 1155
1155 
Продолжая разговор про форматы Big Data файлов, сегодня мы рассмотрим разницу между линейными и колоночными типами, а также расскажем о том, как выбирать между AVRO, Sequence, Parquet, ORC и RCFile при работе с Apache Hadoop, Kafka, Spark, Flume, Hive, Drill, Druid и других средствах работы с большими данными. Итак, форматы файлов Big Data – все, что нужно для начинающего Data Engineer’а – читайте в нашей статье.
2 типа форматов для Big Data файлов
Все многообразие файловых форматов Big Data (AVRO, Sequence, Parquet, ORC, RCFile) можно разделить на 2 категории: линейные (строковые) и колоночные (столбцовые).
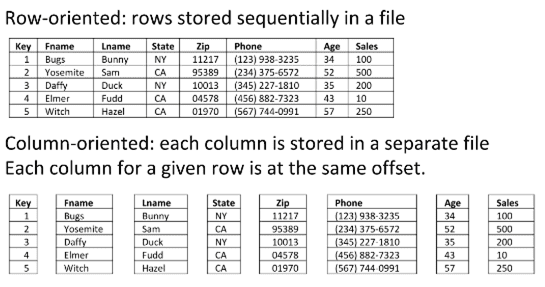
В линейных форматах (AVRO, Sequence) строки данных одного типа хранятся вместе, образуя непрерывное хранилище. Даже если необходимо получить лишь некоторые значения из строки, все равно вся строка будет считана с диска в память. Линейный способ хранения данных обусловливает пониженную скорость операций чтения и выполнении избирательных запросов, а также больший расход дискового пространства [1]. Линейные форматы, в отличие от колоночных, не являются строго типизированными: например, Apache AVRO хранит информация о типе каждого поля в разделе метаданных вместе со схемой, поэтому для чтения сериализованных данных информации не требуется предварительное знание схемы [2]. Бинарный формат файлов последовательностей (Sequence File) для хранения Big Data в виде сериализованных пар ключ/значение в экосистеме Apache Hadoop также содержит метаданные в заголовке файла. Отметим, что формат Sequence File отлично обеспечивает параллелизм при выполнении задач MapReduce, т.к. разные порции одного файла могут быть распакованы и использованы независимо друг от друга. Тем не менее, степень сжатия информации у строковых форматов ниже, чем у столбцовых [3]. Однако, именно линейно-ориентированные форматы лучше всего подходят для потоковой записи, т.к. в случае сбоя информация может быть восстановлена (повторно синхронизирована) с последней точки синхронизации [1].

В колоночно-ориентированных форматах (Parquet, RCFile, ORCFile) файл разрезается на несколько столбцов данных, которые хранятся вместе, но могут быть обработаны независимо друг от друга. Такой метод хранения информации позволяет пропускать ненужные столбцы при чтении данных, что существенно ускоряет чтение данных и отлично подходит в случае, когда необходим небольшой объем строк или выполняются избирательные запросы, как, например, в СУБД Apache Hive. Но такой формат чтения и записи занимает больше места в оперативной памяти, поскольку, чтобы получить столбец из нескольких строк, кэшируется каждая строка. Также колоночно-ориентированные форматы не используются в средах потоковой обработки (Apache Kafka, Flume), т.к. после сбоя записи текущий файл не сможет быть восстановлен из-за отсутствия точек синхронизации. Однако, колоночные файлы занимают меньше места на жестком диске вследствие более эффективного сжатия информации по столбцам [1].

Какой формат файла выбрать для больших данных
Итак, вышеописанные архитектурные различия колоночных и линейных форматов Big Data файлов обусловливают их разную эффективность при хранении, чтении и записи информации. Поэтому примитивное сравнение скорости обработки информации в том или ином формате относительно других не совсем корректно, т.к. оцениваются не только и не столько форматы, сколько алгоритмическое качество использующих их прикладных систем. Отметим, что каждый поставщик Big Data продукта, прежде всего, стремится продвигать свои собственные форматы данных и те, которые больше всего подходят для использования с его решением, например, сертификационный экзамен Data Engineer по дистрибутиву Apache Hadoop от компании Cloudera (CHD, Cloudera’s Distribution of Hadoop) включает темы по Parquet, тогда как аналогичная сертификация по Hortonworks Data Platform больше уделяет внимания формату ORC [4]. Также Parquet широко используется в Apache Impala, Drill и Big Data платформе MAPR. А у разработчика коммерческой версии Apache Kafka, корпорация Confluent, в приоритете формат AVRO [5].
Таким образом, при выборе формата данных, следует, прежде всего, иметь ввиду практические задачи, которые необходимо решить с его помощью в рамках функциональных возможностей конкретной Big Data системы [6]. К примеру, линейный формат AVRO обеспечивает высокую скорость записи информации, и потому отлично подходит обработки потоков Big Data в Apache Kafka, Flume и корпоративных озерах данных (Data Lake), а также хорошо решает задачи полного чтения всех полей записи, что требуется в ETL-хранилищах и витрин данных.
В свою очередь, колочно-ориентированные форматы (Parquet, RCFile, ORCFile) быстрее считывают данные из файла за счет пропуска ненужных столбцов и занимают меньше места на диске. Поэтому колоночные форматы активно применяются в файловых хранилищах и СУБД на основе Apache Hadoop, в частности, Hive. В контексте применения SQL-запросов стоит отметить некоторые ключевые особенности формата ORC по сравнению с другими столбцовыми файлами:
- индексация блоков каждого столбца, что ускоряет операции ввода-вывода;
- считывание метаданных на уровне столбца позволяет оптимизировать SQL-запросы;
- поддержкаACID-требований к транзакциям (Atomicity — Атомарность, Consistency — Согласованность, Isolation — Изолированность, Durability — Долговечность);
- более высокая степень сжатия файлов экономит место на жестком диске [7].
А к уникальным преимуществам формата Apache AVRO относится человекочитаемый формат JSON, обеспечение совместимости и поддержка эволюции схем данных, когда изменения обрабатываются путем пропуска, добавления или модификации отдельных полей [2].

Итак, сравнительное описание наиболее распространенных файловых форматов Big Data, в очередной раз подтверждает, что наилучший эффект дает применение именно того инструмента, который ориентирован на конкретную задачу. Например, Apache Spark поддерживает все вышеперечисленные форматы данных (AVRO, Sequence, Parquet, ORC, RCFile), но наиболее оптимально работает с колоночными файлами в режиме онлайн-аналитики и со строковыми при обработке информационных потоков.
Какой формат выбрать для своего Big Data проекта и как с ним работать, узнайте на наших практических курсах по большим данным для руководителей, архитекторов, инженеров, администраторов, аналитиков и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- HDDE: Hadoop для инженеров данных
- KAFKA: Администрирование кластера Kafka
- SPARK: Администратор кластера Apache Spark
- DEVKI: Apache Kafka для инженеров данных
Источники
- https://habr.com/ru/company/otus/blog/465069/
- https://ru.bmstu.wiki/Apache_Avro
- http://datareview.info/article/test-proizvoditelnosti-apache-parquet-protiv-apache-avro/
- http://www.thecloudavenue.com/2016/10/comparing-orc-vs-parquet-data-storage/
- https://www.datanami.com/2018/05/16/big-data-file-formats-demystified/
- https://habr.com/ru/company/alfastrah/blog/458552/
- https://community.cloudera.com/t5/Support-Questions/ORC-vs-Parquet-When-to-use-one-over-the-other/td-p/95942

