 1174
1174 
Содержание
Сегодня мы поговорим про качество данных – что это за показатель, в чем он измеряется и почему так важен для машинного обучения и других приложений Big Data. Читайте в нашей статье про процессы и инструменты управления качеством данных, а также профессию Data Quality инженера.
Почему большие данные должны быть качественными или что такое Data Quality
Большие данные полезны только когда из них можно извлечь ценные для бизнеса сведения – инсайты. Чтобы анализировать множество файлов или записей Big Data, эти информационные наборы должны обладать не только определенной структурой, но и отвечать следующим характеристикам [1]:
- актуальность – соответствие данных отражают реальному состоянию целевого объекта в текущий период времени;
- объективность — точность отражения данными реального состояния целевого объекта, которая зависит от методов и процедур сбора информации, а также от плотности регистрируемых данных;
- целостность – полнота отражения данными реального состояния целевого объекта, которая показывает, насколько полны, безошибочны и непротиворечивы данные по смыслу и структуре (формату) с сохранением их правильной идентификации и взаимной связанности. Сюда же относится своевременное обнаружение и устранение локальных «болот данных» (data silos). Отдельно про целостность данных читайте в этом материале. А здесь вы узнаете об обеспечении целостности к сущностям в виде подходов entity resolution и identity resolution.
- релевантность – соответствие данных о реальном состоянии целевого объекта и решаемым задачам, что характеризует возможность их применения с учетом содержания, структуры и формата;
- совместимость – процедурный показатель, который характеризует возможность обрабатывать и анализировать данные в дальнейшем, не только в рамках текущей задачи;
- измеримость – качественные или количественные характеристики реального состояния целевого объекта и конечный объем набора цифровых данных.
- управляемость – возможность целевым и осмысленным образом обработать, передать и контролировать данные о реальном состоянии целевого объекта, на основе структуры и формата датасета;
- привязка к источнику данных – связанная и достоверная идентификация цепочки поставки данных, например, указание авторства, источника генерации и прочие атрибуты происхождения данных (Data Provenance);
- доверие к поставщику данных – оценка получателем деловых качеств поставщика публичных данных как ответственного, авторитетного, организованного и относительно независимого издателя цифровой информации высокого качества.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Совокупность количественных оценок каждого из этих показателей отражает качество данных (Data Quality) – характеристику, показывающую степень их пригодности к обработке и анализу, а также соответствие обязательным и специальным требованиям [1]. В упрощенном понимании качество данных – это степень их пригодности к использованию. В частности, стандарт ISO 9000:2015 именно так определяет качество данных по степени их удовлетворения требованиям: потребностям или ожиданиям, таким как полнота, достоверность, точность, последовательность, доступность и своевременность [2]. Эти и другие характеристики качества также мы рассматриваем в нашей новой статье про наблюдаемость данных.
На практике оценка качества данных сильно зависит от контекста их использования. Например, для крупных маркетинговых кампаний может быть приемлемо до 3-5% дублированных или пропущенных записей, а в случае с медицинскими исследованиями такое недопустимо. Поэтому дисциплина интеллектуального анализа данных (Data Mining) выделяет целых 5 процедур подготовки информационных наборов к использованию в машинном обучении. Подробнее об этом мы рассказывали здесь. Однако, качество данных важно не только для точности алгоритмов Machine Learning. Устаревшие или ненадежные данные могут привести к дорогостоящим ошибкам, например, лишним расходам на закупку материалов из-за отсутствия актуальных сведений о складских запасах.
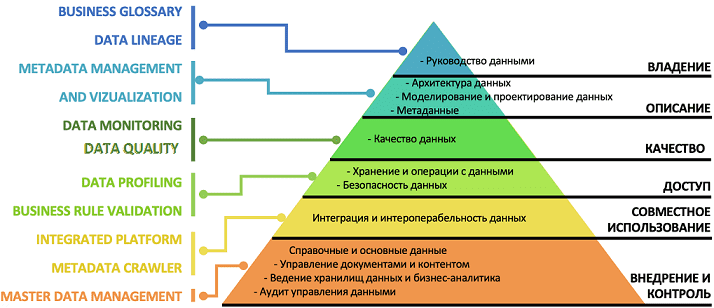
Как управлять качеством данных: процессы и инструменты
За оценку качества данных отвечают инженеры Data Quality, которые управляют информационными массивами, проверяют их поведение в текущих и новых условиях, контролируют релевантность, достаточность и актуальность. Как правило, обязанности Data Quality инженера не ограничиваются только рутинными проверками записей в таблицах СУБД, а требуют глубокого понимания бизнес-потребностей, чтобы трансформировать имеющиеся данные в пригодную к практическому использованию информацию. Для этого решаются следующие задачи: [3]:
- автоматизированная подготовка тестовых данных;
- загрузка подготовленного датасета в исходный источник, например, озеро данных (Data Lake);
- запуск ETL-процессов для обработки набора данных из исходного источника и отправку в окончательное или промежуточное хранилище с возможностью конфигурации параметров ETL-задачи, например, с помощью Apache Airflow;
- верификация данных после ETL-обработки на предмет их качества и соответствие бизнес-требованиям.
Для организации data chain – цепочки проверочных тестов на каждой стадии обработки данных от источника до пункта финального использования могут использоваться легковесные SQL-запросы. Они помогают оценить отдельные атрибуты качества данных, например, tables metadata, blank lines, NULLs, Errors in syntax. Для регрессионного тестирования, когда используются уже готовые неизменяемые датасеты, код автотестов уже хранит готовые шаблоны проверки данных на соответствие качеству, такие как описания ожидаемых метаданных таблиц, строчных выборочных объектов для случайного выбора и т.д. Иногда в ходе тестирования Big Data Quality инженер пишет тестовые ETL-процессы с помощью Apache Spark или Airflow, используя уже готовые операторы, в частности, GCP BigQuery или создавая собственные [3]. Про операторы Apache Airflow мы писали здесь, на примере Kubernetes Operator.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
2 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Разумеется, все это инженеры Data Quality выполняют не вручную. Современный рынок ПО предлагает множество специализированных инструментов для проверки качества данных и их улучшения. В частности, Informatica Data Quality, Microsoft Data Quality Services, Oracle Enterprise Data Quality, SAP Data Services, Talend Open Studio for Data Quality и другие коммерческие продукты, а также открытые сервисы и библиотеки типа Great Expectations. Аналитическое агентство Gartner составило список ТОП-10 таких решений, проранжировав их по удобству использования, функциональным возможностям и отзывам профессионалов [4].
Как правило, большинство специализированных систем управления качеством данных автоматизируют следующие процессы Data Quality Management [2]:
- профилирование – первоначальная оценка данных, чтобы понять их текущее состояние, в т.ч. распределение значений;
- стандартизация – механизм бизнес-правил, обеспечивающий соответствие данных стандартам;
- геокодирование адресов, которое корректирует данные в соответствии с географическими стандартами;
- сопоставление или связывание – способ сравнения данных для выявления одинаковых по смыслу, но разных по виду представления записей. Сопоставление может использовать нечеткую логику для поиска дубликатов в данных. Например, «Петр» и «Птер» может быть одним и тем же человеком, который проживает по одинаковому адресу.
- мониторинг – отслеживание качества данных с течением времени и отчетность об изменениях с автоматическим исправлением изменений на основе предварительно определенных бизнес-правил;
- пакетная и потоковая обработка – первичная очистка данных в пакетном режиме с последующей интеграцией в корпоративные приложения.
Обеспечение качества данных не сводится лишь к технической задаче устранения дублирующихся или пропущенных значений. Важна также организационная сторона этого процесса, где задействован не только Data Quality инженер. В следующей статье мы поговорим про ответственность за качество данных и профессию дата стюарда (Data Steward). А о лучших практиках повышения Data Quality в компании Airbnb с помощью организационных изменений и архитектурно-технических решений читайте здесь.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Как построить согласованную и эффективную архитектуру данных, обеспечив их качество, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

