Dataframe - основная абстрация Apache Spark Dataframe - это аналог реляционной таблицы, которая хранится в распределенной памяти кластера обработки данных. Более точно - это не таблица, а алгоритм ее построения: все операции в Spark делятся на трансформации и действия, поэтому "построение" таблицы, как таковой, происходит только в момент выполнения действия...
DevOps

DevOps (DEVelopment OPeration) – это набор практик для повышения эффективности процессов разработки (Development) и эксплуатации (Operation) программного обеспечения (ПО) за счет их непрерывной интеграции и активного взаимодействия профильных специалистов с помощью инструментов автоматизации. Девопс позиционируется как Agile-подход для устранения организационных и временных барьеров между командами разработчиков и других участников жизненного...
Elasticsearch

Elasticsearch – это одна из самых популярных поисковых систем в области Big Data, масштабируемое нереляционное хранилище данных с открытым исходным кодом, аналитическая NoSQL-СУБД с широким набором функций полнотекстового поиска. Назначение и основные функциональные возможности Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить,...
Environment variable
Переменная окружения (среды) ( environment variable) — текстовая переменная операционной системы, хранящая какую-либо информацию — например, данные о настройках системы.
Flink

Apache Flink – это распределенная отказоустойчивая платформа обработки информации с открытым исходным кодом, используемая в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop. Разработанный в 2010 году в Техническом университете Берлина в качестве альтернативы Hadoop MapReduce для распределенных вычислений больших наборов данных, Flink использует подход ориентированного графа,...
Glove
Glove (Global Vectors for Word Representation) - это алгоритм обучения для получения векторных представлений для слов. Обучение выполняется на агрегированной глобальной статистике совпадений слово-слово из корпуса. Полученные представления демонстрируют интересные линейные подструктуры векторного пространства слов, коррелирующие с их семантическим значением.
Golden Copy
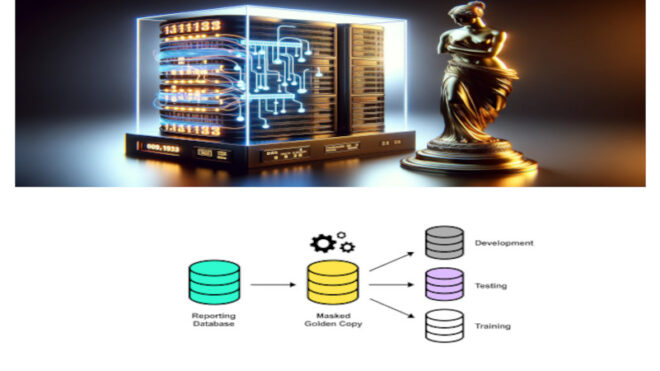
В мире разработки программного обеспечения и управления данными существует понятие "Golden Copy" или "Золотая Копия". Этот термин относится к единственной, авторитетной и доверенной версии данных, которая служит основой для всех других копий в системе. Золотая Копия представляет собой образец данных, который считается источником правды для всей системы. Это позволяет избежать...
Greenplum

Greenplum – open-source продукт, массивно-параллельная реляционная СУБД для хранилищ данных с гибкой горизонтальной масштабируемостью и столбцовым хранением данных на основе PostgreSQL. Благодаря своим архитектурным особенностям и мощному оптимизатору запросов, Гринплам отличается особой надежностью и высокой скоростью обработки SQL-запросов над большими объемами данных, поэтому эта MPP-СУБД широко применяется для аналитики Big...
Hadoop

Hadoop – это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Эта основополагающая технология хранения и обработки больших данных (Big Data) является проектом верхнего уровня фонда Apache Software Foundation. Из чего состоит Hadoop: концептуальная архитектура Изначально проект...
HBase

Apache HBase – это нереляционная, распределенная база данных с открытым исходным кодом, написанная на языке Java по аналогии BigTable от Google. Изначально эта СУБД класса NoSQL создавалась компанией Powerset в 2007 году для обработки больших объёмов данных в рамках поисковой системы на естественном языке. Проектом верхнего уровня Apache Software Foundation HBase стала...
HDFS
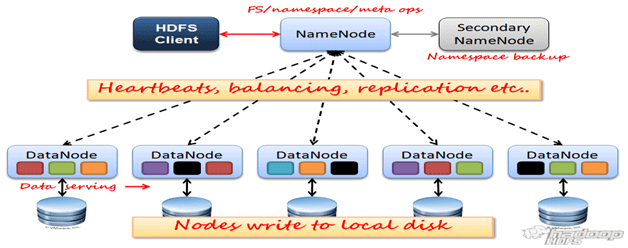
HDFS (Hadoop Distributed File System) — распределенная файловая система Hadoop для хранения файлов больших размеров с возможностью потокового доступа к информации, поблочно распределённой по узлам вычислительного кластера [1], который может состоять из произвольного аппаратного обеспечения [2]. Hadoop Distributed File System, как и любая файловая система – это иерархия каталогов с...
HDInsight

HDInsight - это корпоративный сервис с открытым кодом от Microsoft для облачной платформы Azure, позволяющий работать с кластером Apache Hadoop в облаке в рамках управления и аналитической работы с большими данными (Big Data). Экосистема HDInsight Azure HDInsight – это облачная экосистема компонентов Apache Hadoop на основе платформы данных Hortonworks Data Platform...
Hive
Apache Hive - это SQL интерфейс доступа к данным для платформы Apache Hadoop. Hive позволяет выполнять запросы, агрегировать и анализировать данные используя SQL синтаксис. Для данных в файловой системе HDFS используется схема доступа на чтение, позволяющая обращаться с данными, как с обыкновенной таблицей или реляционной СУБД. Запросы HiveQL транслируются в Java-код...
Hortonworks

Hortonworks Data Platform (HDP) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит Apache Software Foundation, адаптированных компанией Hortonworks для больших данных (Big Data) и машинного обучения (Machine Learning), бесплатно распространяемый и коммерчески поддерживаемый [1]. Помимо HDP, компания Hortonworks предлагает еще другие продукты для Big Data и Machine Learning,...
Impala

Impala – это массово-параллельный механизм интерактивного выполнения SQL-запросов к данным, хранящимся в Apache Hadoop (HDFS и HBase), написанный на языке С++ и распространяющийся по лицензии Apache 2.0. Также Импала называют MPP-движком (Massively Parallel Processing), распределенной СУБД и даже базой данных стека SQL-on-Hadoop. Как появился Apache Impala и чем это связано с...
Impala

Impala - это механизм запросов на языке SQL (Structured Query Language), в основе которого лежит массово-параллельная обработка данных (Massively Parallel Processing, MPP), предполагающая одновременное выполнение множества вычислений благодаря распараллеливанию вычислительных процессов.
Internet of Things
Internet of Things (Интернет вещей) означает сеть физических или виртуальных предметов (вещей) подключенных напрямую или опосредованно к интернету и взаимодействующие между собой и/или с внешней средой посредством сбора данных и обмена данных поступающих со встроенных сервисов. Интернет вещей (IoT) дает компаниям и организациям возможность контролировать удаленно расположенные «дешевые» вещи /объекты ...
Kafka
Apache Kafka - распределенный программный брокер сообщений поддерживающий транзакционность при работе с потребителями и поставщиками событий: публикует и подписывается на поток записей подобно очереди сообщений и корпоративной системе сообщений хранит поток записей (событий) обеспечивая отказоустойчивость и надежность обрабатывает поток записей (событий) по мере поступления Apache Kafka обычно используется как Event...
Kafka Streams
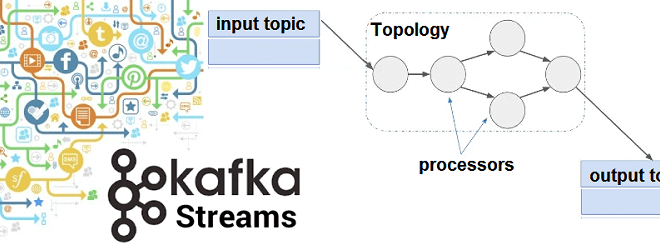
Kafka Streams – это клиентская библиотека для разработки потоковых приложений Big Data, которые работают с данными, хранящимися в топиках Apache Kafka. Она предоставляет мощный и гибкий API-интерфейс со всеми преимуществами Кафка-платформы (масштабируемость, надежность, минимальную задержку, механизмы аналитических запросов), позволяя разработчику писать код в локальном режиме (вне кластера). Kafka Streams API,...
KNOX
Apache KNOX - REST API и шлюз приложений для компонентов экосистемы Apache Hadoop, обеспечивает единую точку доступа для всех HTTP соединений с кластерами Apache Hadoop и систему единой аутентификации Single Sign On (SSO) для сервисов и пользовательского интерфейса компонент Apache Hadoop. В сочетании с средствами сетевой изоляции и аутентификацией Kerberos, KNOX...