 2135
2135 
Содержание
Сегодня мы расскажем, почему и зачем сейчас почти все сайты собирают cookies, что такое GDPR, как банки собираются оценивать кредитоспособность потенциального заемщика по истории его запросов в браузере и насколько это легально. Читайте в нашей статье про персональные данные, синергетический эффект технологий Big Data и финансовый скоринг на основе пользовательского поведения в сети с помощью машинного обучения (Machine Learning).
Зачем собирать cookies, что такое GDPR и при чем тут персональные данные
С 2019 года практически на каждом сайте всплывает сообщение о сборе пользовательских данных: IP-адрес, cookie, информации о браузере и геолокации, время доступа и адрес запрашиваемой страницы. Далее следует приписка, что вся эта информация о пользовательском поведении нужна, чтобы улучшить сайт и маркетинговую аналитику. На самом деле подобное уведомление показывается, чтобы избежать претензий Роскомнадзора и обвинений в нарушении генерального регламента о защите персональных данных граждан и резидентов Евросоюза (GDPR, General Data Protection Regulation).
GDPR действует во всех странах, включая РФ, с 25.05.2018 [1] и предусматривает штрафы до 20 миллионов евро или 4% от мирового оборота компании-нарушителя [2]. В России процедуры сбора, обработки и защиты информации о пользовательском поведении регламентирует №152-ФЗ «О персональных данных». Под персональными данными понимаются сведения о физическом лице, на основании которых его можно прямо или косвенно определить [3]:
- информация, зафиксированная в официальных документах – ФИО, паспортные данные, дата и место рождения, адреса мест регистрации и проживания;
- контакты – номер телефона и email;
- информация социального характера о семейном и имущественном положениях, образовании, профессии и доходах;
- аналитические сведения о пользовательском поведении в интернете – идентификатор устройства, ip-адрес, браузер, файлы cookie и геолокация.
Согласно №152-ФЗ и GDPR, следует предупредить клиента о сборе персональных данных и получить его согласие на обработку такой информации. Штраф за нарушение этого закона составляет максимум 50 тысяч рублей (ч.1 ст.13.11 КоАП), что гораздо ниже аналогичного наказания по GDPR. Пользовательские данные продолжают собираться и использоваться не по назначению, попадая сторонним компаниям и даже утекая в открытый доступ. Это происходит постоянно, несмотря на ряд инцидентов с вынесением обвинительных приговоров известным компаниям, среди которых Уральские Авиалинии, LinkedIn [4]), Google, Uber, Facebook, British Airways [5].
Помимо уголовных правонарушений (фальсификация кредитных договоров, вымогательства и прочие мошеннические операции), персональные данные используются для таргетированной рекламы [5]. Но персонифицированный маркетинг – это не единственная прибыльная и относительно легальная область применения данных о пользовательском поведении. Технологии Big Data обеспечивают синергетический эффект при обмене информацией между разными прикладными сферами. В частности, в декабре 2019 года рунет взорвала новость о проекте финансового скоринга физлиц на основании информации, которую можно получить от сотовых операторов, из соцсетей, интернет-магазинов и розничных магазинов: данные о геолокации, интересах, круге общения, примерном уровне дохода и тратах и прочие данные о потребительском поведении [6]. Как это уже делается и насколько легально, мы рассмотрим далее.
Как Machine Learning от Яндекса оценивает вашу платёжеспособность
На самом деле машинное обучение для оценки кредитоспособности потенциального заемщика используется на практике уже несколько лет. Однако, раньше банки сами собирали входные данные для своих ML-моделей, не прибегая к сторонним источникам. Сегодня же крупнейшие операторы персональных данных могут существенно облегчить финансовым организациям, поставляя им нужные сведения.
В частности, «Интернет-скоринг бюро», совместный проект «Яндекса» и объединенного кредитного бюро (ОКБ), собирается оценивать платежеспособность физлиц, рассчитывая для каждого человека скоринговый (от англ. score) балл. Бюро кредитных историй (БКИ) имеет информацию о текущих и закрытых займах, включая запросы на кредиты и историю выплат. Крупнейший российский поисковик владеет статистикой о поведении свой пользователей. Анализируя около 1000 различных параметров, «Яндекс» с помощью собственных алгоритмов и моделей Machine Learning рассчитывает первичный скоринговый балл. Затем это число добавляется к оценке БКИ. Общий показатель передается в банк, который принимает решение по данному клиенту. Согласно ОКБ, такая модель способна оценить более 95% заемщиков [7]. При этом Яндекс подчеркивает, что анализируемые им данные являются обезличенными, обрабатываются автоматически и находятся исключительно в закрытом контуре корпорации. Но для расчетов по конкретному клиенту КБИ передает «Яндексу» в зашифрованном виде два идентификатора пользователя: адрес электронной почты и мобильный телефон. Эти сведения относятся к персональным данным даже в хэшированном виде и, согласно закону, не должны быть использованы в целях, не указанных при сборе этой информации. Таким образом, для получения совместного скоринга от ОКБ и «Яндекса» требуется согласие клиента на обработку персональных данных. При его отсутствии, если банк отказал в кредите на основании истории запросов в поисковике, это может считаться поводом для судебного иска [7].

Волк, коза и капуста или как Центробанк планирует соблюсти №152-ФЗ, поддерживая интересы банков с помощью технологий Big Data
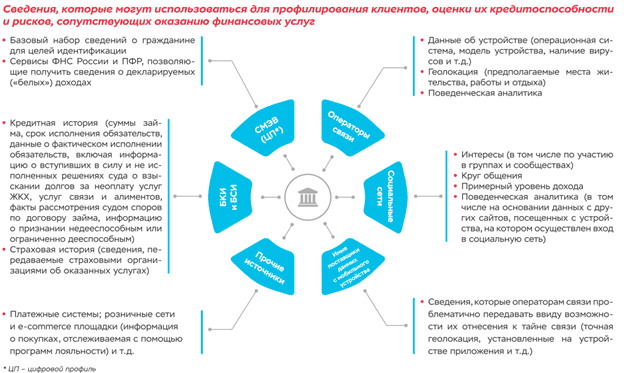
Несколько банков (Ренессанс-Кредит, Совкомбанк) уже протестировали вышеописанный скоринговый сервис от Яндекса, другие используют собственные аналогичные продукты (Открытие). При этом почти все финансовые организации заинтересованы в развитии такой инициативы: ВТБ, Росбанк, Альфа-Банк, АК Барс и другие финансовые корпорации [7]. Центробанк также участвует в этом проекте, опубликовав на своем сайте доклад для общественных консультаций «Недискриминационный доступ к данным физических лиц на финансовом рынке» [6]. В этом документе анализируется текущее состояние процессов обмена данными и обработки информации о физлице, влияние этих данных на конкуренцию между банками и возможные меры обеспечения конкурентного доступа к этой информации. При этом персональные данные позиционируются как информация, не являющаяся тайной, доступ к которой ограничен и возможен с согласия субъекта или без него, если имеется публичный интерес [8].
Разумеется, Центробанк отмечает необходимость защиты персональных данных в соответствии с требованиями №152-ФЗ, возлагая эту обязанность на сами банки и скоринговые компании. Однако это не гарантирует защиту персональных данных, учитывая утечку сведений примерно о 50 миллионах россиян, случившуюся в 2019 году по вине финансовых организаций. Напомним, менее чем за 6 месяцев (с июня по ноябрь 2019) эти инциденты произошли с клиентами ВТБ, Сбербанка, Альфа-банка, ОТП-банка и ХКФ-банка [5]. Кроме того, в конце декабря 2019 года из-за ошибочной настройки одного из серверов публичном доступе оказались персональные данные пользователей портала государственных услуг Ханты-Мансийского региона [9]. Отметим, что Центробанк планирует использовать государственные интернет-сервисы (порталы ФНС и ПРФ России) в качестве одного из источников данных для профилирования клиентов и оценки их кредитоспособности [8]. Однако, текущая ситуация с постоянно поступающими сообщениями об утечках информации, как с частных, так и с государственных площадок, пока не позволяет надеяться на надежную защиту наших персональных данных.
Тем не менее, при всех своих спорных моментах и потенциальных рисках, инициатива Центробанка вполне перспективна. Она снова доказывает, что технологии Big Data способны принести бизнесу дополнительную прибыль за счет предиктивной аналитики данных из разных источников, сэкономив таким образом время и силы на принятие решений. Более того, Центробанк также продвигает использование биометрических персональных данных в качестве уникальных идентификаторов каждого клиента, о чем мы подробно рассказываем здесь. А каким образом большие данные помогут вашему предприятию, узнайте на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://ru.wikipedia.org/wiki/Общий_регламент_по_защите_данных
- https://www.gazeta.ru/tech/2019/08/09_a_12567469.shtml
- https://ru.wikipedia.org/wiki/Персональные_данные
- https://retailer.ru/soglasie-kuki-i-zaprosy-chto-takoe-personalnye-dannye-dlja-sajta/
- https://chernobrovov.ru/articles/chernyj-rynok-dannyh-kak-zashhitit-sebya-i-svoih-klientov/
- https://www.kommersant.ru/doc/4198282
- https://www.rbc.ru/finances/24/12/2019/5e00e2409a79478017f453e6
- https://www.cbr.ru/Content/Document/File/95166/Consultation_Paper_191218.pdf
- https://habr.com/ru/news/t/482394/

