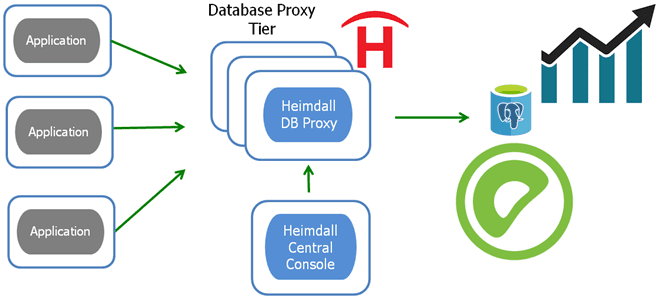
Сегодня рассмотрим, что такое Heimdall Database Proxy и как это пригодится администратору кластера Greenplum и разработчику распределенных приложений, взаимодействующих с этой MPP-СУБД. А также разберем, с какими проблемами администратор кластера может столкнуться при настройке совместного использования этих систем, и как их решить. Что такое Heimdall Database Proxy Хотя Greenplum работает...
Информационно-аналитические статьи и новости о технологиях анализа и хранения Больших Данных (Big Data), машинного обучения (Machine Learning), администрирования кластеров (Hadoop, Kafka, Spark, AirFlow), а также реальные истории и лучшие практики их прикладного использования в российских и зарубежных компаниях
Графовое машинное обучение: кейс Airbnb

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем, как Airbnb использует графовые нейросети для улучшения машинного обучения. А также рассмотрим, как устроены GCN-нейросети и что определяет выбор между потоковым и пакетным ML-конвейером. Анализ графов для обогащения ML-моделей Многие проблемы машинного обучения могут быть...
Проблема с ShellUserGroupProvider в Apache NiFi 1.16.3

Сегодня рассмотрим серьезную уязвимость CVE-2022-33140, связанную с авторизациями и обнаруженную в последнем выпуска Apache NiFi 1.16.3, о котором мы писали здесь. Почему проблема с ShellUserGroupProvider оказалась так значительна и что сделано для ее устранения. Уязвимость CVE-2022-33140 в Apache NiFi 1.16.3 В свежем релизе Apache NiFi 1.16.3, который вышел 15 июня...
Интеграционное тестирование DAG в Apache AirFlow
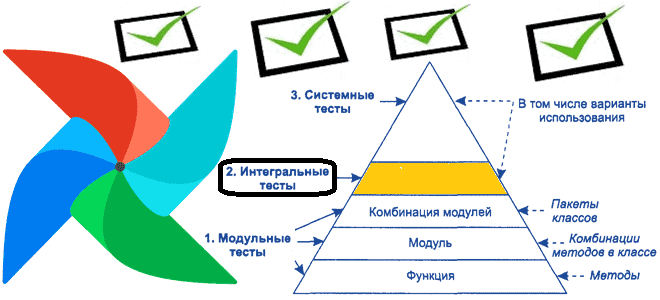
Продолжая тему тестирования DAG в Apache Airflow, сегодня рассмотрим следующий этап проверки качества ПО – разработку интеграционных тестов. Разберемся, как при этом дата-инженер может использовать Docker Compose и Pytest, а также познакомимся с возможностями REST API самого популярного в Big Data batch-оркестратора. Идеи и инструменты интеграционного тестирования DAG в Apache...
Экономия места в Apache Kafka с форматом Parquet

Недавно мы сравнивали разные форматы сериализации данных, поддерживаемые Apache Kafka. Однако, AVRO и JSON не могут похвастаться таким высоким коэффициентом сжатия, как колоночный бинарный формат Parquet. Читайте далее, как хранить больше потоковых данных на тех же ресурсах с помощью движка Deephaven и других open-source решений. Apache Kafka и Parquet Apache...
Под капотом Apache Spark: 3 секрета для дата-инженера и разработчика

Постоянно добавляя в наши курсы по Apache Spark полезные материалы, сегодня мы рассмотрим, что происходит под капотом этого вычислительного движка, чтобы помочь разработчикам распределенных приложений и дата-инженерам повысить его эффективность. Тонкости сериализации данных, компиляции SQL-запросов в JavaBytecode и сборка мусора. 2 библиотеки сериализации данных в Apache Spark В распределенных системах...
Познакомьтесь с ModelOps: новый расширенный MLOps для бизнеса
Пока инженеры данных и специалисты по Data Science привыкали к MLOps, начав понимать важность и необходимость этой концепции непрерывной разработки и эксплуатации систем машинного обучения, в Data Science появился новый термин с модным –Ops окончанием. Разбираемся, что такое ModelOps, чем это отличается от MLOps и как применить его на практике....
Как реализуются ACID-свойства транзакций в Apache HBase
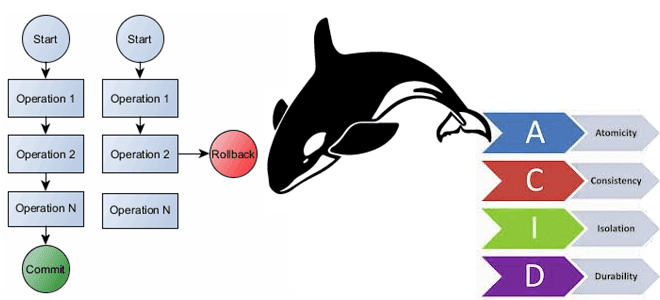
В этой статье для обучения архитекторов, дата-инженеров и аналитиков данных рассмотрим, как поддерживаются транзакции в Apache HBase и почему к ACID-свойствам также добавляется характеристика видимости обновлений. Насколько атомарны и консистентны мутации данных внутри строки HBase, почему сканирование не полностью согласовано и как разрешить устаревшие чтения или путешествия во времени в...
5 лайфхаков по Apache Hive для инженера данных и специалиста по Data Science

Сегодня рассмотрим несколько полезных приемов по работе с Apache Hive, которые пригодятся инженеру данных и специалисту по Data Science в проектах аналитики больших данных. Как разделить и сегментировать таблицы, зачем изменять значение конфигурации памяти этапов MapReduce, чем полезна автоматическая обработка асимметрии данных и еще пара лайфхаков для ускорения выполнения SQL-запросов...
Модульное тестирование условной логики DAG в Apache AirFlow
Мы уже писали про важность модульного тестирования DAG Apache Airflow, а также лучшие практики и инструменты реализации этого процесса. Как протестировать структуру DAG со сложной условной логикой, сделав тест детерминированным с помощью простой сортировки идентификаторов задач, а также каким образом дата-инженеру помогут шаблоны Jinja. Проверка структуры DAG в AirFlow С...