В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
10 вопросов на знание основ Big Data: открытый интерактивный тест для начинающих

Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...
Потоковая обработка событий в Machine Learning и Big Data: основы StreamSQL для начинающих
Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено,...
Зачем вам Feature Store или что не так с микросервисами в ML-системах
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...
5 советов по потоковой аналитике больших данных с Apache Kafka и Spark Streaming

В продолжение вчерашнего материала про потоковую аналитику больших данных с Apache Kafka и Spark, сегодня рассмотрим особенности совместного использования этих технологий Big Data. В этой статье мы собрали для вас 5 лучших практик эффективного применения Apache Kafka и Spark Streaming для разработки распределенных приложений аналитики больших данных в режиме реального...
Как построить ML-pipeline на Qlik Replicate, Apache Kafka и других технологиях Big Data: архитектура real-time аналитики больших данных

Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий...
Apache Kafka и прочая Big Data для железнодорожников: кейс Deutsche Bahn

Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka,...
Что такое GraphQL и как это использовать в разработке приложений Apache Kafka
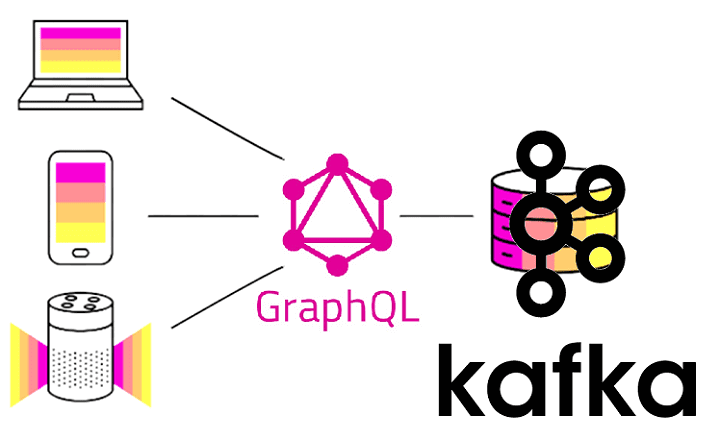
В рамках продвижения нашего нового курса Apache Kafka для разработчиков недавно мы рассматривали RESTful API к этой Big Data платформе потоковой обработки событий на примере Confluent REST Proxy. Сегодня разберем альтернативу REST-интерфейсам в виде GraphQL и применимости этой технологии к разработке распределенных Kafka-приложений. Что такое GraphQL и чем он лучше...
Чем хорош REST Proxy для Apache Kafka и что с ним не так: ключевые достоинства и недостатки RESTful API от Confluent
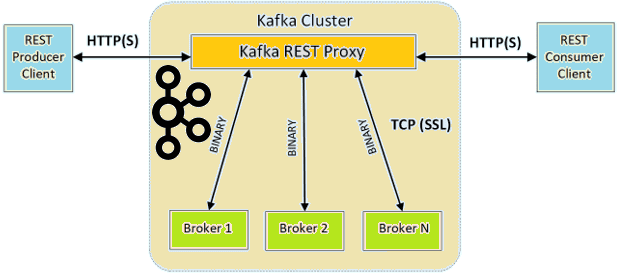
Продолжая разбираться с Confluent REST Proxy для Apache Kafka, сегодня рассмотрим основные достоинства и недостатки этого RESTful API. Читайте далее, что Confluent REST Proxy позволяет делать с Apache Kafka и что ограничивает его взаимодействие с самой популярной Big Data платформой потоковой обработки событий. 6 главных преимуществ RESTful API к...
Что такое REST Proxy к Apache Kafka: разбираемся с RESTful API от Confluent
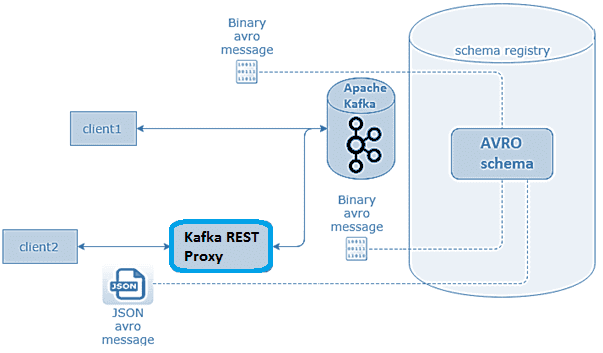
В этой статье разберем, что такое Confluent REST Proxy для Apache Kafka, как работает этот RESTful API, каким образом он связан с облачным сервисом этой популярной Big Data платформой потоковой обработки событий, а также при чем здесь Schema Registry. Основы Confluent REST Proxy для Apache Kafka Широко известная в области...