
Impala — это механизм запросов на языке SQL (Structured Query Language), в основе которого лежит массово-параллельная обработка данных (Massively Parallel Processing, MPP), предполагающая одновременное выполнение множества вычислений благодаря распараллеливанию вычислительных процессов.
Что такое Apache Impala: архитектура и принцип работы
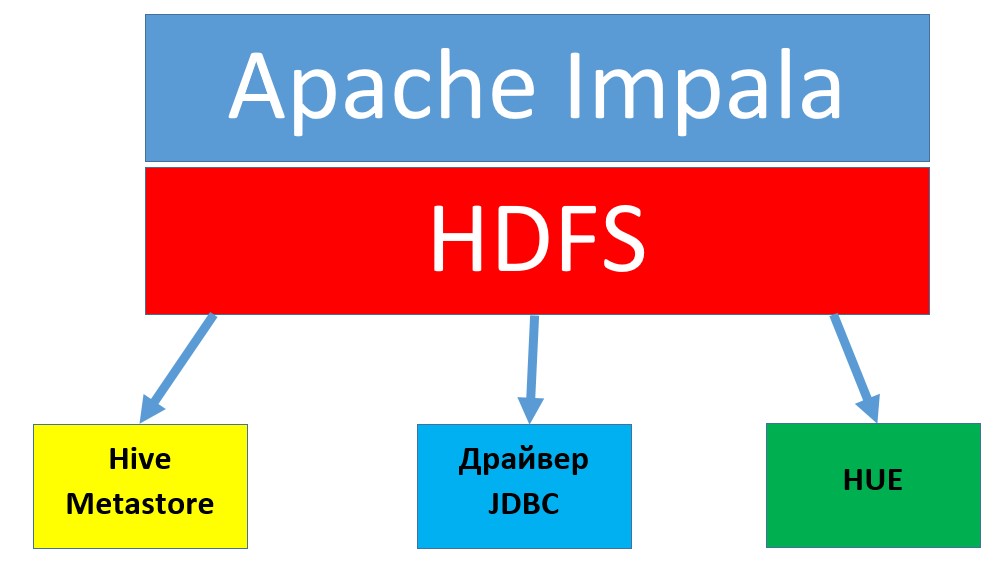
Apache Impala — это распределенный механизм запросов в распределенном кластере экосистемы Hadoop. Работая в распределенной среде, процессы Impala выполняются на различных узлах кластера, получая запросы от клиентов. В качестве клиентов выступают пользователи и приложения, отправляющие SQL-запросы к данным, которые также хранятся в распределенных хранилищах (например, HBase, HDFS, Amazon S3) экосистемы Hadoop. Архитектура Impala состоит из следующих элементов:
- Hive Metastore — это служба каталогов, которая отвечает за хранение информации о доступных базах данных, а также об их структуре. Таким образом, когда в базе данных происходят какие-либо изменения (создание, удаление или изменение данных), они сразу фиксируются на всех узлах кластера Hadoop.
- HUE (Hadoop User Experience) — это веб-интерфейс, предоставляющий пользователю редактор SQL-запросов (SQL Editor) для взаимодействия с Импала.
- JDBC-драйвер — это стандарт для взаимодействия Java-приложений с различными СУБД. Благодаря этому стандарту Импала легко интегрируется в любое приложение (использующее базы данных), содержащее Java-модули.
В состав Impala также входят следующие ключевые сервисы:
- Impalad (Impala daemon) — это системная служба, которая отвечает за планирование и выполнение запросов к распределенным данным. Процесс impalad запускается на каждом узле кластера в момент запуска Импала;
- Statestored — это служба, отвечающая за отслеживание статуса всех impalad-экземпляров в кластере. Один Stetestored-экземпляр запускается на всех узлах в кластере включая центральный узел (Name node).
- Catalogd — это служба координации метаданных, которая передает изменения от операторов Импала DDL (Data Definition Language) и DML (Data Manipulation Language), которые включают в себя операторы определения (
CREATE,ALTER) данных и манипулирования (INSERT,UPDATE,DELETE) данными. Это делается для того, чтобы после изменения новые таблицы (отношения) сразу отображались всем узлам кластера.
Запросы в Импала выполняются следующим образом:
- Клиентское приложение отправляет SQL-запрос, подключаясь к Impalad через драйвер JDBC. Так подключенный Impalad становится координатором текущего запроса
- Impalad выполняет анализ запроса и строит оптимальный план его выполнения, а также определяет задачи для impalad-экземпляров в кластере.
- Impalad получает доступ к распределенным данным через локальные экземпляры предоставления данных (например, Spinnaker в Amazon S3)
- Каждый процесс impalad возвращает данные координирующему daemon’у, который отправляет результаты запроса клиенту [1]
Как появилась Apache Impala: краткая история
Изначально Импала была разработана компанией Cloudera, и в октябре 2012 года было объявлено официальное бета-тестирование продукта. В начале 2013 года был анонсирован формат файлов под названием Parquet для архитектур (Hive, Pig), имеющих распределённую структуру, включая также Импала. Parquet подразумевал табличную структуру хранения данных (в виде строк и столбцов). В декабре 2013 года Amazon Web Services объявила о поддержке Импала. 28 апреля 2013 года Impala вышла в свет как самостоятельный общедоступный проект. В 2015 году Cloudera решает пожертвовать свой проект компании Apache Software Foundation. 28 ноября 2017 года Импала стала проектом верхнего уровня Apache. Последняя версия Импала (Impala 3.3.0) была выпущена 22 августа 2019 года [2].
Таким образом, благодаря вышерассмотренной единой системе для обработки Big Data, Импала имеет возможность обрабатывать распределенные запросы с высокой скоростью и весьма хорошей масштабируемостью, а благодаря наличию удобного SQL-интерфейса, любой аналитик в области Big Data может легко работать с Impala, не имея каких-либо специализированных знаний. Именно поэтому Impala является неотъемлемой частью экосистемы Hadoop, являющейся универсальным решением для организации обработки Big Data.
Больше подробностей про применение Apache Impala в проектах анализа больших данных вы узнаете на практических курсах по Impala в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
IMPA: CLOUDERA IMPALA DATA ANALYTICS
ADQM: ЭКСПЛУАТАЦИЯ ARENADATA QUICKMARTS
ADBR: Arenadata DB для разработчиков
ADB: Эксплуатация Arenadata DB
HBASE: Администрирование кластера HBase
HIVE: Hadoop SQL администратор Hive
NoSQL: Интеграция Hadoop и NoSQL
Источники