
Kudu – это колоночное хранилище данных в экосистеме Apache Hadoop, нереляционная СУБД (NoSQL) с открытым исходным кодом от компании Cloudera для оперативной аналитики быстро меняющихся данных в режиме реального времени.
Назначение, история разработки и развития
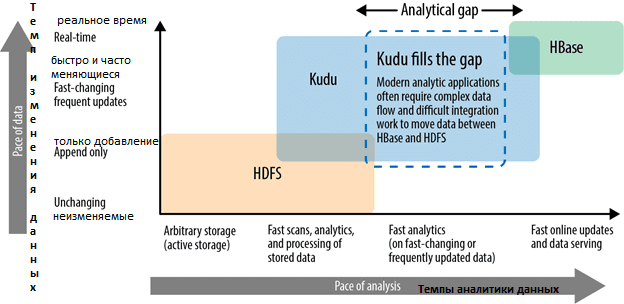
Основное назначение Apache Kudu состоит в заполнении аналитического разрыва между 2-мя движками хранения данных Apache Hadoop: HDFS и HBase. Напомним, HDFS эффективно и надежно хранит большие данные различных форматов с высокой степенью сжатия. Но данные в HDFS невозможно изменить, а также быстро проанализировать в реальном времени. И, наоборот, колоночная NoSQL-СУБД Apache HBase, которая работает поверх HDFS, позволяет быстро искать данные в режиме real-time, но долго сканирует записанные объемы информации. Apache Kudu ориентирован на устранение этого разрыва в экосистеме Hadoop, позволяя оперативно сканировать, читать, искать, записывать, изменять и удалять быстро меняющиеся данные [1].
Основными ключевыми вехами в истории Kudu считаются следующие:
- начало 2015 года – для своих внутренних нужд компания Cloudera запустила собственный проект по созданию новой колоночной СУБД для оперативной аналитики быстро меняющихся больших данных [2];
- конец сентября 2015 года – Cloudera представила Kudu профессиональному сообществу на конференции Strata + Hodoop World 2015, вызвав широкий интерес к данному проект [3];
- сентябрь 2016 года – 1-ая версия Kudu с открытым исходным кодом выпущена под лицензией Apache.
Архитектура и принципы работы Куду
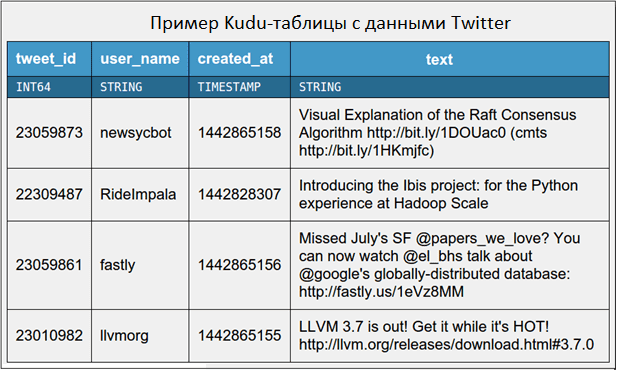
В отличие от большинства NoSQL-СУБД, с точки зрения пользователя данные в Кudu хранятся в таблицах с четко регламентированной структурой, где заданы столбцы, их типы, определены первичные ключи и политики разбиения на разделы. Таким образом, Kudu хранит таблицы подобно реляционным СУБД. Сами таблицы могут быть простыми, например, двоичный ключ и значение, или сложными из нескольких сотен различных строго типизированных атрибутов. Каждая таблица имеет первичный ключ (primary key) из одного или нескольких столбцов, например, уникальный идентификатор id, или составной ключ из технических параметров, таких как host, metric, timestamp. Наличие первичного ключа позволяет эффективно читать, обновлять или удалять строки. Модель данных Kudu позволяет легко переносить унаследованные приложения или создавать новые, не беспокоясь о кодировании данных в двоичные объекты или интерпретации JSON-файлов. Благодаря самостоятельному описанию таблиц (self-describing) для анализа данных можно использовать SQL-инструменты или Apache Spark [4].
В терминах CAP-теоремы Apache Kudu можно отнести к колоночным CP-системам с поддержкой нескольких уровней согласованности данных. Также Куду поддерживает операции обновления и транзакции на уровне записей, обеспечивая высокую производительность при сканировании больших объемов данных и быстрый отклик при поиске [1].
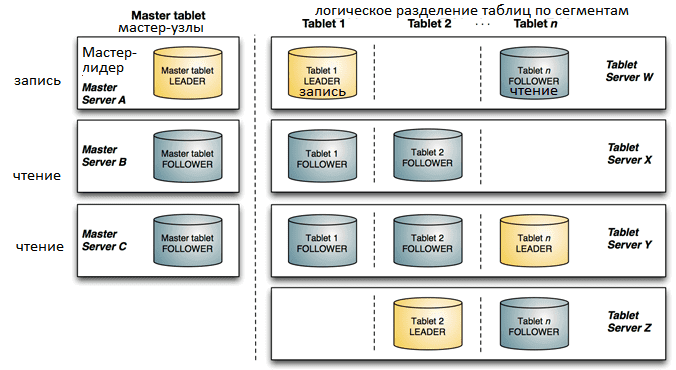
Хотя Apache Kudu является NoSQL-СУБД для Hadoop, в отличие от, например, HBase и других движков работы с данными в этой экосистеме, он не использует HDFS для хранения информации даже косвенно. Файлы записываются напрямую в ext4 или XFS. Сам кластер Apache Kudu состоит из двух типов серверов [1]:
- master – главный узел, который отвечает за управление метаданными и координацию между tablet-узлами;
- tablet – сервера, где хранятся данные, разделенные на логические разделы (tablets), которые представляют собой сегменты таблиц.
Репликация данных между tablet-серверами обеспечивает сохранность данных при отказе отдельных узлов кластера. Обычно каждый логический tablet-раздел хранится на 3-х tablet-серверах, один из которых принимает операции на запись, а остальные – только на чтение. Благодаря такому явному заданию одного лидера, алгоритм распределенного консенсуса RAFT синхронизирует реплики между tablet-узлами через механизм строго последовательной записи [5].
Разделение таблиц на логические сегменты происходит на основе хеш-функций. Сочетание этого с собственной поддержкой составных ключей строк позволяет настроить реплицирование таблицы по нескольким tablet-серверам без единой точки отказа [6].
Где используется Куду: компании и Big Data проекты
Благодаря возможности оперативно обрабатывать быстро меняющиеся данные, Kudu отлично подходит для следующих Big Data приложений [6]:
- потоковый ввод данных в реальном времени, например, при генерации отчетов, когда поступающая информация должна быть немедленно доступна для конечных пользователей;
- формирование OLAP-кубов в проектах аналитики больших данных;
- анализ временных рядов с различными моделями доступа к данным, например, для исследования производительности метрик с течением времени или прогнозирования будущего поведения на основе исторических данных. Kudu позволяет обрабатывать разные вставки и изменения данных индивидуально и в совокупности, с немедленным представлением пользователям. А колоночный принцип хранения данных позволяет считывать информацию из отдельных столбцов, а не всю строку, что еще более повышает скорость работы.
- системы принятия решений в реальном времени с периодическим обновлением прогнозной модели на основе всех исторических данных;
- интеграция приложений и поддержка устаревших систем, когда, например, часть данных хранится в реляционных СУБД, а часть – в HDFS. Благодаря тесной интеграции с компонентами Apache Hadoop и Cloudera Impala, Куду позволяет получить доступ и запросить все эти источники и форматы, не изменяя системы-источники.
Хотя Kudu не предназначен для OLTP-систем, но его можно применять для хранения и быстрой обработки данных с произвольным доступом, помещающихся в оперативную память [4].
Из наиболее интересных примеров практического использования Apache Kudu стоит отметить кейс китайской компании Xiaomi, которая построила на базе этой NoSQL-СУБД собственную BI-платформу для аналитики больших данных и генерации отчетности в реальном времени, сократив цикл аналитической обработки Big Data в тысячи раз. Подробнее об этом читайте в нашей отдельной статье.
Источники
- https://habr.com/ru/post/272267/
- https://ru.bmstu.wiki/Apache_Kudu
- https://www.zdnet.com/article/strata-hadoop-world-cloudera-introduces-recordservice-for-security-kudu-for-streaming-data-analysis/
- https://kudu.apache.org/overview.html
- https://ru.wikipedia.org/wiki/Алгоритм_Raft
- https://kudu.apache.org/docs/#kudu_use_cases