Мы уже рассматривали, как загрузить в Greenplum большие объемы данных. В продолжение этой важной для обучения дата-инженеров темы, сегодня разберем еще несколько инструментов, решающих задачу организации ETL-процессов с этой MPP-СУБД. ETL-инструменты PostgreSQL Хотя Greenplum может хранить и обрабатывать огромные наборы данных на уровне петабайт, эта СУБД не генерирует их самостоятельно,...
Информационно-аналитические статьи и новости о технологиях анализа и хранения Больших Данных (Big Data), машинного обучения (Machine Learning), администрирования кластеров (Hadoop, Kafka, Spark, AirFlow), а также реальные истории и лучшие практики их прикладного использования в российских и зарубежных компаниях
Apache Kafka в Walmart для масштабируемого пополнения запасов в реальном времени

Проблема своевременного пополнения товарных запасов актуальна для любого ритейлера. Разбираемся, как торговый гигант США Walmart построил свою платформу планирования и пополнения продукции в реальном времени на базе Apache Kafka: ключевые требования к системе, архитектура и принципы работы, настройка конфигураций продюсеров и потребителей. Постановка задачи: пополнение товарного запаса в реальном времени...
CI/CD для дата-инженера: разработка DAG и развертывание в среде Airflow с GitLab
Интеграция Apache Airflow с инструментами CI/CD является одной из лучших практик современной дата-инженерии, о чем мы недавно писали. Читайте далее, зачем нужно управлять кодом DAG с помощью популярных систем управления версиями и как это сделать на примере GitLab CI/CD. Сложности управления DAG в разных средах AirFlow Apache Airflow считается наиболее...
Feature Store на Apache HBase с Phoenix, RonDB и Kafka: кейс Dream11
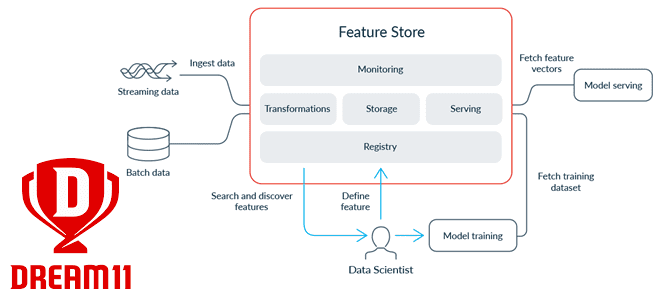
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka. Что такое хранилище фичей и зачем это Dream11...
DevOps + MLOps: мониторинг ML-моделей с New Relic
Зачем нужен мониторинг ML-систем в production, чем он отличается от простого отслеживания метрик ПО и при чем здесь MLOps. Как настроить телеметрию ML-приложений в New Relic: 5 простых шагов для специалистов по Machine Learning и дата-инженеров. Зачем нужен мониторинг ML-систем и при чем здесь MLOps В реальных системах машинного обучения...
Анализ европейской газотранспортной системы с Neo4j

В рамках практического обучения аналитиков данных и специалистов по Data Science реальным задачам современных бизнес-приложений, сегодня разберем актуальную и острую для многих стран тему по промышленному использованию природных ресурсов в современных непростых условиях. Строим граф европейской газотранспортной системы в Neo4j. Создание графа европейской газотранспортной системы в Neo4j Российский природный газ...
Бесплатный митап: «Spark или pandas? Spark и pandas!»

Школа Больших Данных продолжает серию митапов по Apache Spark. Третий митап состоится 24 мая в 17:00 МСК по теме «Spark или pandas? Spark и pandas!». Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов...
3 режима вывода в Apache Spark Structured Streaming
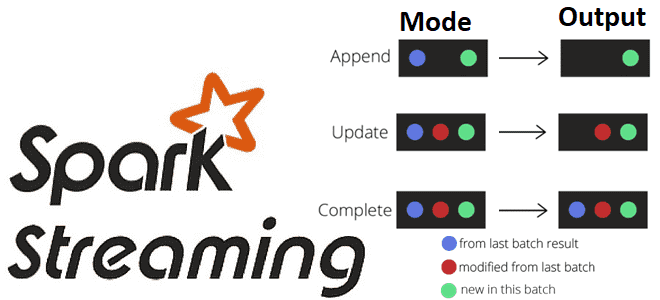
Какие бывают режимы вывода в структурированной потоковой передаче Spark, чем они отличаются и как их использовать на практике: разбираемся на практическом примере. Краткий ликбез по output modes в Apache Spark Structured Streaming для обучения дата-инженеров и разработчиков распределенных приложений. Что такое режимы вывода в Apache Spark Structured Streaming Apache Spark...
Интеграция Apache NiFi и Hive в ETL-конвейере
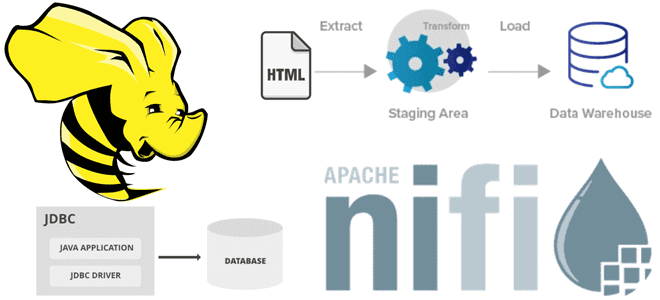
В этой статье для дата-инженеров рассмотрим пример интеграции Apache NiFi c Hive в рамках ETL-конвейера потокового веб-скрейпинга, который будет получать данные с веб-страницы практически без кода, обрабатывать их и загружать в таблицу NoSQL-СУБД в реальном времени. Постановка задачи: ETL-процесс веб-скрейпинга В реальной жизни задача считать данные с веб-сайта для последующей...
Как написать свой ExecuteScript-процессор Apache NiFi на TypeScript
Сегодня рассмотрим, что такое процессор ExecuteScript в Apache NiFi, как с его помощью реализовать собственную бизнес-логику обработки потоков данных на мульти-парадигмальном языке программирования TypeScript и чем это будет лучше кода на JavaScript. Краткий ликбез для дата-инженеров. Процессор ExecuteScript в Apache NiFi Напомним, за обработку потоков данных в Apache NiFi отвечают...