 1137
1137 
Содержание
В продолжение темы про совместное использование Apache Kudu с другими технологиями Big Data, сегодня рассмотрим, как эта NoSQL-СУБД работает вместе с Kafka, Spark и Cloudera Impala для построения озера данных (Data Lake) для быстрой аналитики больших данных в режиме реального времени. Также читайте в нашей статье про особенности интеграции Apache Kudu со Spark SQL.
Зачем совмещать Apache Kudu с Kafka и Spark или быстрая альтернатива традиционному Data Lake на Hadoop
Рассмотрим пример типичной Big Data для потокового анализа данных на базе Data Lake, куда информация непрерывно передается из кластера Kafka. Там новые данные обогащаются историческими, чтобы конечные пользователи (BI-приложения, Data Scientist’ы и аналитики Big Data) использовали их для своих бизнес-нужд анализ. При этом производительность системы является ключевым фактором, который обеспечивает возможность быстро принимать, преобразовывать и записывать данные. Таким образом, для оперативной аналитики запросы конечных пользователей также должны выполняться очень быстро.
В экосистеме Apache Hadoop такая Big Data система может быть реализована с помощью NoSQL-СУБД Hbase для быстрого случайного чтения и записи. Возможно хранение таблиц в формате Parquet в HDFS и применение средств SQL-on-Hadoop, например, Cloudera Impala, для интерактивной аналитики с помощью структурированных запросов. Также данные из Data Lake будут доступны для запросов в Apache Spark и Hive. Таким образом, придется работать с 4-мя разными инструментами в одной системе, инвестируя ресурсы в каждый из них, чтобы использовать их преимущества. Можно упростить архитектуру такой системы с помощью Apache Kudu, представив процесс обработки данных следующим образом [1]:
- Kafka передает данные в Spark, например, так, как мы рассказывали здесь;
- Spark принимает и преобразовывает потоковые данных;
- Kudu предоставляет слой быстрого хранения, который буферизует данные в памяти и сбрасывает их на диск;
- можно использовать Impala для запроса к итоговым таблица Kudu, чтобы немедленно предоставить нужные данные BI-приложениям и конечным пользователям.
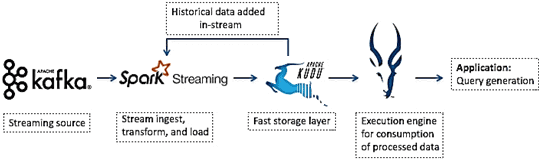
Примечательно, что весь код для реализации такого конвейера обработки данных (data pipeline) может быть написан на одном языке, поддерживаемом Спарк , например, Java, Scala или PySpark. Дополнительную привлекательность решения обусловливают следующие особенности [1]:
- API-интерфейсы таких структур данных Spark как DataSets и DataFrames являются высокоуровневыми и хорошо спроектированными;
- микропакетная архитектура Spark Streaming позволяет повторно использовать код с другими компонентами Спарк ;
- API интеграции Spark с Kudu прост, но при этом эффективно обеспечивает высокую пропускную способность и горизонтальную масштабируемость. Например, распараллеленный переход от Spark DataFrame к таблице Kudu является однострочной командой: upsertRows (sparkDataFrame, kuduTableName).
10 особенностей интеграции Apache Spark с Kudu
При практическом использовании Kudu совместно с Apache Spark стоит помнить про следующие ограничения интеграции этих Big Data технологий, которые могут расцениваться как недостатки [2]:
- Spark 2.2 (и выше) требует Java 8 во время выполнения, хотя интеграция Kudu Spark 2.x совместима с Java 7. Версия 2.2 по умолчанию интегрирована с версией Kudu 1.5.0.
- Kudu-таблицам, имена которых содержат символы верхнего регистра или НЕ ASCII-символы, следует присвоить альтернативное имя при регистрации в качестве временной таблицы. Аналогичное требование выдвигается к Kudu-таблицам с именем столбца, который содержит символы верхнего регистра или НЕ ASCII-символы. По умолчанию они не должны использоваться в Spark SQL. Чтобы обойти это ограничение, столбцы можно переименовать в Kudu.
- <> и OR-предикаты не отправляются в Kudu, а оцениваются заданием Спарк. В Куду передаются только предикаты LIKE с подстановочным суффиксом %. Например, LIKE «FOO%» будет передан, а LIKE «FOO% BAR» – нет.
- Куду не поддерживает все типы данные, доступные в Spark SQL, такие как, дата и другие сложные типы.
- Куду-таблицы могут быть зарегистрированы только как временные таблицы Spark SQL.
- К Kudu-таблицам нельзя обратиться через HiveContext — расширенный набор SQLContext, дополнительные функции которого включают возможность писать запросы с использованием более полного анализатора HiveQL, доступ к пользовательским функциям Hive и возможность чтения данных из таблиц Hive [3].
Также необходимо иметь ввиду следующие особенности совместного использования Kudu с Apache Spark:
- Куду весьма требователен к качеству данных, поэтому любые некачественные данные, скорей всего, НЕ будут обработаны. Это значит, что их нужно записывать в другом месте и обрабатывать отдельно [1].
- Поскольку Куду является строго колоночным хранилищем, ему нужны четко структурированные и типизированные данные без JSON, AVRO и прочих неструктурированных текстовых форматов. Кроме того, в настоящее время поддерживается не более 300 столбцов на таблицу [1].
- рекомендуется избегать нескольких клиентов Куду на кластер и создания дополнительных объектов KuduClient. Код приложения Spark не должен создавать другой объект KuduClient, который подключается к тому же кластеру. Вместо этого Спарк-приложению стоит использовать KuduContext для доступа к KuduClient с использованием KuduContext # syncClient. Для диагностики нескольких экземпляров KuduClient в задании Spark, следует поискать признаки в журналах мастера, перегруженных запросами GetTableLocations или GetTabletLocations, поступающими от разных клиентов, обычно примерно в одно и то же время. Это наиболее вероятно в коде Spark Streaming, где создание KuduClient для каждой задачи приведет к периодическим волнам мастер-запросов от новых клиентов [4].
- интеграция Kudu-Spark может работать на защищенных кластерах Куду, для которых включена аутентификация и шифрование. При этом отправитель задания Спарк должен предоставить соответствующие учетные данные. Для заданий Spark, использующих по умолчанию режим развертывания «клиент», отправляющий пользователь должен иметь активный ticket безопасного протокола Kerberos, предоставленный через kinit. Для заданий Спарк, использующих режим развертывания «кластер», имя участника Kerberos и расположение таблицы ключей должны быть предоставлены с помощью аргументов —principal и —keytab для spark2-submit [2].
О других особенностях интеграции Apach Spark с Kudu читайте в нашей новой статье. А завтра мы рассмотрим несколько практических примеров использования Куду в реальных Big Data проектах, включая современную BI-аналитику больших данных. Еще больше подробностей про работу с большими данными с помощью Apache Spark, Kudu и других компонентов экосистемы Hadoop в проектах цифровизации своего бизнеса вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Анализ данных с Apache Spark
- Cloudera Impala Data Analytics
- Hadoop для инженеров данных
- Интеграция Hadoop и NoSQL
- Безопасность озера данных Hadoop
Источники
- https://cazena.com/streaming-data-analytics-kafka-spark-kudu-tutorial/
- https://docs.cloudera.com/runtime/7.2.0/kudu-development/topics/kudu-spark-integration-known-issues/
- http://www.openkb.info/2016/02/difference-between-spark-hivecontext/
- https://docs.cloudera.com/runtime/7.2.0/kudu-development/topics/kudu-spark-integration-best-practices/

