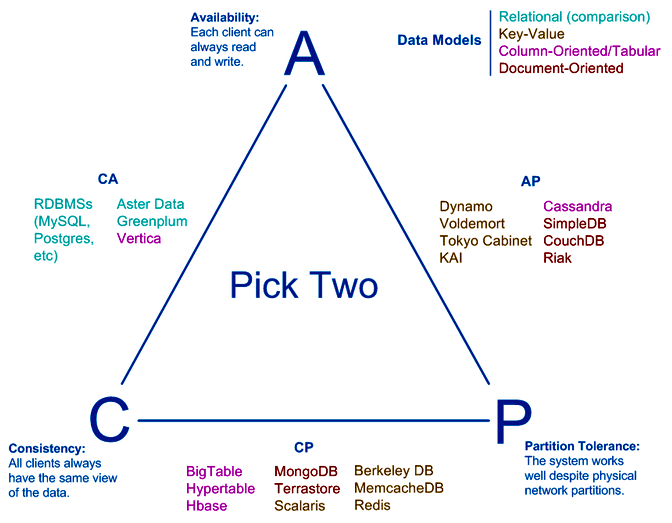
CAP – это акроним от англоязычных слов Consistency (Согласованность, Целостность), Availability (Доступность) и Partition tolerance (Устойчивость к разделению). Согласно утверждению профессора Калифорнийского университета в Беркли, Эрика Брюера, сделанному в 2000-м году, в распределенных системах осуществимы лишь 2 свойства из указанных 3-х. В частности, считается что нереляционные базы данных жертвуют согласованностью данных в...
Case Based Reasoning (CBR)
Case Based Reasoning (CBR) - метод решения проблем рассуждением по аналогии, путем предположения на основе подобных случаев (прецедентов). Это способ решения проблем на основе уже известных решений, который широко применяется во всех областях деятельности. Например, в бизнес-анализе такое сопоставление с эталоном, целенаправленный поиск и внедрение лучших практик со стороны называется...
Cassandra

Apache Cassandra – это нереляционная отказоустойчивая распределенная СУБД, рассчитанная на создание высокомасштабируемых и надёжных хранилищ огромных массивов данных, представленных в виде хэша. Проект был разработан на языке Java в корпорации Facebook в 2008 году, и передан фонду Apache Software Foundation в 2009 [1]. Эта СУБД относится к гибридным NoSQL-решениям, поскольку она...