 1016
1016 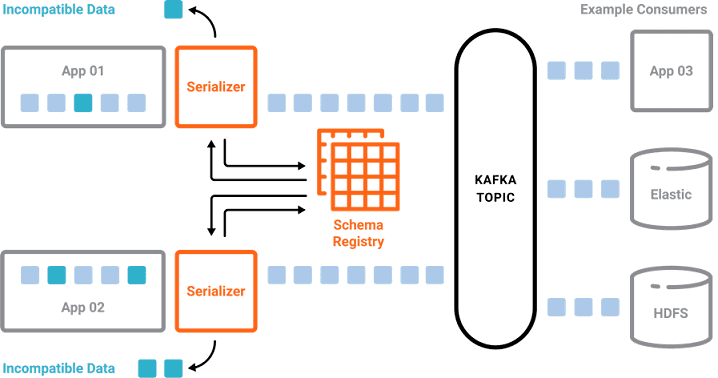
Содержание
Продолжая серию публикаций про основы Apache Kafka для начинающих, в этой статье мы рассмотрим, зачем этой распределенной системе управления сообщениями нужен реестр схем данных (Schema Registry) и что такое сериализация файлов Big Data.
Что такое схемы данных в Big Data и как они используются
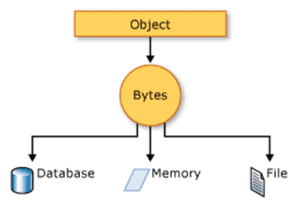
Понятие схемы неразрывно связано с форматом данных, который регламентирует структуру представления информации. Схема предписывает как обрабатывать тот или иной формат. Например, для обработки JSON-файлов используются схемы данных, отличные от схем для работы с изображениями PNG, GIF и прочих графических форматов. Любые файлы, в т.ч. Big Data, хранятся и передаются по сети в виде неструктурированной последовательности двоичных символов – битов, упакованных в байты. Перевод из формата – структуры, семантически понятной человеку, в двоичное представление для машинной обработки называется сериализацией [1]. Характер этой операции преобразования объекта в поток байтов для сохранения/передачи в память, базу данных или файл определяется схемой данных [2].
Файлы Big Data характеризуются большим объемом и разнообразием форматов, поэтому для их программной обработки, например, извлечения конкретных данных в рамках SQL-подобного запроса, активно используются различные схемы. В Apache Kafka механизм работы с разными схемами данных реализован специальным компонентом – реестром схем (Schema Registry).
Благодаря этому схемы данных в Apache Kafka реализуют следующие действия [3]:
- позволяют отправителям (producer) и потребителям (consumer) сообщений определить поля, необходимые для описания события, а также идентифицировать тип каждого поля;
- документируют события и значение каждого его поля в виде, понятном человеку (т.е. не бинарном представлении);
- предотвращают получение искаженных данных потребителями, поскольку в топик (topic) попадут только те сообщения, которые соответствуют схеме;
- делают возможной работу с различными форматами данных от разных источников информации.
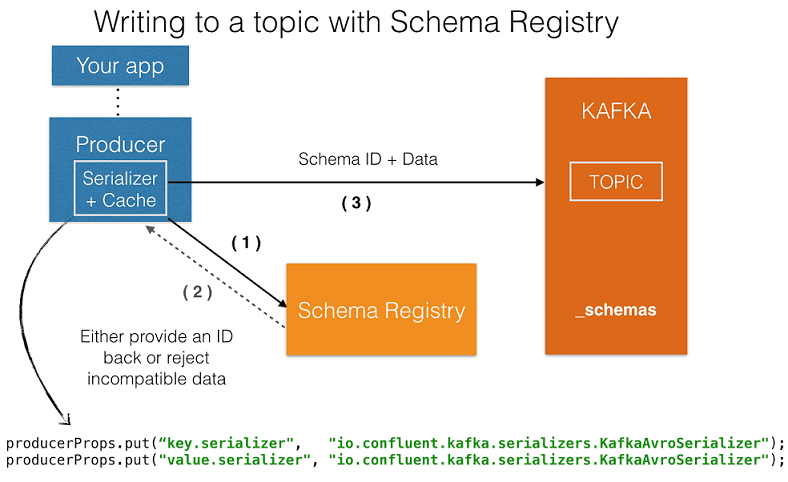
Широко используемая на практике версия Apache Kafka от компании Confluent включает графический интерфейс реестра схем, который позволяет [4]:
- визуализировать схемы данных;
- выполнять поиск по схемам;
- регистрировать новую схему;
- отображать команды работы со схемами.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
16 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
5 преимуществ использования схем данных в Apache Kafka
Учитывая специфику Apache Kafka, как наиболее популярного брокера потоковых сообщений среди Big Data систем, отметим следующие ключевые для нее плюсы схем данных [3]:
- независимость данных от приложений – отправители сообщений генерируют информационные потоки, а получатели сами обращаются к нужным данным согласно схеме;
- четкая регламентация вида представления информации – наличие единого инструментария для описания данных;
- семантическая ясность – смысловое назначение каждого поля, определенное в документации, позволяет избежать неверных интерпретаций в распределенной команде разработчиков;
- обеспечение совместимости при изменении структур и форматов данных, например, удалении или добавлении нового поля. Схема данных позволяет отслеживать модификации данных и объективно оценивать возможность обработки новых информационных структур с помощью уже существующего инструментария.
- Автоматизация процессов подготовки данных к моделированию (Data Preparation) – Благодаря наличию только действительных данных, соответствующих схеме, разработчику или, Data Scientist’у не приходится тратить время на ручную обработку информационного массива, например, выделяя поля с регулярным выражением из неправильно отформатированных данных CSV-файла со множеством запятых внутри самих значений типовых полей.
Вообще понятия сериализации, десериализации и схем данных применимы ко всей ИТ-области, а не только к Big Data. Однако, в связи с высокими требованиями к объему и скоростям обработки информации больших данных, существуют системы сериализации и схемы данных, разработанные специально для Big Data. Наиболее популярными среди них считаются Apache Avro и Apache Parquet [5], которые мы рассмотрим в следующей статье. А про проблемы сериализации и десериализации очень больших сообщений в Apache Kafka читайте здесь и здесь.
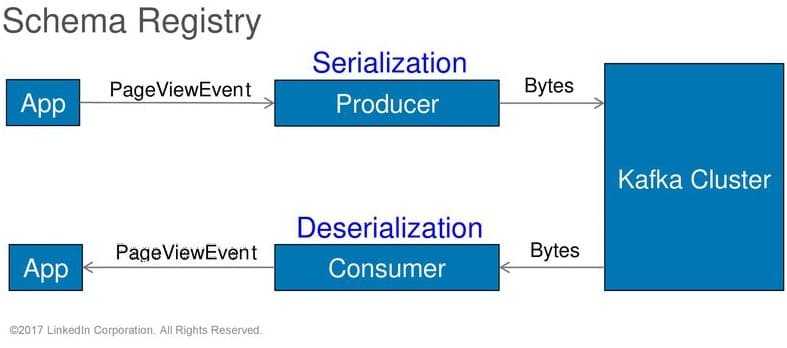
Подробнее о том, что под капотом реестра схем Kafka Confluent, читайте в нашей новой статье. О том, как инженеры Expedia Group организовали безопасное взаимодействие клиента Kafka с реестром схем по REST API, мы рассказываем здесь. Какие исключения могут возникнуть при использовании реестра схем, разбирается в этом материале.
А больше практических подробностей про администрирование и эксплуатацию Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://ru.wikipedia.org/wiki/Формат_файла
- https://docs.microsoft.com/ru-ru/dotnet/csharp/programming-guide/concepts/serialization/
- https://www.confluent.io/blog/avro-kafka-data/
- https://lenses.io/blog/2016/08/schema-registry-ui/
- http://datareview.info/article/test-proizvoditelnosti-apache-parquet-protiv-apache-avro/

