 1245
1245 
Содержание
DataOps (DATA Operations, датаопс), по аналогии с DevOps (DEVelopment Operations, девопс) — это концепция и набор практик непрерывной интеграции данных между процессами, командами и системами для повышения эффективности корпоративного управления или отраслевого взаимодействия за счет распределенного сбора, централизованной аналитики и гибкой политики доступа к информации с учетом ее конфиденциальности, ограничений на использование и соблюдения целостности [1]. Как связаны DataOps, цифровизация и Agile-подходы, насколько это выгодно бизнесу и какие инструменты обеспечивают непрерывную работу с Big Data на практике, читайте в нашей сегодняшней статье.
Как все началось: предпосылки появления DataOps
Термину DataOps еще не исполнилось 5 лет, а он уже активно используется в ИТ-мире. Впервые это понятие прозвучало в 2015 году, а затем стало тиражироваться в контексте цифровизации и построения компаний, управляемых данными (data-driven enterprise) на примере Facebook [1].
Если главной целью DevOps считается быстрая и непрерывная поставка бизнесу работающего программного обеспечения [2], то DataOps предполагает оперативное и безбарьерное предоставление актуальных и рабочих данных каждому участнику корпоративных процессов. Это означает устранение когнитивных, временных и организационных разрывов между исследователями данных (data scientist’ы), бизнес-аналитиками, разработчиками, руководителями и пользователями Big Data.
Такая демократизация данных повышает скорость реакции на любые изменения, что весьма актуально для современного бизнеса и соответствует принципам Agile [2]. Большие данные нестатичны, поэтому нужны не только надежные и быстрые технологии их обработки, необходима гибкость прикладных и управляющих процессов, а также изменение корпоративной культуры, когда информация становится главной ценностью и основным средством осуществления деятельности. Иначе, какой смысл, например, от высочайшего качества аналитических моделей машинного обучения (Machine Learning), которые разработал data scientist, если эта информация вовремя не передана лицам, использующим ее для текущей работы или принятия стратегических решений?
В свою очередь, непрерывная аналитика данных в течение всего жизненного цикла повышает не только их значимость для бизнеса, но и обеспечивает лучшую защиту информации от утечек и других нарушений информационной безопасности за счет согласованной политики доступа [3].
Методы и средства реализации датаопс в Big Data
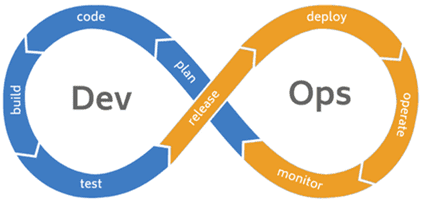
Аналогично DevOps, когда разработка и эксплуатация интегрированы в единый процесс взаимодействия специалистов по кодированию, тестированию, развертыванию и поддержке, DataOps реализует идею непрерывной интеграции, доставки и обработки данных. Для этого в Big Data проектах используются методы Agile (Scrum, Kanban и их разновидности), командные системы управления проектами, средства управления версиями (GitHub и пр.), технологии контейнеризации и виртуализации (Docker, Rocket, Kubernetes и т.д.), а также технические решения для управляемого конвейера данных [1].
Для бесперебойной работы конвейера данных цифрового предприятия (data-driven company) его ИТ-инфраструктура должна обеспечивать следующие процессы [1]:
- оркестрация информационных потоков – движение Big Data по маршрутной карте с описанием всех источников данных, моделей их представления и интеграции, а также шагов процесса анализа. Для этого можно использовать Apache AirFlow, Oozie (планировщик процессов заданий Apache Hadoop), BMC Control-M (решение по автоматизации пакетной обработки, DataKitchen (платформа DataOps поддержки всего цикла аналитической обработки, сокращающая время подготовки и доставки данных нужного качества), Reflow (система инкрементальной обработки данных в облаке с помощью произвольных программ, упакованных в контейнеры Docker).
- автоматизированное тестирование и обеспечение качества данных – проверка и очистка информации на каждом этапе ее обработки. Возможно применение ICEDQ (ПО для автоматизации тестирования при работе с ETL-хранилищами и средствами миграции данных), Naveego (облачная платформа для построения информационных панелей и витрин с целью мониторинга состояния данных и управления исключениями). Подробнее об этом читайте в нашей новой статье про наблюдаемость данных.
- автоматическое распределение – непрерывное перемещение кода и конфигураций по всем этапам CRISP-DM, от постановки задачи с позиции бизнеса до внедрения. Здесь следует использовать инструменты DevOps, например, Jenkins для непрерывной поставки ПО с автоматическим контролем всех этапов жизненного цикла приложения от написания кода к сборке, автоматическому тестированию и развертыванию в эксплуатационных средах.
- развертывание моделей данных и управление «песочницами» — формирование воспроизводимых сред работы с данными с помощью DevOps: бесшовная интеграция, ускорение процессов извлечения данных для бизнеса, разработки и развертывания приложений и аналитических моделей (Domino, Open Data Group, DSFlow).
- виртуализация данных и управление тестовыми данными, включая их защиту и мониторинг производительности (Delphix, Redgate).
- интеграция и унификация данных, в т.ч. с использованием Machine Learning (Tamr, Switchboard Software).
- мониторинг и управление производительностью локальных и облачных решений – наблюдение за текущими процессами хранения и обработки больших данных, а также выявление аномалий. Возможно применение SelectStar (мониторинг баз данных), Unravel (средство управления производительностью и работой с приложениями и платформами Big Data); MapR (конвергентная платформа работы с большими данными, объединяющая инструменты аналитики реального времени и операционные бизнес-приложения), Quobole (облачная платформа Вig Data as a Service).
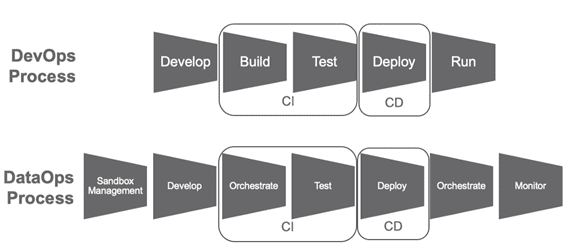
За встраивание этих средств в корпоративную ИТ-инфраструктуру и поддержку других технологий больших данных отвечают DevOps- и DataOps-инженеры. Как именно разграничены задачи этих специалистов, и чем конкретно занимается каждый из них, читайте в нашей следующей статье. А реальные приемы настройки, администрирования и использования больших данных осваивайте у нас на практических курсах в специализированном учебном центре обучения руководителей, администраторов, аналитиков, data engineer’ов, data scientist’ов и пользователей больших данных в Москве:
Источники

