 1617
1617 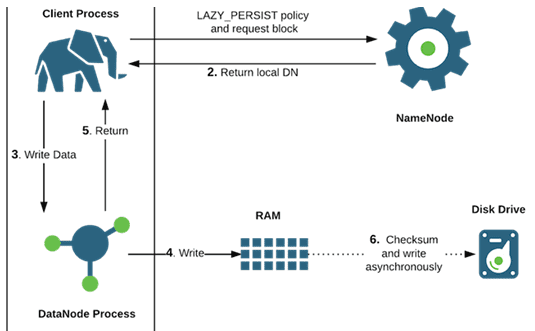
Содержание
HDFS предназначена для больших данных (Big Data), поэтому размер файлов, которые хранится в ней, существенно выше чем в локальных файловых системах – более 10 GB [1]. Продолжая тему файловых операций и взаимодействия компонентов Hadoop Distributed File System, в этой статье мы расскажем, как осуществляется запись таких больших файлов с учетом блочного расположения информации в HDFS и кластерной архитектуры Hadoop.
Запись данных в HDFS
Информация записывается в потоковом режиме, за счет чего достигается высокая пропускная способность. Клиент, осуществляющий запись, кэширует данные во временном локальном файле, пока их объем не достигнет размера одного HDFS-блока (по умолчанию 64 MB). Накопив данные на один блок, клиент отправляет на сервер имен NameNode запрос на создание файла, указав размер блока для создаваемого файла и количество реплик.
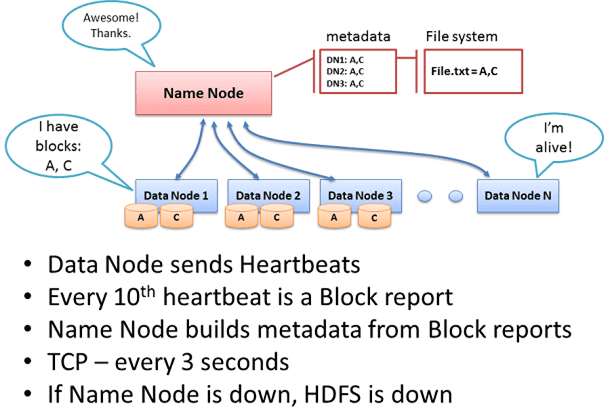
Сервер имен регистрирует новый файл, выделяет блок и возвращает клиенту идентификаторы узлов данных для хранения копий (реплик) этого HDFS-блока [2]. Также сервер имен уведомляет другие узлы данных, на которые будут писаться реплики файлового блока.
Все блоки в HDFS, кроме последнего блока файла, имеют одинаковый размер. Каждый блок может быть размещён на нескольких узлах. Размер блока и коэффициент репликации – число узлов для размещения каждого HDFS-блока – определяются в файловых настройках. Репликация обеспечивает устойчивость системы к отказам отдельных узлов [1].
Клиент начинает передачу данных блока из временного файла первому по списку узлу данных, который сохраняет информацию на своем диске и пересылает ее следующему серверу данных. Второй узел передает данные третьему и далее: файловый поток передается в конвейерном режиме и автоматически реплицируется на нужном количестве узлов. Все HDFS-блоки реплицируются столько раз, сколько было указано клиентом (по умолчанию 3). Для повышения надежности узлы для хранения 2-ой и 3-ей реплики располагаются в разных серверных стойках. Расположение следующих реплик вычисляется произвольно. Для защиты от сбоев можно настроить кластер так, чтобы сервер имен знал, на каких серверных стойках расположены узлы данных. Для этого используется специальный механизм Hadoop — rack awareness.
По завершении записи HDFS-блока каждый узел данных из цепочки в обратном порядке (т.е. с конца) отправляет клиенту сообщения об успешной операции. После этих подтверждений клиент оповещает сервер имен об успешной записи блока и получает цепочку узлов данных для записи 2-го блока и т.д.
Если сервер имен не принимает от узла данных heartbeat-сообщений, он считает этот DataNode вышедшим из строя (умершим) и реплицирует данные, хранящиеся на этом узле, на другие сервера данных (живые) [3]. Если клиент смог успешно записать блок хотя бы на 1 узел, можно не беспокоиться за дальнейшую репликацию – это находится в сфере ответственности сервера имен, который сам обеспечит распространение информации на нужном уровне [4].
Окончив запись, клиент уведомляет сервер имен NameNode, который фиксирует транзакцию создания файла в своем журнале. После этого HDFS-файл становится доступным для использования: чтения, повторной репликации или удаления [2].
Все нюансы практической работы с HDFS: настройка, администрирование и использование экосистемы Hadoop в инфраструктуре Big Data и Machine Learning в нашем учебном центре для начинающих и профессионалов — компьютерные курсы обучения пользователей, инженеров, администраторов и аналитиков больших данных в Москве:
- INTR: Основы Hadoop;
- HADM: Администрирование кластера Hadoop;
- HIVE: Hadoop SQL Hive администратор.
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
- BAHU: Основы Hadoop для пользователей
Источники

