 1295
1295 
Содержание
Сегодня мы рассмотрим Apache Hive и Cloudera Impala – аналитические SQL-средства для работы с данными, хранящимися в экосистеме Apache Hadoop и других Big Data хранилищах: HDFS, HBase, Amazon S3. Читайте в нашей статье, что такое Hive и Impala, где они используются и почему они не заменяют, а дополняют друг друга.
Apache Hive и Cloudera Impala: что это и как используется в SQL для Big Data
Прежде всего отметим, что Hive и Impala не конкурируют, а, скорее эффективно дополняют друг друга. Между этими системами довольно много общего, но есть некоторые различия [1]. Прежде всего, отметим их основное назначение и некоторые аспекты, особенно важные для практического использования.
Обе рассматриваемые платформы свободно распространяются под лицензией Apache Software Foundation и относятся к SQL-средствам работы с данными, хранящимися в кластере Hadoop. Помимо распределенной файловой системы Apache Hadoop, HDFS, Hive и Импала обеспечивают интерактивные SQL-запросы к данным, хранящимся в HBase или Amazon Simple Storage Service (S3).
Как правило, Hive используется инженерами данных (Data Engineer) в ETL-процессах (Extract, Transform, Load), например, для длительных пакетных заданий на больших наборах данных, в частности, веб-журналах. В этом случае ключевыми преимуществами Hive являются его масштабируемость (расширяется динамически при добавлении машины к кластеру Hadoop), расширяемость за счет MapReduce и определяемых пользователем функций (UDF/UDAF/UDTF), отказоустойчивость и способность работать с различными форматами входных данных (TEXTFILE, Sequence, ORC и RCFILE, а также Parquet с помощью специального плагина в версиях позже 0.10). При этом Hive не поддерживает интерактивное выполнение запросов в режиме реального времени, а потому не может использоваться в OLTP-задачах [2].
В свою очередь, Cloudera Impala, предназначенная, главным образом, для аналитиков и ученых по данным (Data Analyst, Data Scientist), представляет собой открытую базу данных для Apache Hadoop. Импала обеспечивает быстрые интерактивные SQL-запросы с низкой временной задержкой (low latency) на лету. В отличие от Hive, где поддерживается вычислительная модель MapReduce, Impala основана на массивно-параллельной архитектуре (MPP, Massively Parallel Processing). MPP активно используется в других аналитических СУБД стека Big Data (Greenplum Database, Arenadata DB, Teradata и др.). Импала работает со многими форматами данных (LZO, Avro, RCFile, Parquet), реализуя распределенные SQL-запросы в кластерной среде, что обусловливает ее высокую скорость работы по сравнению с Хайв [3]. Подробнее про сходства и различия Apache Hive и Impala мы расскажем в следующей статье, а сейчас рассмотрим несколько практических примеров эффективного сочетания этих двух SQL-инструментов в разных Big Data проектах.
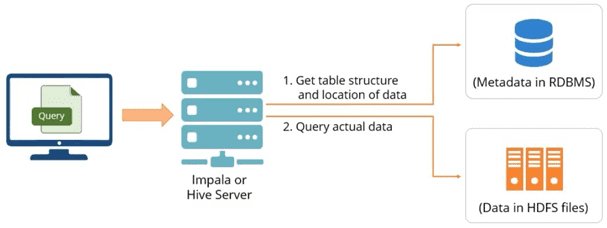
Как Impala работает с Hive: несколько реальных кейсов
Как мы уже отметили выше, Impala и Hive реализуют разные задачи при общей нацеленности на SQL-обработку больших данных, хранящихся в кластере Apache Hadoop. Impala предоставляет SQL-подобный интерфейс, позволяя читать и записывать таблицы Hive, обеспечивая таким образом простой обмен данными [3]. При этом Импала делает SQL-операции на Hadoop достаточно быстрыми и эффективными, что позволяет использовать эту СУБД в исследовательских проектах по Big Data аналитике. По возможности Cloudera Impala работает с уже существующей инфраструктурой Apache Hive, которая уже используется для выполнения длительных пакетных SQL-запросов. В частности, Impala хранит свои определения таблиц в метахранилище – традиционной базе данных MySQL или PostgreSQL, т.е. там же, где Хайв хранит аналогичные данные. Благодаря этому Impala может обращаться к Hive-таблицам, при условии, что все столбцы используют поддерживаемые Импала типы данных, форматы файлов и кодеки сжатия. Отметим, что Импала в большей степени ориентирована на чтение, позволяя читать больше типов данных с помощью инструкции SELECT, чем писать с помощью INSERT. Для запроса данных в форматах AVRO, RCFile или Sequence Impala использует Hive [4].
Благодаря высокой скорости выполнения SQL-запросов Impala используется в тех бизнес-приложениях, где необходима интерактивная аналитика Big Data в режиме онлайн. В частности, в задачах Business Intelligence (BI) при таких аналитических запросах в Hadoop, которые не поддерживаются пакетными средами, т. е. Хайв, требуя низкой временной задержки и высокого параллелизма [5]. Один из практических примеров использования Apache Hive с Cloudera Impala с – это тревел-агрегаторы и информационные системы аэропортов, которые предоставляют информацию о задержках рейсов, причинах задержек рейсов, времени в различных форматах, сведениях об источниках и пунктах назначения, включая перенаправленные маршруты. Отметим, что в этом бизнес-кейсе новые данные появляются постоянно и имеют большой размер и увеличиваются. Инструменты визуализации должны извлекать данные в режиме реального времени, а наглядные графики и диаграммы должны быстро обновляться. Импала быстро, в режиме реального времени (за считанные секунды) обрабатывает сложные SQL-запросы, повышая производительность повторной обработки данных за счет кэширования результатов в памяти [6]. А Хайв обеспечивает надежное выполнение ETL-процессов, реализуя отказоустойчивый обмен пакетами Big Data между различными распределенными файловыми системами и базами данных, преобразуя SQL-запросы в задания Apache Spark или Hadoop.
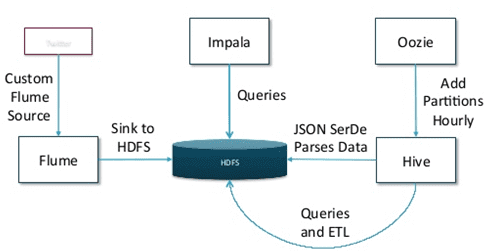
Аналогичным образом сочетание Apache Hive и Cloudera Impala может использоваться для маркетинговой аналитики, когда потоковые данные о пользовательском поведении стекаются в HDFS с помощью Apache Flume. Далее в рамках Impala выполняются интерактивные SQL-запросы, а Hive предоставляет SQL-подобный интерфейс для создания заданий MapReduce для доступа к данным. Для автоматического запуска и управления всеми рабочими процессами используется Apache Oozie. Таким образом, на базе SQL-инструменты с открытым исходным кодом в экосистеме Hadoop, можно создать полную аналитическую линию Twitter для эффективного поиска, хранения и запросов сообщений [7].
В следующей статье мы подробнее расскажем о ключевых сходствах и различиях Apache Hive и Cloudera Impala. А чем Импала отличается от Apache Drill, мы рассматриваем здесь.
Все тонкости аналитики больших данных с помощью этих SQL-инструментов вы освоите на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://data-flair.training/blog/impala-vs-hive/
- https://ru.bmstu.wiki/Apache_Hive
- https://ru.bmstu.wiki/Apache_Impala
- https://impala.apache.org/docs/build/html/topics/impala_hadoop/
- https://data-flair.training/blog/impala-use-cases/
- https://www.dezyre.com/hadoop-tutorial/impala-case-study-flight-data-analysis
- http://www.datacommunitydc.org/blog/2013/05/event-review-analyzing-twitter-an-end-to-end-data-pipeline-recap

