
Мы уже рассказывали про интеграцию Tarantool с Apache Kafka на примере Arenadata Grid. Сегодня рассмотрим, как интегрировать Кафка с MPP-СУБД Greenplum и каковы ограничения каждого из существующих способов. Читайте в сегодняшнем материале, что такое GPSS, PXF и при чем тут Docker-контейнер с коннектором Кафка для Arenadata DB. IoT и не...
Интеграция Big Data или как связать Tarantool c Apache Kafka на примере Arenadata Grid
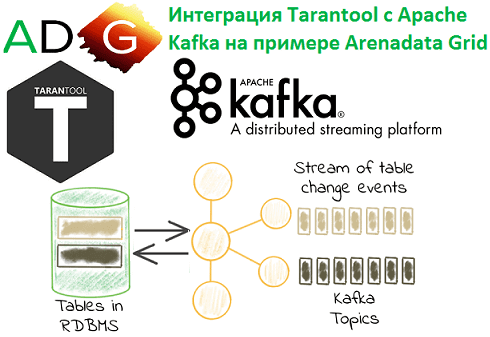
Продолжая разбираться с In-Memory СУБД Tarantool и Arenadata Grid, сегодня рассмотрим, как эти резидентные базы данных интегрируются с Apache Kafka. Читайте в нашей статье, что такое коннекторы и процессоры, а также как записать в топик Кафка сообщение, SQL-запрос или часть таблицы. Arenadata Grid и Apache Kafka: коннектор + процессоры Напомним,...
Big Data, Machine Learning и Internet of Things в складской логистике: 7 FMCG-кейсов
Вчера мы затрагивали тему управления поставками в ритейле с помощью технологий Big Data и Machine Learning. Теперь разберем подробнее, как большие данные, машинное обучение и интернет вещей меняют складскую логистику и насколько это выгодно бизнесу. Сегодня мы собрали для вас 7 практических примеров: кейсы от отечественных и зарубежных транспортных компаний,...
Завод, телеком и госсектор: 3 примера внедрения Arenadata

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...
Data lineage и provenance: близнецы или двойняшки – Big Data Management для начинающих
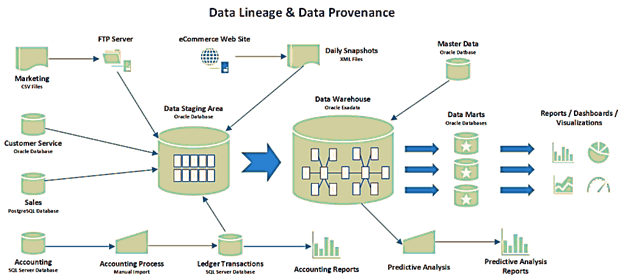
В этой статье мы продолжим разговор про основы управления данными и рассмотрим, что такое data provenance и data lineage, чем похожи и чем отличаются эти понятия. Также разберем, почему эти термины особенно важны для Big Data, какие инструменты помогают работать с ними, а также при чем здесь GDPR. Что такое...
Что такое Каппа-архитектура: альтернатива Лямбда для потоков Big Data
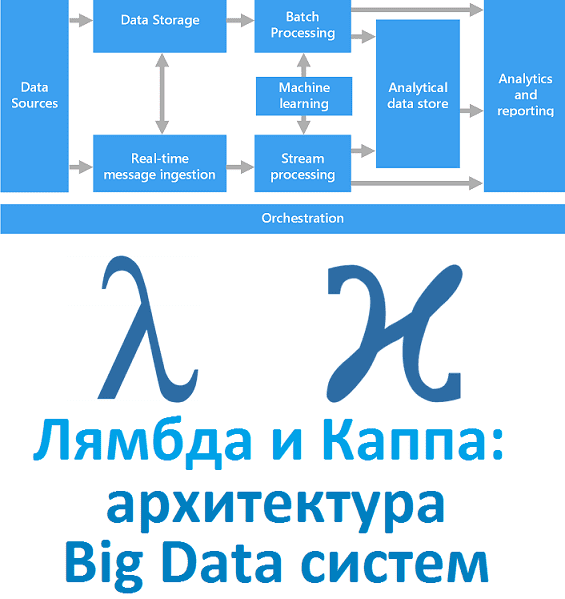
Вчера мы рассказали, что такое лямбда-архитектура. Сегодня рассмотрим Каппа - альтернативный подход к проектированию Big Data систем. Читайте в нашей статье, зачем нужна эта концепция, каковы ее достоинства и недостатки, чем Каппа отличается от Лямбда, где это используется на практике и при чем тут Apache Kafka с Machine Learning. Зачем...
7 принципов Lean в Big Data: бережливое производство больших данных
Не претендуя на лавры Мэри и Тома Поппендиков, которые впервые освятили применение Lean в разработке ПО, сегодня мы расскажем, как идеи бережливого производства реализуются в области Big Data. Читайте в нашей статье про принцип вытягивания в Apache Kafka, концепцию «точно вовремя» в Apache Spark, SMED в Kubernetes и облачных кластерах...
Как выбрать курсы по Spark: 4 ключевых аспекта, на что обратить внимание

Выбирая курсы по Spark, Hadoop, Kafka и другим технологиям больших данных, легко запутаться во многочисленных предложениях от различных учебных центров и платформах онлайн-обучения. Сегодня мы расскажем, что должна включать программа курса по Big Data, чтобы результат обучения оправдал ваши ожидания и даже превзошел их. 4 главных свойства эффективного курса по...
Как работает Apache Zookeeper: 5 проблем самой популярной службы синхронизации для распределенных Big Data систем

Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления...
Как Apache Kafka используется в реальном производстве: пример Северстали

Рассматривать обучение Кафка интереснее на практических примерах. Сегодня мы расскажем, как Apache Kafka применяется в одной из крупнейших промышленных компаний России - ПАО «Северсталь». Эта статья написана на основе выступления Доната Фетисова, главного архитектора «Северсталь Диджитал». Доклад был представлен 7 декабря 2019 года на очередном ИТ-митапе компании Авито по Big...