 1000
1000 
Содержание
В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене и построение наглядных BI-дэшбордов.
CDC как технология интеграции самообслуживаемых микросервисов
Рассмотрим пример построения самообслуживаемых (Self-service) аналитических приложений с использованием CDC-подхода вместо непосредственной интеграции с оперативными хранилищами данных. Этот кейс становится актуальным по мере роста бизнеса, который провоцирует увеличение сложности и количества информационных систем. Ускорить процессы разработки и добавления новых функций можно через децентрализацию контроля над инфраструктурой и архитектурами приложений, чтобы самообслуживаемые команды тратили меньше времени на ожидание других групп.
Отметим наиболее простые, но эффективные сценарии использования технологии захвата измененных данных (CDC, Change Data Capture):
- аналитика изменения данных – простой аудит;
- источники событий – запрос к главному представлению данных распределенного домена;
- внутренние или внешние панели мониторинга – преобразование данных предметной области в аналитические данные.
На практике CDC чаще всего используется как подход к интеграции, основанный на идентификации, регистрации и доставке изменений в корпоративных источниках данных во внешние системы. Этот подход можно применять в любой базе или хранилище данных, реализуя его табличных триггеров, отметок времени или номеров версий в строках таблиц, сканирования лог-файлов и потоковой обработке событий. В последнем случае в качестве CDC-инструмента часто используется распределенная open-source платформа Debezium, основанная на Apache Kafka, о чем мы рассказывали здесь.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Apache Kafka и Debezium относятся к промежуточному слою программного обеспечения, обеспечивая сбор, агрегацию и первичную обработку данных из разных источников для следующего уровня, с которым и работают конечные пользователи. Таким итоговым пунктом назначения в системах аналитики больших данных могут быть реляционные базы или корпоративные хранилища данных, которые и предоставляют информацию для наглядных витрин (дэшбордов). Одним из подобных OLAP-хранилищ является open-source проект Apache Pinot, который мы подробнее рассмотрим далее.
Что такое Apache Pinot и при чем здесь аналитика больших данных в реальном времени
Pinot — это распределенное масштабируемое OLAP-хранилище данных с низкой задержкой, работающее практически в реальном времени. Оно может принимать данные из пакетных источников (Hadoop HDFS, Amazon S3, Azure ADLS, Google Cloud Storage), а также из потоковых источников данных, таких как Apache Kafka.
Изначально этот проект был создан дата-инженерами LinkedIn и Uber и предназначен для неограниченного масштабирования с постоянной производительностью в зависимости от размера кластера и ожидаемого порогового значения количества запросов в секунду (QPS). В LinkedIn он поддерживает множество многофункциональных интерактивных приложений аналитики больших данных в реальном времени, таких как Who Viewed Profile, Company Analytics, Talent Insights и пр, всего более 50 продуктов, обрабатывая миллионы событий и более 100 тысяч запросов в секунду с миллисекундной задержкой.
Этот инструмент выполнения OLAP-запросов с малой задержкой особенно полезен там, где требуется быстрая аналитика и агрегирование неизменяемых данных, в т.ч. в реальном времени. Еще Pinot можно использовать для выполнения типичных аналитических операций с OLAP-кубами, включая детализацию и свертку крупномасштабных многомерных данных. Например, в LinkedIn это хранилище поддерживает информационные дэшборды для нескольких тысяч бизнес-показателей. Для визуализации данных к Pinot можно подключить различные BI-инструменты: Superset, Tableau или PowerBI, а также запускать ML-алгоритмы для обнаружения аномалий в хранящихся данных.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Интересно, что Pinot предоставляет разные возможности для разных Big Data специалистов [2]:
- для аналитиков и дата-инженеров это масштабируемая платформа данных для бизнес-аналитики, которая объединяет технологии Big Data с традиционной ролью хранилища данных, облегчая их анализ и генерацию отчетности;
- для разработчиков приложений Pinot можно рассматривать как неизменяемое совокупное хранилище, которое получает события из источников потоковых данных, таких как Kafka, и делает их доступными для SQL-запросов. Это устраняет недостатки микросервисной архитектуры, когда каждое приложение должно предоставлять собственное хранилище данных вместо совместного использования одного OLTP-хранилища для чтения и записи. Клиенты Pinot предотвращают разделение таблиц СУБД между разными микросервисами: разработчики могут создавать свои собственные модели запросов данных из нескольких систем в зависимости от своего варианта использования и потребностей. При этом, как и во всех хранилищах агрегатов, модели запросов в конечном итоге становятся непротиворечивыми и неизменными.
Еще из наиболее важных на практике функций Apache Pinot стоит отметить следующие [2]:
- колоночный формат хранения данных с различными схемами сжатия;
- разные варианты индексирования (отсортированный, растровый или инвертированный индекс);
- оптимизация плана запроса на основе метаданных запроса и сегмента;
- SQL-подобный язык, который поддерживает выбор, агрегацию, фильтрацию, группировку, сортировку и отдельные запросы к данным;
- поддержка многозначных полей.
По функциональным возможностям и принципам работы Apache Pinot во многом похожа на Druid и ClickHouse с Arenadata QuickMarts, но отличается от них особенностями архитектуры и управления данными [3], о чем мы подробнее поговорим в другой раз. В заключение краткого ликбеза по Apache Pinot, отметим, что это быстрое OLAP-хранилище активно используется не только LinkedIn, но и Uber, Weibo, Microsoft и ряде других компаний для оперативной аналитики больших данных в реальном времени [2].
Аналитика изменения данных и поиск событий с Apache Pinot, Debezium и Kafka
Распределенные системы обычно предполагают тесную координацию между командами, чтобы гарантировать согласованность данных и отсутствие состояния неопределенности. Например, невозможность создать новую онлайн-учетную запись для номера мобильного телефона, из-за того, что старый аккаунт уже использует номер телефона и электронную почту.
CDC-подход позволяет понять, что произошло на уровне базы данных с учетной записью клиента. Загрузив события изменений в Apache Pinot с помощью Debezium и Kafka, можно запрашивать каждое изменение базы данных для аккаунтов клиентов в режиме реального времени. В рассмотренном кейсе вместо того, чтобы обращаться к каждой отдельной системе записи, чтобы выяснить, где имеется несогласованность данных, достаточно просто запрашивать все изменения в любой учетной записи, привязанной к электронной почте или номеру телефона. Так CDC-подход позволяет выявлять и предотвращать подобные дефекты в будущем и дает командам разработчиков возможность видеть перспективу дальше, чем хранилище данных собственного микросервиса.
Что касается поиска событий, то он позволяет рассматривать источник данных как «машину времени» для понимания состояния приложения или функции в определенный момент в прошлом аналогично системам контроля версий. Применение Debezium для сбора событий изменения данных из СУБД приложения облегчает масштабирование поиска событий между разными группами разработчиков, позволяя им не выполнять дополнительную работу с исходным кодом своего микросервиса. Загрузив событие изменения базы данных в приемник, который может надежно хранить журнал каждого изменения записи, их можно повторно материализовать для новых функций и приложений.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
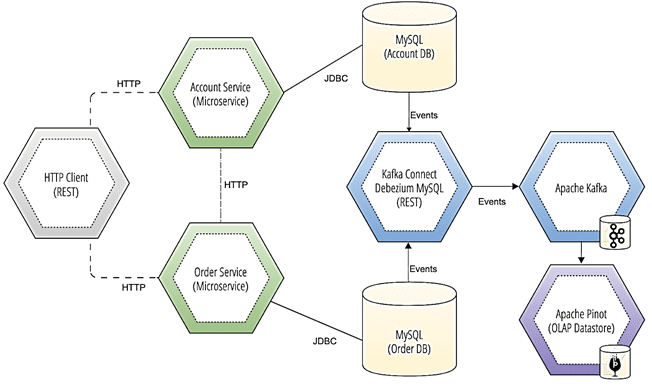
Таким образом, с OLAP-хранилищем Apache Pinot можно строить прогнозы на основе событий для всего домена, объединяя записи из разных источников. К примеру, потоки Debezium записывают события изменения данных из нескольких разных СУБД, от NoSQL до RDBMS, во множество топиков Kafka, откуда они далее попадают в Pinot. Kafka выступает средством интеграции между Debezium и Pinot, реплицируя запрашиваемое представления событий изменения данных. Это дает возможность запрашивать записи СУБД почти в реальном времени без необходимости подключения к исходной системе. В частности, в ранее рассмотренном примере с учетными записями они могут храниться в одной СУБД MySQL (Account DB), а данные о клиентских заказах, сделанных через эти аккаунты – в другом экземпляре этой базы (Order DB). За объединение этих сведений отвечает RESTful-коннектор Debezium с MySQL, совместимый с платформой Kafka Connect, который записывает необходимые события в топики самой Kafka. А Pinot выполняет роль конечного инструмента аналитики больших данных, позволяя практически в реальном времени получать нужные бизнесу сведения через SQL-подобные запросы [1]. Как именно реализуется получение данных в таблицы Pinot из топиков Kafka в реальном времени, мы рассмотрим завтра. А пример реализации CDC-подхода к отслеживанию измененных данных в MySQL средствами Apache NiFi смотрите в нашей новой статье.
Разобраться во всех особенностях администрирования кластеров Apache Kafka, а также использования этой event-streaming платформы для интеграции информационных систем и разработки распределенных приложений потоковой аналитики больших данных, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

