 1132
1132 
Продолжая разговор про Delta Lake, сегодня мы рассмотрим, чем это быстрое облачное хранилище для больших данных в реализации компании Databricks отличается от классического озера данных (Data Lake) на Apache Hadoop HDFS. Читайте далее, как коммерческое Cloud-решение на Apache Spark облегчает профессиональную деятельность аналитиков, разработчиков и администраторов Big Data.
Больше, чем просто облачный Hadoop или Spark: преимущества Delta Lake от Databricks
Напомним, наиболее известной коммерческой реализацией open-source технологии Data Lake считается продукт международной компании Databricks [1]. Помимо архитектурных плюсов Apache Spark по сравнению с Hadoop, Databricks привнесла в концепцию облачного масштабируемого и надежного хранилища данных следующие преимущества [2]:
- Простота администрирования. В кластерах Apache Hadoop системный менеджер ресурсов YARN управляет емкостью и согласованием заданий. При этом балансировка кластерной нагрузки предполагает довольно высокий уровень владения тонкостями конфигурирования распределенной системы для настройки баланса между потребностями нескольких пользователей с учетом емкости и производительности каждого из узлов. Кластер в Databricks создается и настраивается в облачном варианте по запросу (On-Demand), используя встроенную эластичность и масштабирование Cloud-подхода. Такая SaaS/PaaS-модель освобождает пользователей от операционной рутины по управлению мощностью в длительно работающих кластерах — пользователи легко развертывают новые эластичные кластеры, которые автоматически расширяются или сжимаются в зависимости от требований рабочей нагрузки и могут автоматически отключаться в периоды ожидания. Это позволяет пользователям облачного озера данных Databricks уделить больше внимания аналитике больших данных с Apache Spark, не размениваясь на сопровождающие процессы.
- Хранение данных. В Apache Hadoop в качестве хранилища больших данных используется распределенная файловая система HDFS, привязанная к вычислениям. Databricks предлагает собственное облачное хранилище, такое как S3 на AWS или ADLS в Azure, что приводит к независимости вычислений от архитектуры хранилища. Это позволяет пользователям масштабировать распределенные вычисления независимо от хранилища и избавляет от необходимости планировать емкость хранилища или сталкиваться с ограничениями масштабируемости имен HDFS-узлов.
- Сервисный подход. Delta Lake от Databrick позволяет пользователям создавать надежные и производительные озера данных в Cloud-хранилище, отражая все современные тенденции в мире ИТ: высокая скорость распределенных вычислений, эластичная масштабируемость кластеров и повышенная производительность приложений за счет облачных технологий.
- Интеграция с другими Big Data фреймворками и облачными сервисами. Экосистема Apache Hadoop включает полезные для анализа больших данных движки: Hive, open-source Spark и HBase. Delta Lake от Databrick продолжает эту концепцию единого информационного пространства, легко интегрируясь с облачными сервисами, а такжеNoSQL-СУБД.
- Производительность и параллелизм. Параллелизм заданий в общем кластере работает по-разному в Delta Lake Databricks и озере данных на Apache Как мы уже отметили, Hadoop использует менеджер кластерных ресурсов YARN. Он включает планировщик заданий и пулы ресурсов для управления заданиями, запуская новый драйвер Spark для каждого задания, чтобы обеспечить восстановление заданий и параллелизм в одном кластере. Однако, ресурсы YARN ограничены общей емкостью кластера. Это может привести к увеличению времени выполнения заданий, конкуренции за ресурсы, невыполнению соглашений об уровне обслуживания и повышению сложности рутинных операций по разделению ограниченной мощности между несколькими конкурирующими рабочими нагрузками. Реализация Apache Spark в Databricks, по сравнению с open-source версией, ориентирована на потребности корпоративного использования, она более производительна, масштабируема и готова к работе для предприятий. В частности, поддержка транзакционных конвейеров, автономного кэширования и методов кластеризации данных позволяет создать облачное озеро данных, удовлетворяя любые потребности запросы современного data-driven предприятия.
Разумеется, решение Databricks, — далеко не единственное коммерческое воплощение открытой технологии Delta Lake уровня enterprise. На отечественном рынке это направление продвигает компания «Неофлекс», предлагая на его базе комплексные решения по внедрению MLOps [3], о чем мы писали здесь.
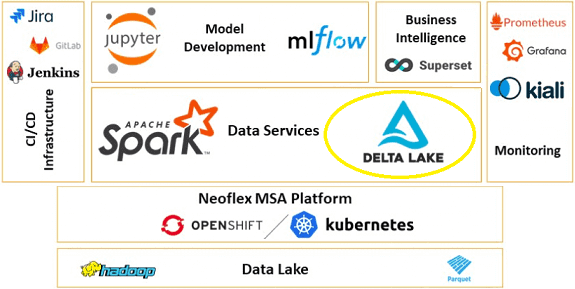
В заключение отметим, что, как и любая технология, в дополнение к своим достоинствам, Delta Lake имеет ряд ограничений, которые могут расцениваться как недостатки. О них мы расскажем в следующей статье.
Как эффективно использовать Apache Spark и Hadoop для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

