
Сегодня разберем, как из ClickHouse обратиться к встроенной key-value БД RockDB, используя табличный движок EmbeddedRocksDB, и познакомимся с возможностями новой песочницы колоночной базы данных. Постановка задачи и DDL-скрипты Колоночная СУБД ClickHouse поддерживает несколько движков таблиц, включая интеграционные механизмы для взаимодействия со сторонними системами, одной из которых является key-value база данных...
Новости и статьи по администрированию, аналитике, разработке и эксплуатации NOSQL технологий в Big Data: Apache HBase, Hive, Impala, Greenplum, ClickHouse и другие Not Only SQL СУБД для хранения и аналитической обработки больших данных.
3 среды выполнения запросов Cypher в графовой базе данных Neo4j: что выбрать?

Тонкости параллельной среды выполнения Cypher-запросов в NoSQL-СУБД Neo4j и критерии выбора runtime для аналитических и транзакционных сценариев работы с графами. Слотовая и конвейерная среды выполнения Вообще в графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. По умолчанию в версии в Community Edition используется слотовая, а...
Слотовая или конвейерная: сравнение сред выполнения Cypher-запросов в графовой базе данных Neo4j
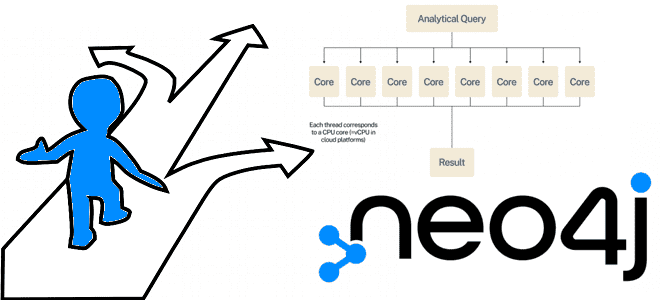
Чем слотовая среда выполнения Cypher-запросов в Neo4j отличается от конвейерной, как ее задать и что выбрать для транзакционных и аналитических сценариев работы с графами: наглядные примеры. Слотовая среда выполнения В графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. В большинстве случаев среды выполнения по умолчанию...
Оптимизация запросов Cypher к графовой базе данных Neo4j

Почему тормозит Cypher-запрос к Neo4j, как его отладить и чем оператор PROFILE отличается от EXPLAIN. Краткий ликбез с примерами выполнения запросов к графовой базе данных для аналитиков и разработчиков. Как выполняются Cypher-запросы в Neo4j Любой дата-аналитик и разработчик, работающий с базами данных, знает, что одной из самых частых причин медленного...
3 главных проблемы проектирования современной архитектуры данных

От оркестрации и синхронизации конвейеров обработки данных до управления хранилищами, включая хранение состояний для stateful-приложений: сложности проектирования архитектуры потоковой обработки событий и способы их решения. Основные сложности проектирования современной архитектуры данных Из-за принципиальных отличий потоковой парадигмы обработки данных от пакетной, что разбиралось здесь, задача проектирования дата-конвейеров сильно усложняется, т.к. редко...
Как создать дэшборд NeoDash для графовой базы данных Neo4j
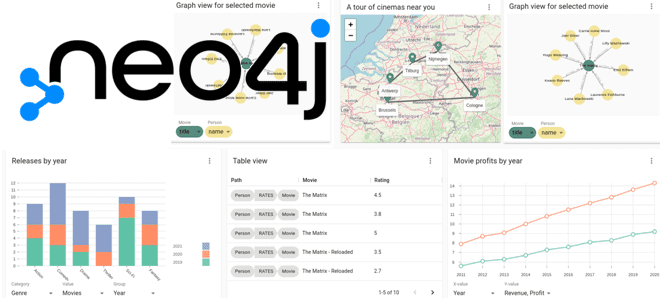
Создаем визуализации Cypher-запросов к своему графу в графовой базе данных Neo4j с помощью дэшборда NeoDash на примере анализа финансовых транзакций в банке. Python-генерация графа в Neo4j с фейковыми данными Поскольку NoSQL-СУБД Neo4j отлично подходит для задач графовой аналитики больших данных благодаря своей нативно графовой модели хранения данных, ее можно использовать...
Из Apache Kafka в Elasticsearch: реализуем sink-коннектор и строим дашборд в Kibana
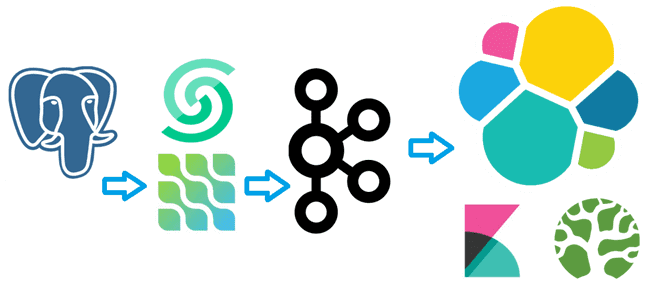
Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven. Постановка задачи и проектирование конвейера Как обычно, в...
Словари в ClickHouse

Что такое словарь в ClickHouse, какие бывают словари, как их создать и каким командами к ним обращаться. Пара примеров со словарями в самой популярной колоночной аналитической СУБД. Что такое словарь в ClickHouse Как колоночная база данных, ClickHouse предназначена для аналитической обработки огромных объемов данных в реальном времени. Аналитические сценарии предполагают...
Проектирование хранилища данных с методологией Data Vault в архитектуре Lakehouse
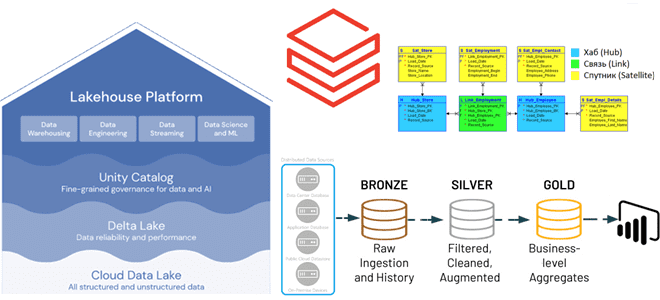
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...
Apache Kafka vs Streams и Pub/Sub в Redis
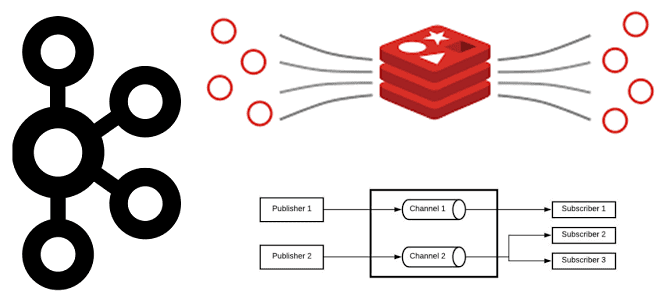
Как key-value СУБД Redis может работать с потоковыми данными и чем Pub/Sub и Streams отличаются от Apache Kafka. Сравнение и рекомендации по использованию. Потоковое сохранение данных Redis Будучи очень быстрым key-value хранилищем, NoSQL-СУБД Redis часто используется в качестве слоя кэширования для разгрузки основной базы данных. В отличие от многих других...