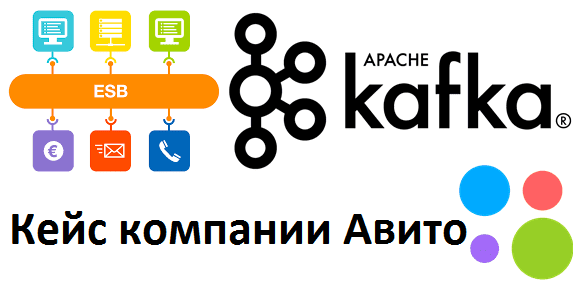
Есть мнение, что использование Apache Kafka в качестве корпоративной сервисной шины (ESB, Enterprise Service Bus) является антипаттерном. Сегодня мы проясним это категоричное утверждение и рассмотрим, как корректно реализовать ESB с помощью Kafka на практическом примере шины данных в компании Avito.ru. Что такое ESB и чем это отличается от брокера сообщений...
Комбо потоковой обработки Big Data с Apache Kafka и NiFi: пара практических примеров
Сегодня рассмотрим примеры совместного использования двух популярных технологий потоковой обработки больших данных (Big Data): Apache Kafka и NiFi. Читайте в нашей статье, как они дополняют друг друга, каковы преимущества их объединения и каким образом инженеру Data Flow это реализовать на практике. Еще раз о том, что такое Apache Kafka и...
3 проблемы администрирования Apache Kafka и пути их решения на практических примерах

Администрирование кластера Kafka порой напоминает работу детектива, когда нужно понять мотив преступления причину появления того или иного бага и устранить ее вместе с последствиями наиболее оптимальным способом. В этой статье мы рассмотрим несколько практических примеров конфигурирования Apache Kafka из опыта компании Booking.com, кейс которой был представлен в докладе ее сотрудника...
Как сэкономить место на диске, управляя временем: проблемы администрирования Apache Kafka на примере Booking.com

В продолжении серии статей по докладу Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech, сегодня мы рассмотрим некоторые проблемы администрирования Apache Kafka, с которыми можно столкнуться на практике. Читайте в этом материале, как не допустить разрастание топика, правильно задав параметр CreateTime. Что делать,...
Борьба со сложностью ACL-настроек в Apache Kafka или self-service авторизации в Booking.com

Аутентификация – далеко не единственная возможность обеспечения информационной безопасности в Apache Kafka. Сегодня мы продолжим разговор про Big Data cybersecurity и рассмотрим особенности авторизации в Apache Kafka в формате самообслуживания (self-service), как это было сделано в travel-компании Booking.com. В качестве примера продолжим разбирать доклад Александра Миронова, который был представлен 23...
Особенности самообслуживаемой аутентификации Apache Kafka на примере Booking.com

Продолжая разбирать доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech, сегодня мы рассмотрим, с какими проблемами столкнулись администраторы Big Data при обеспечении информационной безопасности своих Кафка-кластеров. Читайте в нашей статье про возможные методы аутентификации в Apache Kafka и их практическое использование в...
45+ кластеров и 2 DevOps-лайфхака по администрированию Apache Kafka от Booking.com

Сегодня мы разберем доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech [1]. Читайте в нашей статье, как одна из ведущих travel-компаний использует Apache Kafka, с какими проблемами столкнулись администраторы ее Big Data инфраструктуры и DevOps-инженеры, а также почему были выбраны именно такие...
Как найти товарные остатки с помощью Big Data и Machine Learning: пример Леруа Мерлен

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...
Как организовать конвейер self-service Machine Learning на Apache Kafka, Spark Streaming, Kudu и Impala: пример расширенной BI-аналитики Big Data
Продолжая разбирать production-кейсы реального использования этих технологий Big Data, сегодня поговорим подробнее, каковы плюсы совместного применения Kudu, Spark Streaming, Kafka и Cloudera Impala на примере аналитической платформы для мониторинга событий информационной безопасности банка «Открытие». Также читайте в нашей статье про возможности этих технологий в контексте машинного обучения (Machine Learning), в...
Как сократить цикл BI-аналитики Big Data в тысячи раз или ETL-конвейер Apache Kafka-Storm-Kudu-Impala в Xiaomi

Сегодня мы рассмотрим практический кейс использования Apache Kudu с Kafka, Storm и Cloudera Impala в крупной китайской корпорации, которая производит смартфоны. На базе этих Big Data технологий компания Xiaomi построила собственную платформу для BI-аналитики больших данных и генерации отчетности в реальном времени. История Kudu-проекта в Xiaomi Корпорация Xiaomi начала использовать...