
Yandex Managed Data Proc (YMDP) - это мощный инструмент для обработки и анализа Big Data, предоставляемый Yandex Cloud. Он позволяет эффективно управлять распределенными вычислениями экосистемы Hadoop, обеспечивая высокую производительность и масштабируемость.
Yandex Managed GreenPlum

Яндекс, один из ведущих технологических гигантов, предоставляет множество облачных сервисов, включая Yandex Managed GreenPlum - управляемый сервис для работы с распределенной базой данных GreenPlum. GreenPlum - это мощная система управления данными, основанная на архитектуре PostgreSQL, предназначенная для обработки больших объемов данных. В этой статье мы рассмотрим, как использовать Yandex Managed...
Yandex Managed Kafka

Apache Kafka является распределенной системой обмена сообщениями, широко используемой для построения отказоустойчивых и масштабируемых потоков данных. Yandex Managed Kafka предоставляет управляемый сервис Kafka, который облегчает развертывание и управление кластерами Kafka без необходимости заботиться о инфраструктуре.
YARN
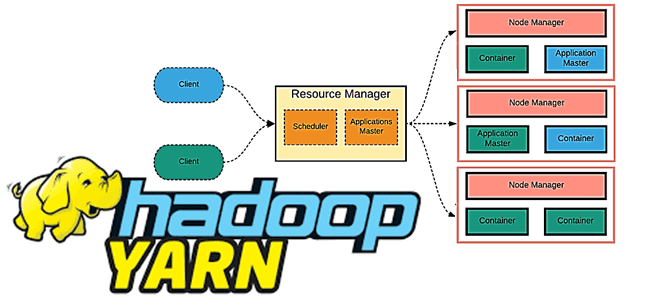
YARN – это система планирования заданий и управления кластером (Yet Another Resource Negotiator), которую также называют MapReduce 2.0 – набор системных программ (демонов), обеспечивающих совместное использование, масштабирование и надежность работы распределенных приложений. YARN является интерфейсом между аппаратными ресурсами кластера и приложениями, использующих его мощности для вычислений и аналитики больших данных....
Zookeeper

Apache Zookeeper - open source проект Apache Software Foundation, cервис-координатор, который обеспечивает распределенную синхронизацию небольших по объему данных (конфигурационная информация, пространство имен) для группы приложений. Zookeeper представляет из себя распределенное хранилище ключ-значение (key-value store), гарантирующий надежное консистентное (consistency) хранение информации за счет синхронной репликации между узлами, контроля версий, механизма очередей (queue) и блокировок...
Блокчейн

Блокчейн (от английского blockchain, block chain – цепочка блоков) — выстроенная по определённым правилам непрерывная последовательность информационных блоков (связный список). Копии цепочек блоков хранятся на множестве разных, независимых друг от друга, компьютеров [1]. Поэтому данную цифровую цепочку называют технологией распределенного реестра [2]. История появления блокчейна Цифровизация финансовой сферы стала родоначальником термина...
Большие данные
Большие данные (Big Data) Большие данные - данные большого объема, высокой скорости накопления или изменения и/или разновариантные информационные активы, которые требуют экономически эффективных, инновационных формы обработки данных, которые позволяют получить расширенное понимание информации, способствующее принятию решений и автоматизации процессов. Для каждой организации или компании существует предел объема данных (Volume) которые...
Большие данные (Big Data)

Большие данные (Big Data) – совокупность непрерывно увеличивающихся объемов информации одного контекста, но разных форматов представления, а также методов и средств для эффективной и быстрой обработки [1]. Big Data: какие данные считаются большими Благодаря экспоненциальному росту возможностей вычислительной техники, описанному в законе Мура [2], объем данных не может являться...
Ввод и вывод в Apache Spark
Ввод и вывод в Apache Spark Apache Spark имеет простые, удобные и универсальные механизмы ввода вывода. С их помощью просто "читать" и "писать" файлы различных форматов (поддерживаются текстовые файлы, CSV, JSON, Parquet, ORC), а также работа с базами данных (через JDBC). Spark может использовать общие с Hive метаданные, тем самым...
Естественная классификация
Естественная классификация - разделение (или, наоборот, группировка) предметов и явлений по существенным признакам, характеризующим их внутреннюю общность. В отличие от искусственной классификации, которая сосредоточена на внешних признаках, естественная больше ориентируется на внутреннее содержание исследуемого предмета. В частности, группировка предмета со схожими по сути (овощи, посуда, техника) - это естественная классификация....
Интернет вещей
Интернет вещей (Internet of Things) - Интернет вещей означает сеть физических или виртуальных предметов (вещей) подключенных напрямую или опосредованно к интернету и взаимодействующие между собой и/или с внешней средой посредством сбора данных и обмена данных поступающих со встроенных сервисов. Интернет вещей (IoT) дает компаниям и организациям возможность контролировать удаленно расположенные...
Искусственная классификация
Искусственная классификация - разделение объектов по внешнему признаку для придания множеству исследуемых предметов (процессов, явлений) нужного порядка. Вообще в Data Mining, Data Science и машинном обучении (Machine Learning) в частности, искусственная классификация используется в рамках подготовки данных к моделированию, на этапе формирования датасета. Например, Data Scientist может заниматься искусственной классификацией...
Классификация
Классификация - системное распределение изучаемых предметов, явлений, процессов по родам, видам, типам, по каким-либо существенным признакам для удобства их исследования; группировка исходных понятий и расположение их в определенном порядке, отражающем степень этого сходства.
Машинное обучение
Машинное обучение (Machine Learning) — класс методов искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться
Мультиколлинеарность
Мультиколлинеарность — корреляция независимых переменных [1], которая затрудняет оценку и анализ общего результата [2]. Когда независимые переменные коррелируют друг с другом, говорят о возникновении мультиколлинеарности. В машинном обучении (Machine Learning) мультиколлинеарность может стать причиной переобучаемости модели, что приведет к неверному результату [3]. Кроме того, избыточные коэффициенты увеличивают сложность модели машинного...
Ошибка распознавания
отношение объектов, неправильно классифицированных в процессе обучения, к общему количеству объектов набора данных, которые принимали участие в обучении
Прогнозирование
Прогнозирование направлено на определение тенденций динамики конкретного объекта или события на основе исторических данных, т.е. анализа его состояния в прошлом и настоящем. Таким образом, решение задачи прогнозирования требует некоторой обучающей выборки данных.
Продюсер
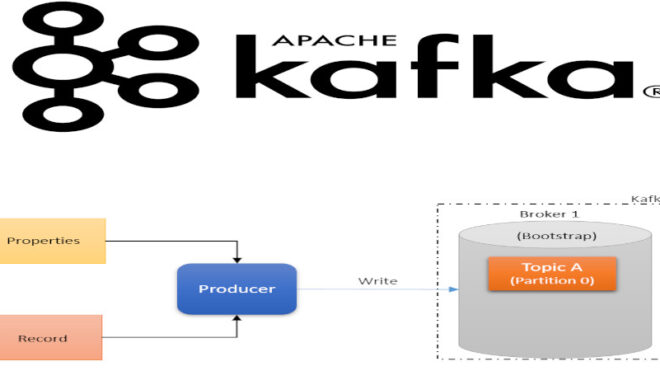
Продюсер (Producer) - приложение, которое создает и передает события в виде сообщений для потребителей
Профессии в Data Science
Две базовые профессии в Data Science - это инженер данных (data engineer) и дата сайентист (data scientist). Если совсем кратко, то дата сайентист занимается построением моделей, инженер данных обеспечивает дата сайентиста данными. Если рассмотреть работу инженера данных более подробно, то можно выделить следующие категории работ и работы в этих категориях...