 633
633 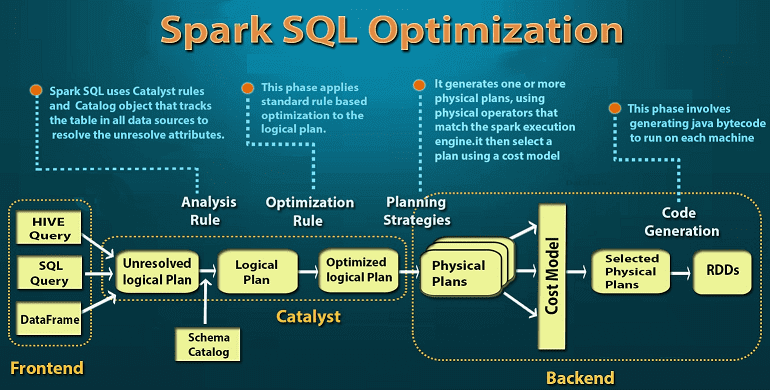
Содержание
Завершая тему SQL-оптимизации в Big Data на примере Apache Spark, сегодня мы подробнее расскажем, какие действия выполняются на каждом этапе преобразования дерева запросов в исполняемый код. А рассмотрим, за счет чего так эффективна автоматическая кодогенерация в Catalyst. Читайте в нашей статье про планы выполнения запросов, квазиквоты Scala и операции с абстрактными синтаксическими деревьями.
Как Catalyst преобразует SQL-запросы в исполняемый код
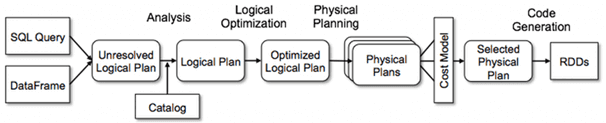
Весь процесс оптимизации SQL-запросов в рамках Catalyst состоит из 4-х этапов [1]:
- анализ, когда вычисляются отношения из абстрактного синтаксического дерева, возвращаемого синтаксическим анализатором SQL, либо из объекта DataFrame, созданного с использованием API.
- логическая оптимизация, когда типовые правила применяются к логическому плану: свертка (constant folding), предикатное сжатие (predicate pushdown), сокращение проекций (projection pruning) и другие правила. Catalyst позволяет добавлять свои правила для различных ситуаций.
- физическая оптимизация, когда один или несколько физических планов формируются из логического с использованием физического оператора, соответствующего движку Apache Spark. Итоговый план выбирается на основе стоимостной модели (CBO, Cost-based optimization). CBO позволяет оценить стоимость рекурсивно для всего дерева с помощью правил. Физическая оптимизация на основе правил (RBO, Rule-based Optimization), такая как конвейерные проекции или map-фильтры в Spark также выполняется физическим планировщиком. Помимо этого, он может передавать операции из логического плана в источники данных, которые поддерживают сжатие предикатов или проекций (Predicate Pushdown и Projection Pushdown), о которых мы рассказываем здесь.
- Кодогенерация, когда создается байт-код Java для запуска на каждом узле кластера. Отметим, что Spark SQL часто работает с наборами данных в памяти, когда обработка зависит от процессора, поэтому кодогенерация влияет общую скорость выполнения [2]. Catalyst использует специальную особенность языка Scala, квазиквоты (Quasiquotes), чтобы упростить генерацию кода, потому что очень сложно создавать механизмы генерации кода. Квазиквоты позволяют программно создавать абстрактные синтаксические деревья на языке Scala, которые затем могут быть переданы компилятору Scala во время выполнения для генерации байт-кода. С помощью Catalyst можно преобразовать дерево, представляющее выражение в SQL, в код абстрактного синтаксического дерева для Scala, чтобы оценить это выражение, а затем скомпилировать и запустить сгенерированный код.
Особенности этапов анализа и кодогенерации при SQL-оптимизации в Apache Spark
Рассмотрим этап анализа чуть подробнее, ведь именно на этом шаге абстрактное синтаксическое дерево запросов начинает преобразоваться в логический план. Напомним, в абстрактном синтаксическом дереве (AST, Abstract Syntax Tree) внутренние вершины сопоставлены (помечены) с операторами языка программирования, а листья — с соответствующими операндами. Листья являются пустыми операторами и представляют только переменные и константы. Синтаксические деревья используются в парсерах для промежуточного представления программы между деревом разбора (конкретным синтаксическим деревом) и структурой данных, которая затем используется в качестве внутреннего представления в компиляторе или интерпретаторе для оптимизации и генерации программного кода. Возможные варианты подобных структур описываются абстрактным синтаксисом [3].
В Spark SQL абстрактные синтаксические деревья могут содержать неразрешенные атрибутные ссылки или отношения, когда неизвестен тип атрибута или он не сопоставлен с входной таблицей. Для определения таких атрибутов в Spark SQL используются правила Catalyst и объект Catalog, которые отслеживают данные во всех источниках. После создания неразрешенного логического плана выполняются следующие действия:
- поиск имени отношения из каталога (Catalog);
- сопоставление атрибутов имени, например, столбца, со входом – дочерними элементами данного оператора;
- определение, какие атрибуты соответствуют одному и тому же значению, чтобы дать им уникальный идентификатор;
- типизация атрибута с помощью регулярных выражений.
Дальнейший процесс преобразования плана запросов в исполняемый код был описан выше.
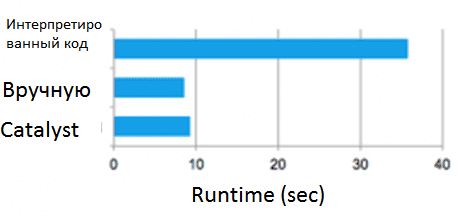
Отметим также некоторые особенности фазы кодогенерации. В частности, квазиквоты обеспечивают проверку типов во время компиляции, гарантируя, что в них подставляются только соответствующие AST или литералы. Благодаря этому квазиквоты Scala более полезны, чем конкатенация строк, что позволяет работать непосредственно к AST вместо запуска анализатора Scala во время выполнения. Более того, они легко компонуются, поскольку правилу генерации кода для каждого узла дерева не нужно знать, как создаются деревья, возвращаемые его дочерними элементами. Наконец, результирующий код дополнительно оптимизируется компилятором Scala на случай редких ситуаций, когда Catalyst пропустил какие-либо оптимизации на уровне выражений. Из-за этого квазиквоты позволяют генерировать код с высокой производительностью, аналогичной настроенным вручную программам. Более того, благодаря простоте использования квазиквот, работать с ними могут даже новички в Spark SQL, чтобы быстро добавлять правила для новых типов выражений. Квазиквоты также хорошо запускаются на нативных объектах Java: при доступе к полям из них можно сгенерировать код для прямого доступа к требуемому полю, вместо того, чтобы копировать объект в строку SQL Spark и использовать строку методы доступа. Наконец, можно объединить сгенерированную кодом оценку с интерпретированной оценкой для выражений, для которых еще не сгенерирован программный код, поскольку компилируемый код Scala может напрямую вызывать интерпретатор выражений [2].
Таким образом, SQL-оптимизация в Apache Spark повышает производительность разработчиков Big Data и производительность написанных ими запросов. Catalyst автоматически переписывает реляционные запросы для более эффективного выполнения, используя предварительную фильтрацию данных, утилизацию доступных индексов и даже объединение разных источников данных в наиболее эффективном порядке. Выполняя эти преобразования, оптимизатор сокращает время выполнения реляционных запросов, позволяя программисту сосредоточиться на семантике своего Big Data приложения, а не на его производительности. Для этого Catalyst использует мощные функции Scala, такие как сопоставление с образцом и метапрограммирование во время выполнения, позволяя разработчику кратко определять сложные реляционные оптимизации [1].
Станьте профессионалом в интерактивной аналитике больших данных, освоив практический курс SPARK2:Анализ данных с Apache Spark в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.
Источники

