и увеличить пропускную способность всей Big Data системы на базе этой платформы потоковой обработки событий. Читайте далее, зачем добавлять задержку перед отправкой сообщений брокеру, как кодеки сжатия помогут снизить затраты на облачный Kafka-кластер...
Apache Kafka теперь без Zookeeper — новый релиз
Свершилось. 19 апреля вышел долгожданный релиз Apache Kafka за номером 2.8.0 в котором вы наконец можете начать избавляться от использования Apache Zookeeper кластера ( см. подробности в KIP-500 и нашей статье от 30 января Зачем Apache Kafka и другие Big Data системы используют Zookeeper и чем его заменить ) Приглашаем...
Зачем вам cURL или как быстро загрузить ответ REST API или HTTP-запроса в Apache Kafka

Дополняя наши курсы по Apache Kafka практическими примерами, сегодня рассмотрим, как загрузить в топик данные из ответа REST API или HTTP-запроса. Читайте далее, что такое cURL и какие команды нужно отправить через эту утилиту, чтобы записать в Kafka сообщения из JSON-файла. REST API, HTTP и сURL Импорт данных из REST...
От пакетов к потокам с Kafka и Flink: аналитика больших данных по пользовательским сеансам в Spotify

Сегодня рассмотрим преимущества потоковой обработки данных с Apache Kafka и Flink над пакетными Big Data технологиями в виде Hadoop, Spark и Oozie. В качестве примера разберем реальный кейс аналитики больших данных по пользовательским сеансам в музыкальном онлайн-сервисе Spotify, а также возможность замены Apache Flink на Spark Structured Streaming. От рекламы...
Можно ли заменить Apache Kafka базой данных и почему не стоит даже пытаться
Однажды мы уже разбирали, способна ли Apache Kafka заменить собой базы данных в мире Big Data. Сегодня рассмотрим обратную постановку этой задачи: можно ли реализовать постоянный обмен сообщениями в стиле Kafka с помощью СУБД. Читайте далее, что общего у Kafka с базой данных, чем они отличаются и почему попытки заменить...
Как повысить отказоустойчивость продюсера Kafka: 5 практик по настройке ТОП-10 конфигураций

В этой статье поговорим про практическое обучение Apache Kafka и рассмотрим, как сделать продюсеров еще более отказоустойчивыми, чтобы улучшить общую надежность всей Big Data системы. Читайте далее про наиболее важные конфигурации продюсеров Kafka и эффективные рекомендации по их настройке. 10 самых важных параметров продюсера Apache Kafka Из множества конфигурационных параметров...
ОЗУ, Kafka и Logstash для решения IOPS-проблемы в кластере Apache NiFi

В рамках обучения дата-инженеров, сегодня рассмотрим проблему роста числа операций ввода-вывода в секунду (IOPS) при обработке большого количества данных в потоках Apache NiFi и способы ее решения. Читайте далее, как перемещение репозиториев NiFi с жесткого диска в оперативную память снижает IOPS, а также зачем при этом в Big Data систему...