 1474
1474 
Содержание
В прошлой статье мы рассмотрели основные возможности и ключевые характеристики Apache Hive и Cloudera Impala. Сегодня подробнее поговорим про то, что между ними общего и чем отличаются друг от друга эти SQL-инструменты для обработки больших данных (Big Data), хранящихся в кластере Hadoop.
Что общего между Apache Hive и Cloudera Impala: 5 главных сходств
Сначала поговорим о том, чем похожи рассматриваемые SQL-инструменты для Apache Hadoop. Проанализировав их основные функциональные возможности и примеры использования, мы выделили следующие общие характеристики:
- прикладное назначение – Hive (Хайв) и Impala (Импала), в первую очередь, ориентированы на аналитическую обработку данных, хранящихся в экосистеме Hadoop (HDFS, HBase) и некоторых других распределенных файловых системах (Amazon S3) [1].
- Обе системы представляют собой решения с открытым исходным кодом и свободно распространяются по лицензии Apache Software Foundation (ASF). Тем не менее, изначально Импала является продуктом компании Cloudera, тогда как Хайв была разработана корпорацией Facebook в 2010 году, а затем передана фонду ASF [2].
- SQL-подобный синтаксис (Hive SQL) — Impala использует те же метаданные, драйвер ODBC, пользовательский интерфейс и SQL-подобный язык запросов (HiveQL), что и Apache Hive [3].
- Использование YARN в качестве кластерного менеджера ресурсов, который позволяет управлять всеми ресурсами обработки данных в кластере, назначая их запрашивающим приложениям, таким образом, поддерживая баланс выполнения заданий в распределенной среде [4].
- Распространение коммерческих дистрибутивов от компании Cloudera, которая поглотила корпорацию Hortonworks, ранее продвигавший Хайв.
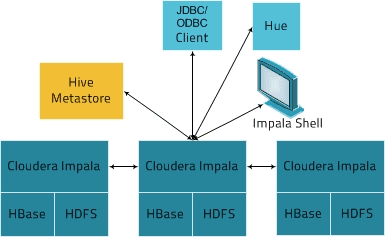
В чем разница между Hive и Impala: 10 ключевых отличий
При всех вышеотмеченных сходствах, рассматриваемые SQL-инструменты для Apache Hadoop существенно отличаются друг от друга по следующим параметрам:
- Режим обработки данных – Impala обрабатывает SQL-запросы на лету, реализуя интерактивные вычисления в режиме онлайн, тогда как Hive не походит для OLTP-задач, т.к. работает с пакетами данных не в реальном времени [5].
- Языки разработки – Хайв написан на Java, тогда как Импала – на C++. Это обусловливает более эффективное использование памяти в Impala, несмотря на то в Hive повторно используются экземпляры JVM (Java Virtual Machine), чтобы частично снизить накладные расходы при запуске виртуальной машины. Однако, Impala, разработанный на C ++, иногда может не работать с форматами, написанными на Java [5].
- Форматы данных – Impala работает с форматами LZO, Avro и Parquet, а Hive – c Plain Text и ORC. При этом обе рассматриваемые системы поддерживают форматы RCFIle и Sequence.
- Вычислительная модель – Impala основана на архитектуре массовой параллельной обработки (MPP, Massive Parallel Processing), благодаря чему реализуется распределенное многоуровневое обслуживание дерева для отправки SQL-запросов с последующей агрегацией результатов из его листьев [5]. Также MPP позволяет Импала распараллеливать обработку данных, поддерживая интерактивные вычисления. В свою очередь, Hive использует технологию MapReduce, преобразуя SQL-запросы в задания Apache Spark или Hadoop [1].
- Задержка обработки данных (latency) – в связи с разными вычислительными моделями, рассматриваемые системы по-разному обрабатывают информацию. Cloudera Impala выполняет SQL-запросы в режиме реального времени. Для Apache Hive характерна высокая временная задержка и низкая скорость обработки данных. Impala способна работать в 6-69 раз быстрее Хайв с простыми SQL-запросами. Однако, со сложными запросами Hive справляется лучше благодаря LLAP [1].
- Пропускная способность Hive существенно выше, чем у Impala [6]. LLAP-функция (Live Long and Process), которая разрешает кэширование запросов в памяти, обеспечивает Hive хорошую производительность на низком уровне. LLAP включает долговременные системные службы (демоны), что позволяет напрямую взаимодействовать с узлами данных HDFS и заменяет тесно интегрированную DAG-структуру запросов (Directed acyclic graph) – графовую модель, активно используемую в Big Data вычислениях [1].
- Кодогенерация – Hive генерирует выражения запросов во время компиляции (compile time), тогда как Impala — во время выполнения (runtime). Для Хайв характерна проблема «холодного старта», когда при первом запуске приложения запросы выполняются медленно из-за необходимости установки подключения к источнику данных. В Импала отсутствуют подобные накладные расходы при запуске, т.к. необходимые системные службы (демоны) для обработки SQL-запросов запускаются во время загрузки (boot time), что ускоряет работу [1].
- Отказоустойчивость – Хайв является отказоустойчивой системой, которая сохраняет все промежуточные результаты. Это также положительно влияет на масштабируемость, однако приводит к снижению скорости обработки данных. В свою очередь, Impala нельзя назвать отказоустойчивой платформой [1].
- Безопасность – в Хайв отсутствуют инструменты обеспечения кибербезопасности, тогда как Impala поддерживает аутентификацию Kerberos [6].
- Основные пользователи – с учетом отказоустойчивости и высокой пропускной способности Хайв, эта система более адаптирована для промышленной эксплуатации в условиях высоких нагрузок, когда допустима некоторая временная задержка (latency). Поэтому она в большей степени востребована у инженеров больших данных (Data Engineer) в рамках построения сложных ETL-конвейеров. А быстрая и безопасная, но не слишком надежная Impala лучше подходит для менее масштабных проектов и пользуется популярностью у аналитиков и ученых по данным (Data Analyst, Data Scientist) [6].
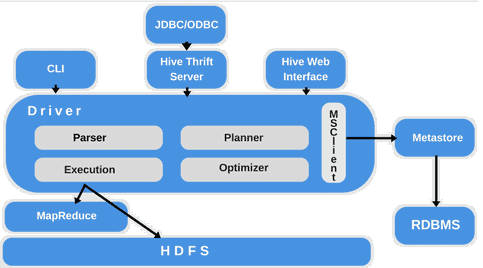
Таким образом, рассмотренные сходства и различия Cloudera Impala и Apache Hive подтверждают, что данные SQL-инструменты для аналитической обработки данных, хранящихся в экосистеме Hadoop, не конкурируют, а дополняют друг друга. Аргументы выбора того или иного решения мы приводим здесь, вместе с реальными примерами использования. А в следующей статье подробнее рассмотрим разницу их использования и работы с точки зрения разработчика Big Data: процесс генерации и выполнения запросов, потребление памяти, расширяемость и другие аспекты, важные для программиста, а также поговорим про язык HiveQL.
Узнайте больше про аналитику больших данных с помощью этих SQL-инструментов на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://data-flair.training/blog/impala-vs-hive/
- https://ru.wikipedia.org/wiki/Apache_Hive
- https://ru.bmstu.wiki/Apache_Impala
- https://ru.bmstu.wiki/YARN_(Yet_Another_Resource_Negotiator)
- https://www.dezyre.com/article/impala-vs-hive-difference-between-sql-on-hadoop-components/180
- https://www.educba.com/hive-vs-impala/

