
Apache NiFi - это простая платформа обработки событий (сообщений), предоставляющая возможности управления потоками данных из разнообразных источников в режиме реального времени с использованием графического интерфейса. Программа Apache NiFi написана на Java и была разработана Агентством Национальной Безопасности (NSA) под кодовым названием «Niagara Files» для диспетчеризации данных, поддерживающих работу с разнообразными небольшими сетевыми...
NLTK
NLTK (Natural Language Toolkit) - это ведущая платформа для создания программ на Python для работы с данными на человеческом языке. NLTK предоставляет простые в использовании интерфейсы для более чем 50 корпоративных и лексических ресурсов, таких как WordNet. NLTK включает в себя большой набор библиотек обработки текста для классификации, токенизации, обработки...
NoSQL
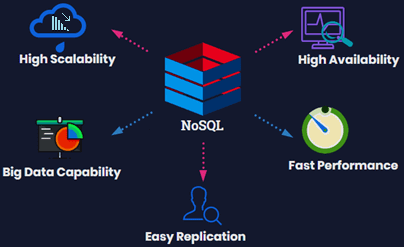
NoSQL – это подход к реализации масштабируемого хранилища (базы) информации с гибкой моделью данных, отличающийся от классических реляционных СУБД. В нереляционных базах проблемы масштабируемости (scalability) и доступности (availability), важные для Big Data, решаются за счёт атомарности (atomicity) и согласованности данных (consistency) [1]. Зачем нужны нереляционные базы данных в Big Data:...