
В уроке 30 разобрали MirrorMaker 2 - инструмент для репликации топиков между кластерами. Там мы мельком упоминали, что MM2 построен поверх Kafka Connect. Теперь пришло время разобраться с самим фреймворком. Kafka Connect - это слой интеграции, который берёт на себя всю рутину переноса данных между Kafka и внешними системами....

В уроке 29 мы разобрали kafka-consumer-perf-test.sh — как измерить скорость чтения, интерпретировать вывод и подбирать параметры консьюмера. Получили полную картину: есть цифры продюсера, есть цифры консьюмера, узкое место теперь видно. Следующий логичный вопрос: а что делать, если кластеров несколько? DR-окружение, географически распределённые датацентры, изоляция окружений prod и staging —...
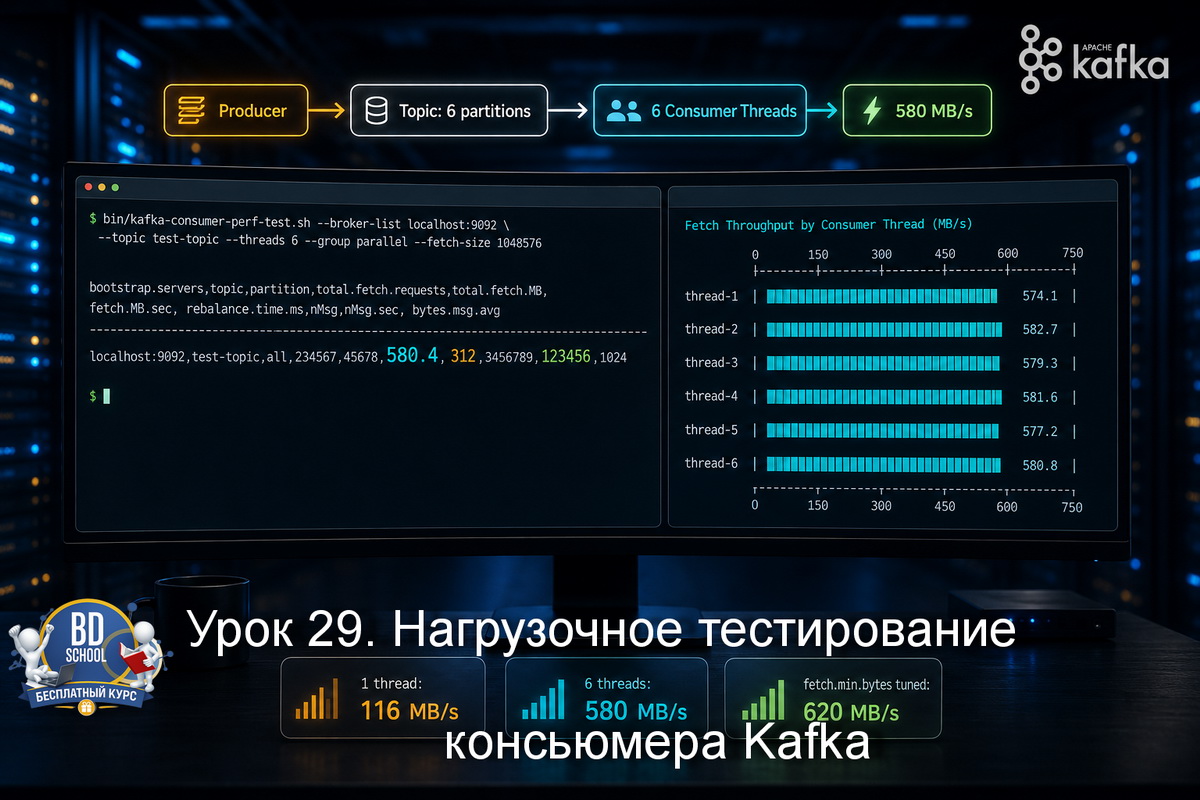
В уроке 28 мы разобрали kafka-producer-perf-test.sh: как гнать синтетическую нагрузку в топик, читать перцентили латентности и подбирать параметры продюсера. Получили цифры на стороне записи. Но у любого потока данных есть вторая сторона - чтение. И там своя картина. Узкое место системы не всегда продюсер. Часто потребитель не успевает за входящим...
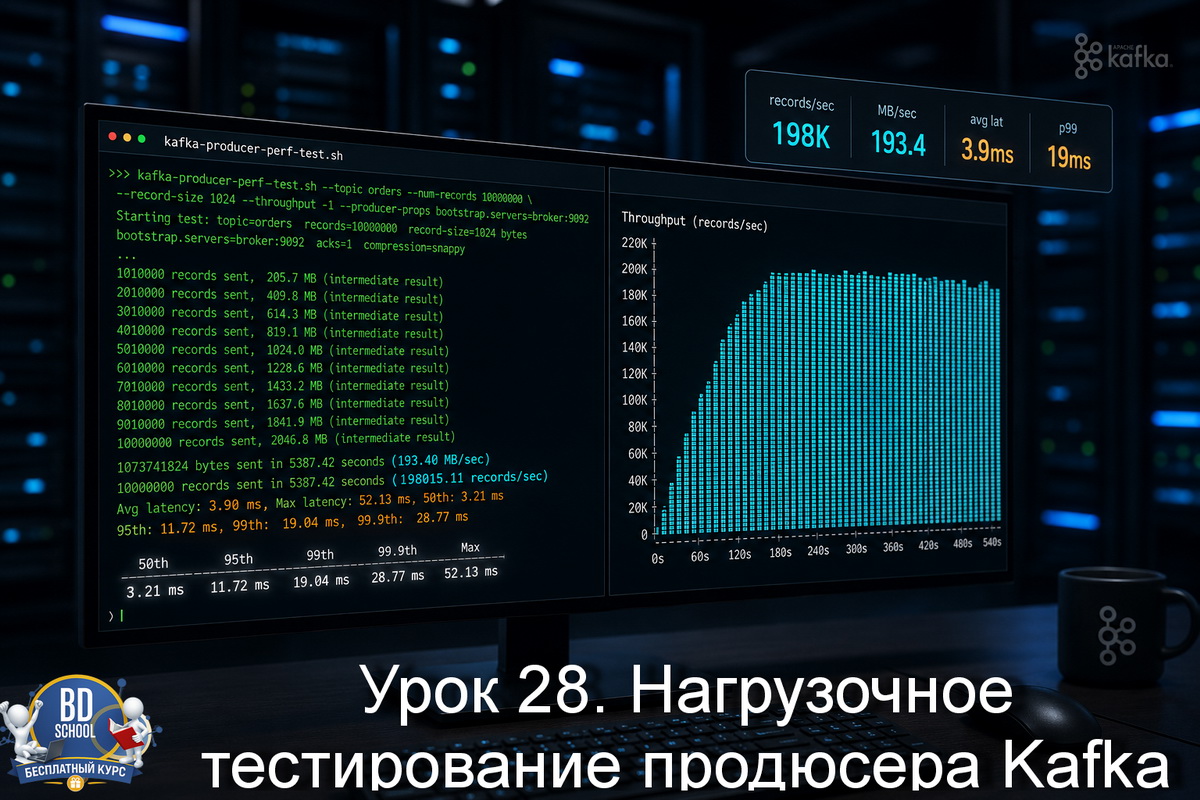
В уроке 27 мы разбирали kafka-verifiable-producer.sh и kafka-verifiable-consumer.sh - утилиты, которые показывают каждое отправленное и полученное сообщение в виде JSON. Они хороши для отладки: видно, что именно ушло, какой офсет получили, есть ли потери. Но если нужно понять не "что" отправляется, а "как быстро" и "с какой задержкой" -...

В уроке 26 мы работали с kafka-get-offsets.sh и разбирались, как читать офсеты топиков: где сейчас начало лога, где конец, сколько сообщений накопилось на каждой партиции. Офсеты дают общую картину, но не отвечают на вопрос, работает ли кластер так, как ожидается, когда по нему идёт реальный поток данных. Именно для...

В уроке 25 мы разбирались с kafka-broker-api-versions.sh - смотрели, какие версии протокола поддерживает брокер, и учились диагностировать ошибки UNSUPPORTED_VERSION при rolling upgrade. Там речь шла о низкоуровневой совместимости на уровне API. Сегодня спускаемся на уровень ниже - не к протоколу, а к данным. Конкретно к офсетам. Любой, кто разбирается...

В уроке 24 мы разбирали kafka-acls.sh и работу со списками доступа: кто из клиентов что может делать с топиками, группами, кластером. Там же всплыл важный момент - аутентификация через SASL и флаг --command-config. Прежде чем клиент получит право что-то делать, он должен вообще договориться с брокером на уровне протокола....
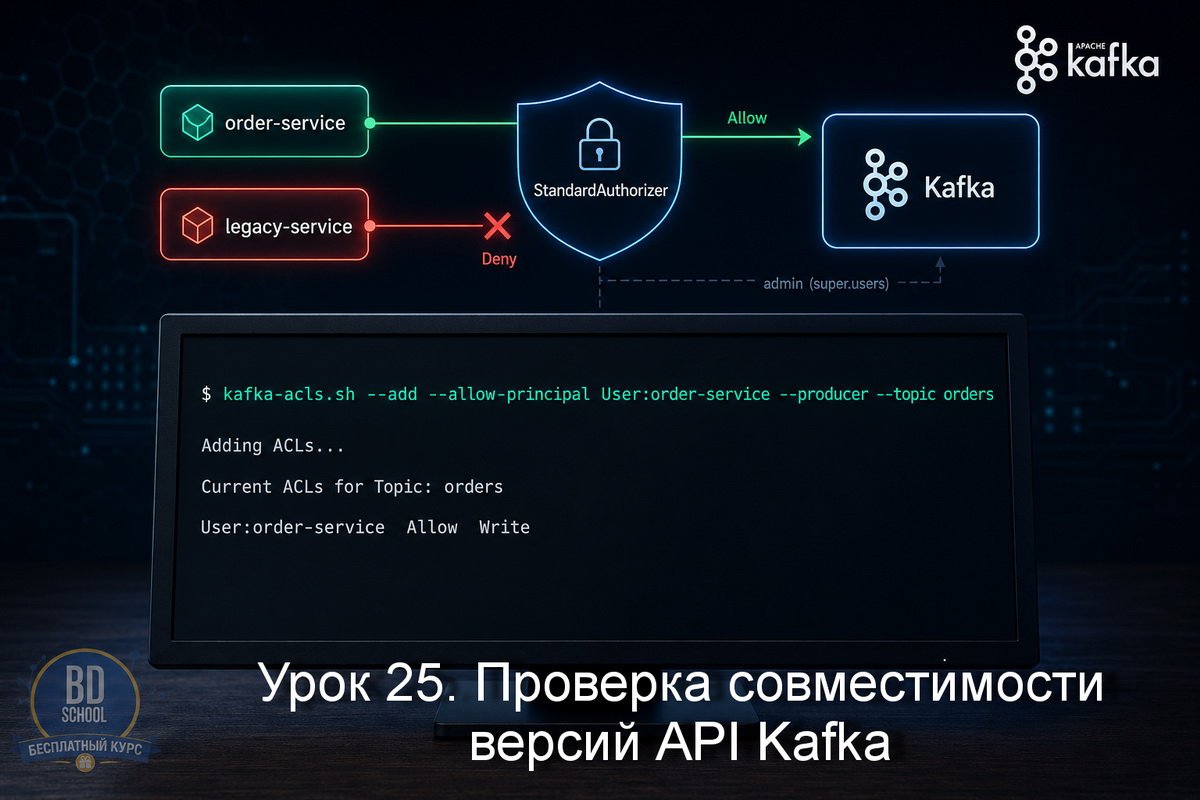
В уроке 23 мы разобрали kafka-replica-verification.sh - инструмент, который подключается к каждому брокеру напрямую и сравнивает смещения реплик. Там же мы отметили важную особенность: утилита общается с брокерами через Fetch API без каких-либо ограничений доступа. В реальном кластере это уже вопрос: а кто вообще имеет право подключаться? В production-окружениях...

В уроке 22 мы разобрались с kafka-reassign-partitions.sh: генерировали план переноса партиций, запускали его с троттлингом и проверяли статус через --verify. После того как переназначение завершилось - данные физически переехали, реплики поднялись на новых брокерах. Но как убедиться, что данные во всех репликах одинаковые? Что ни одна реплика не отстала...

В уроке 21 мы разбирали kafka-leader-election.sh - инструмент для управления лидерами партиций после сбоев и перезапусков брокеров. Там вопрос стоял просто: вернуть лидерство туда, где оно должно быть по конфигурации. Сегодня задача масштабнее - физически переместить партиции между брокерами. Это нужно при добавлении нового брокера в кластер, выводе старого...
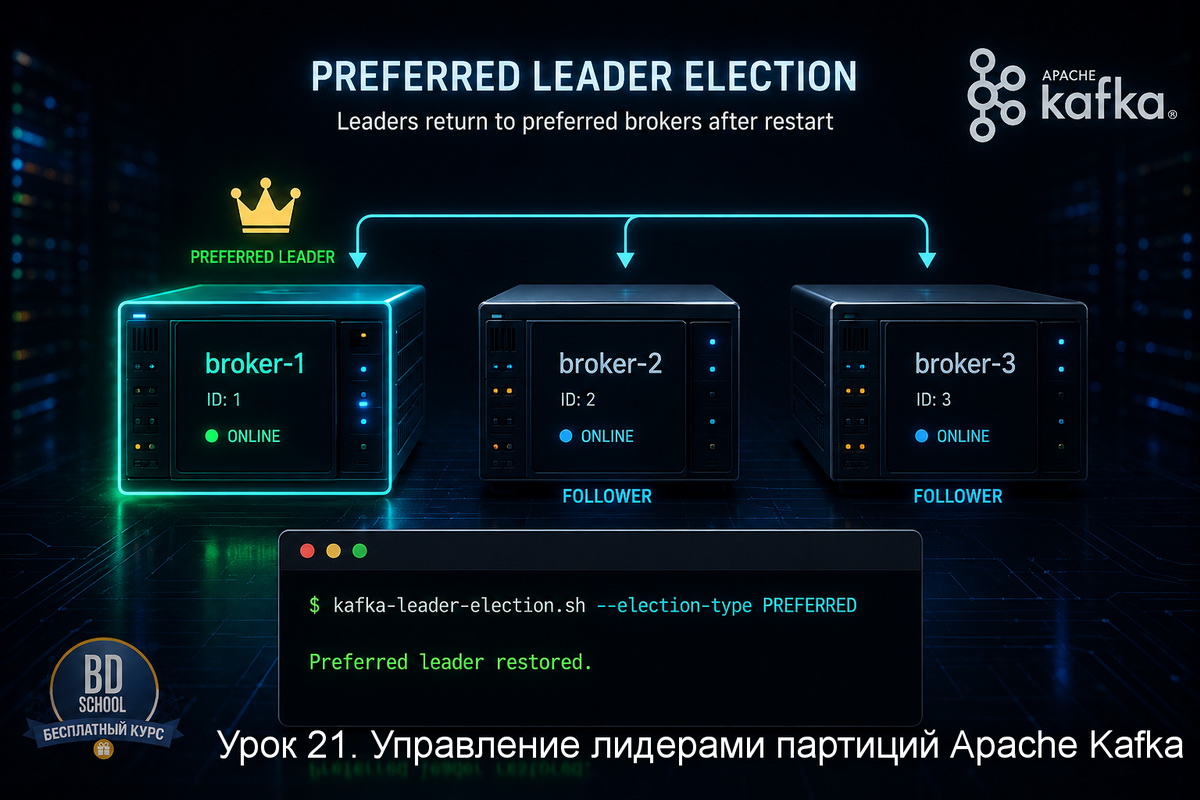
В уроке 20 мы разбирали kafka-streams-application-reset.sh - инструмент для сброса состояния Kafka Streams приложений. Там речь шла о внутренних топиках, changelog-топиках и локальных state store. Сегодня переключаемся на другую задачу - управление лидерами партиций. kafka-leader-election.sh нужна когда лидер партиции после сбоя или перезапуска брокера оказался не там, где должен...

В уроке 19 мы разобрали kafka-consumer-groups.sh - утилиту для работы с группами консьюмеров: просмотр lag-а, сброс офсетов, удаление групп. Там же обсуждали, как Kafka хранит офсеты в топике __consumer_offsets. Сегодня идём дальше. kafka-streams-application-reset.sh - это специализированный инструмент для приложений на Kafka Streams. У стримингового приложения состояние устроено значительно сложнее,...
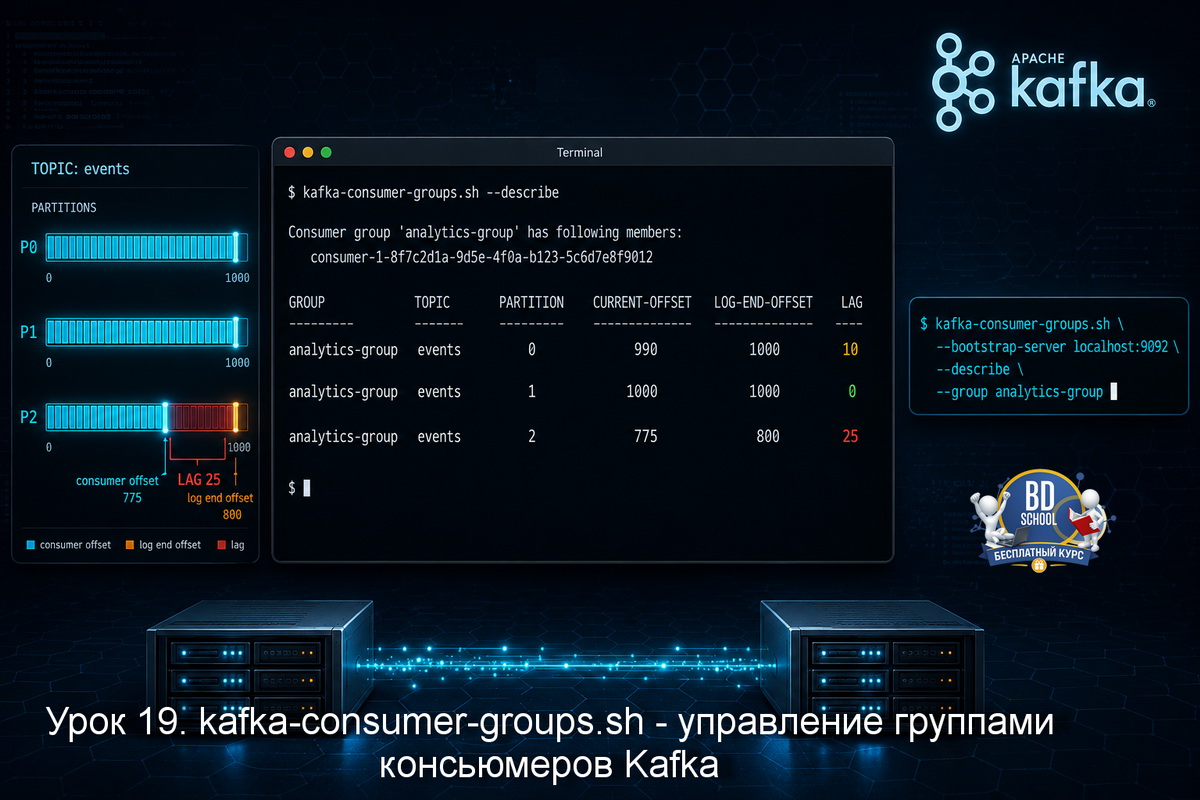
В уроке 18 мы разобрали kafka-delete-records.sh - смещали нижнюю границу лога, делая ненужные записи недоступными для консьюмеров. Там уже мелькало понятие consumer group offset: Kafka запоминает, до какого сообщения дочитала каждая группа, и именно это позволяет консьюмерам продолжать с нужного места. Сегодня разбираем утилиту, которая управляет этим механизмом напрямую....

В уроке 17 мы разобрали kafka-dump-log.sh - читали бинарные лог-сегменты прямо с диска, смотрели содержимое батчей, проверяли офсеты и метаданные продюсеров. Это диагностический инструмент: он ничего не меняет, только показывает. Сегодня переходим к другой задаче. Иногда данные нужно не просмотреть, а удалить - конкретные сообщения в конкретных партициях. Причины...
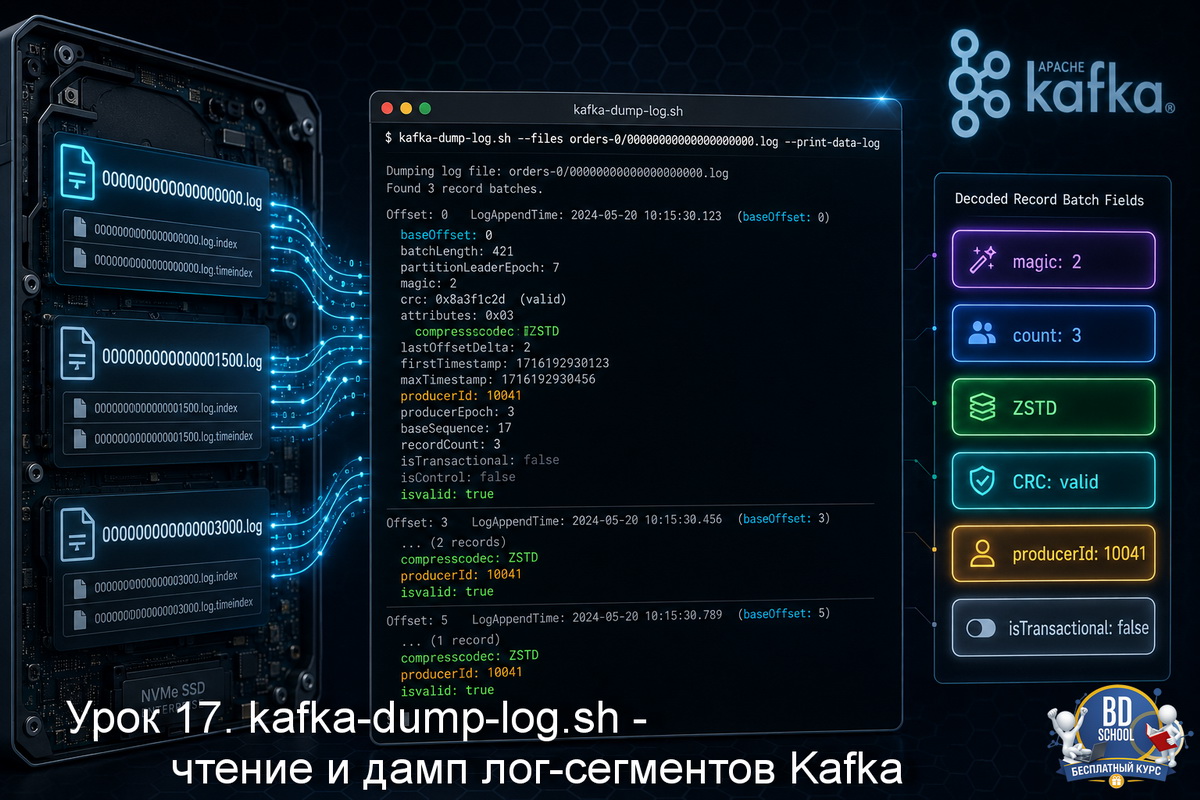
В уроке 16 мы использовали kafka-log-dirs.sh, чтобы узнать, сколько места занимают партиции и в каких директориях они лежат. Утилита работает через API брокера и возвращает агрегированные метаданные. Это удобно, но иногда нужно копнуть глубже - посмотреть прямо в файл и понять, что именно там лежит. kafka-dump-log.sh делает именно это....

В уроке 15 мы разобрали kafka-configs.sh - утилиту для управления динамическими конфигурациями топиков, брокеров и квот. Там мы меняли retention.ms, max.message.bytes и другие параметры без перезапуска кластера. Но одно дело выставить срок хранения, другое - понять, сколько места реально занимают данные прямо сейчас. Именно тут нужна kafka-log-dirs.sh. Она показывает,...

В уроке 14 мы разобрали kafka-features.sh - утилиту для управления feature-флагами кластера и версией метаданных KRaft. Там же стало понятно, что Kafka хранит в метаданных не только версии функций, но и переопределённые конфигурации топиков и брокеров. Посмотреть эти конфигурации в режиме read-only можно через kafka-metadata-shell.sh из урока 13 -...

В уроке 13 мы разбирались с kafka-metadata-shell.sh - интерактивным шеллом для чтения содержимого KRaft-метаданных. Если вы там заходили в директорию /features/ и видели там metadata.version с каким-то числом - это как раз то, чем управляет утилита сегодняшнего урока. kafka-features.sh отвечает за управление feature-флагами кластера. Звучит абстрактно, но на практике...

В уроке 12 мы разобрали kafka-metadata-quorum.sh - как смотреть состояние кворума KRaft, кто сейчас лидер контроллера и насколько отстают фолловеры. Это взгляд на кворум снаружи: числа, статусы, смещения. Но иногда нужно заглянуть внутрь - буквально открыть метаданные кластера и посмотреть, что там хранится. Для этого в Apache Kafka есть...

В уроке 11 мы разобрали kafka-cluster.sh - как получить cluster ID от работающего брокера и как корректно вывести брокер из KRaft-кластера через команду unregister. После вывода брокера логично проверить, что кворум не пострадал и кластер продолжает работать нормально. Именно для этого существует утилита следующего урока. kafka-metadata-quorum.sh - инструмент для...