Продвигая наши курсы по прикладной Data Science и графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим специальную DS-библиотеку в Neo4j и ее возможности для фильтрации подграфов. А также разберем, чем версия сообщества отличается от Enterprise Edition, как запустить анализ слабо связанных компонент и алгоритм определения центральности на проекции графа в памяти.
Graph Data Science: принципы работы библиотеки Neo4j
Напомним, графовые алгоритмы используются для вычисления показателей для узлов или отношений графа. Они могут дать представление об объектах на графе (центральность, ранжирование) или присущих ему структурах, таких как сообщества: например, обнаружение сообществ, разбиение графа, кластеризация и пр. Многие графовые алгоритмы представляют собой итерационные подходы, которые часто обходят граф для вычислений с использованием случайных обходов, поиска в ширину или в глубину или сопоставления с образцом. Из-за экспоненциального роста возможных путей с увеличением расстояния эти подходы имеют высокую алгоритмическую сложность. Но есть и оптимизированные алгоритмы, которые используют определенные структуры графа, запоминая уже исследованные части и распараллеливая операции. Например, алгоритм Дейкстры для поиска кратчайшего пути на графе с неотрицательными ребрами, что мы рассматриваем здесь.
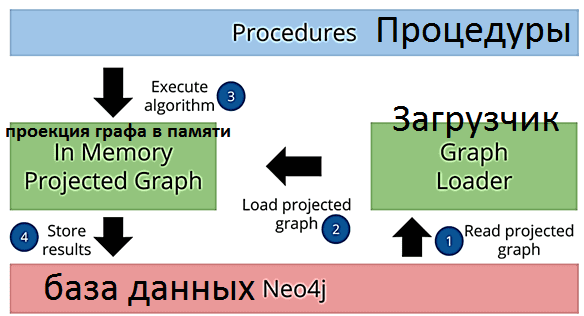
Библиотека NoSQL-СУБД Neo4j под названием Graph Data Science (GDS) использует загрузчик Graph Loader, чтобы проецировать граф в память. Алгоритмы графа работают на модели данных, которая является проекцией графа свойств Neo4j. Проекцию графа можно рассматривать как материализованное представление сохраненного графа, содержащее только аналитически релевантную, потенциально агрегированную, топологическую информацию и информацию о свойствах. Проекции графов полностью хранятся в памяти с использованием сжатых структур данных, оптимизированных для топологии и поиска свойств.
Граф в памяти для GDS основан на макете сжатых разреженных строк (CSR, Compressed Sparse Row) и по умолчанию использует сжатые списки смежности. Сжатие снижает использование памяти для графа, но требует дополнительного времени вычислений для распаковки во время выполнения алгоритма. Использование несжатого списка смежности увеличивает потребление памяти для более быстрого обхода. Это снижает производительность из-за увеличения размера резидентной памяти. Использование большего объема памяти требует более высокой пропускной способности памяти для чтения того же списка смежности. Что лучше использовать: сжатый или несжатый граф, во многом зависит от его топологии и алгоритма. Алгоритмы с большим объемом обхода, такие как подсчет треугольников, имеют больше шансов получить выгоду от несжатого списка смежности. Очень плотные узлы в графах с очень искаженным распределением степеней часто достигают более высокой степени сжатия. Использование несжатого списка смежности на этих графах имеет больше шансов столкнуться с ограничениями пропускной способности памяти.
Еще одной важной концепцией GDS-библиотеки является каталог графов – специальный формат графа в памяти для представления данных. Каталоги позволяют управлять несколькими проекциями графов по имени и многократно использовать созданные графы в аналитическом рабочем процессе. Сперва необходимо загрузить данные графа из базы данных Neo4j в каталог графов в памяти с помощью загрузчика. Объем загружаемых данных можно контролировать с помощью проекций, которые позволяют, например, фильтровать узлы и отношения по меткам.
Именованные графы могут быть созданы с использованием нативных проекций (Native) или языка запросов Cypher. После использования именованные графы можно удалить из каталога, чтобы освободить основную память. При этом создание, использование, перечисление и удаление именованных графов доступны только в рамках одного пользовательского сеанса Neo4j, т.е. не могут применяться сразу несколькими пользователями.
GDS-Библиотека Neo4j доступна в двух редакциях. Версия Community Edition с открытым исходным кодом включает в себя все алгоритмы и функции, но ограничена четырьмя ядрами ЦП. Enterprise Edition может работать на неограниченном количестве ядер ЦП и поддерживает систему управления доступом на основе ролей (RBAC), а также различные дополнительные функции каталога моделей. Также GDS-библиотека может хранить неограниченное количество моделей в каталоге моделей, позволяет сохранять модели на диск и затем публиковать их.
GDS Enterprise Edition использует другую реализацию графа в памяти, которая потребляет меньше памяти по сравнению с версией сообщества (Community). Поскольку производительность реализации графа в памяти зависит от размера и топологии его базового графа, работа с проекцией в памяти может быть медленнее для записи и создания графов меньшего размера. Чтобы переключиться на реализацию с большим объемом памяти, используемую в GDS Community Edition, можно отключить эту функцию, передав методу features.useBitIdMap значение false: CALL gds.features.useBitIdMap(false). Как извлечь данные из проекции графа в библиотеке GDS и передать их в конвейер машинного обучения с помощью плагина neo4j-arrow и независящей от языка программной среды Apache Arrow для разработки приложений анализа данных в колоночных форматах, читайте в нашей новой статье.
Фильтрация подграфов: пара примеров
Фильтрация подграфов позволяет создать новый спроектированный граф в памяти на основе существующего спроецированного графа. Например, можно спроецировать граф, определить в нем слабо связанные компоненты, а затем использовать фильтрацию подграфов для создания нового спроецированного графа, который состоит только из самого большого компонента. Это упрощает процесс анализа графовых данных, позволяя не сохранять промежуточные результаты обратно в базу данных и повторно использовать загрузчик Graph Loader для проецирования нового графа в память.
Можно использовать статистический режим алгоритма, когда нужен только общий обзор результатов и не требуется сохранять результаты обратно в Neo4j или в спроецированный граф. Синтаксис процедуры фильтрации подграфов следующий:
CALL gds.beta.graph.subgraph( graphName: String, -> name of the new projected graph fromGraphName: String, -> name of the existing projected graph nodeFilter: String, -> predicate used to filter nodes relationshipFilter: String -> predicate used to filter relationships )
Параметр nodeFilter позволит отфильтровать узлы по свойствам или меткам. Аналогично параметр RelationshipFilter фильтрует отношения – связи между узлами.
Графовые алгоритмы. Бизнес-приложения
Код курса
GRAF
Ближайшая дата курса
20 мая, 2024
Продолжительность
24 ак.часов
Стоимость обучения
54 000 руб.
Предположим, в Neo4j уже есть маркированный взвешенный граф. Создадим его проекцию в памяти, которая содержит только отношения с весом больше 1.
CALL gds.beta.graph.create.subgraph( 'wgt1', // name of the new projected graph 'interactions', // name of the existing projected graph '*', // node predicate filter 'r.weight > 1' // relationship predicate filter )
Оператор подстановочного знака * показывает отсутствие фильтрации по узлам. Синтаксис предиката аналогичен запросу Cypher. Сущность отношения всегда обозначается r, а сущность узла — переменной n. Можно продолжить и запустить алгоритм слабо связанных компонент (WCC, Weakly Connected Components) на новом графе в памяти, созданном с помощью фильтрации подграфов, обратившись к нему по имени wgt1:
CALL gds.wcc.mutate('wgt1', {mutateProperty:'wcc'})
YIELD componentCount, componentDistribution
Если нужно выявить центральность собственного вектора на самом большом компоненте графа, следует сперва определить его идентификатор. Результаты WCC-алгоритма сохраняются в спроецированном графе в памяти, поэтому следует использовать процедуру gds.graph.streamNodeProperties для доступа к результатам WCC и определения самого большого компонента. Для этого составляется Cypher-запрос аналогичный SQL-запросу с сортировкой и ограничением результатов:
CALL gds.graph.streamNodeProperties('wgt1', ['wcc'])
YIELD propertyValue
RETURN propertyValue as component, count(*) as componentSize
ORDER BY componentSize DESC
LIMIT 5
К полученным результатам можно применить функцию фильтрации подграфов для создания нового проецируемого графа в памяти, который содержит только узлы в самом большом компоненте.
CALL gds.beta.graph.create.subgraph( 'largest_community', 'wgt1', 'n.wcc = 0', '*' )
Чтобы определить центральность собственного вектора только для самого большого компонента, следует вызвать функцию GDS-библиотеки eigenvector.stream с параметром largest_community
CALL gds.eigenvector.stream('largest_community')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name as character, score
ORDER BY score DESC
LIMIT 5
О том, как визуализировать графы в Neo4j, включая анализ кибербезопасности, читайте в нашей новой статье. А о другой полезной библиотеке, которая реализует GraphQL-запросы в этой графовой СУБД, мы рассказываем здесь. Про эмбеддинг-алгоритмы GDS для задач NLP мы сделали отдельную статью.
Узнайте больше подробностей про использование возможностей Neo4j и другие инструменты графовой аналитики больших данных для реальных бизнес-приложений на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

