 633
633 
Содержание
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica.
Зачем и как выполнить развертывание Apache Flink в Kubernetes
Развертывание Apache Flink в Kubernetes дает гибкое и легкое использование потоковых приложений без необходимости управления инфраструктурой. Чтобы развернуть приложения Apache Flink на платформе Kubernetes с целью улучшения масштабируемости и реализации CI/CD с помощью контейнеров, можно использовать различные операторы – программные расширения Kubernetes, которые используют настраиваемые ресурсы для управления приложениями и их компонентами. Оператор стремится абстрагироваться от сложности размещения, настройки, управления и эксплуатации кластеров Flink от разработчиков приложений. Это достигается за счет расширения любого кластера Kubernetes с использованием пользовательских ресурсов. Операторы позволяют разработчикам создавать свои собственные объекты и упрощать развертывание, а также предлагают возможность добавления пользовательской логики. Однако, самостоятельная разработка и проверка операторов требуют много времени и сил. Поэтому проще использовать готовые решения, уже разработанные отдельными вендорами или энтузиастами сообщества.
Прежде всего отметим нативное решение Kubernetes от Apache Flink, которое не требует добавления каких-либо пользовательских объектов или дополнительных приложений для управления Flink. Кластер Flink Session выполняется как длительное развертывание Kubernetes: можно запустить несколько заданий в кластере сеансов. Каждое задание должно быть отправлено в кластер после его развертывания.
Кластер приложений Flink — это выделенный кластер, на котором выполняется одно приложение. Нативный Kubernetes не вводит никакого оператора, и установка довольно проста. Процесс CI/CD аналогичен другому контейнеризированному приложению, работающем в Kubernetes — достаточно развернуть все непосредственно из CI/CD-инструмента, и проверить работоспособность приложения. Однако, здесь нет пользовательских объектов и поддержки кластеров для каждого задания, а также ограничены некоторые функции без механизма перезапуска, за исключением прямого задания Flink. Подробнее об этом способе развертывания приложения Apache Flink и его сравнении с кластером Amazon EMR читайте в нашей новой статье.
Сине-зеленое развертывание с оператором от Lyft
Другим решением является FlinkK8sOperator — оператор Kubernetes, который управляет приложениями Flink в Kubernetes. Он действует как плоскость управления для управления полным жизненным циклом развертывания приложения. Изначально оператор был разработан компанией Lyft, а сейчас поддерживается сообществом. Последняя версия (v0.5.0) этого оператора была выпущена 30 апреля 2020 года. До сих пор проект все еще находится в стадии бета-тестирования.
Оператор динамически создает кластеры Flink, используя указанный пользовательский ресурс. Кластеры Flink в Kubernetes состоят из развертывания JobManager и диспетчера задач, а также сервиса диспетчера заданий. Необязательным компонентом является JobManager Ingress (базовый тип ресурса в Kubernetes) для UI. Этот объект API управляет внешним доступом к службам в кластере, обычно HTTP, и может обеспечивать балансировку нагрузки, терминацию SSL и виртуальный хостинг на основе имени.
Развертывание и управление приложениями Flink в Kubernetes состоит из 2-х этапов:
- создание Flink-приложения, упакованного в Docker-образ, который содержит исходный код приложения с необходимыми встроенными зависимостями. Это нужно для начальной загрузки подов Jobmanager и Taskmanager.
- создание пользовательского ресурса Flink-приложения, который предоставляет спецификацию для настройки и управления кластерами Flink в Kubernetes. FlinkK8sOperator, развернутый в Kubernetes, постоянно отслеживает ресурс и соответствующий кластер Flink и выполняет действия.
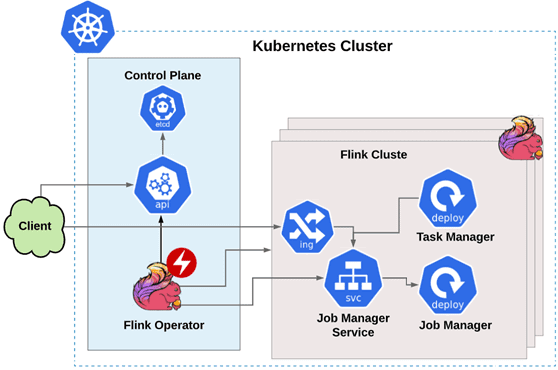
Для установки и обновления можно использовать манифесты Kubernetes или Helm-диаграмму, при этом следует помнить про значения конфигураций по умолчанию, чтобы не столкнуться с OOM-ошибками при работе контейнеризованного приложения, о чем мы писали здесь. Аналогичным образом организуется процесс CI/CD через манифесты Kubernetes или диаграммы Helm со всеми обновлениями и настройками. Можно использовать настраиваемые определения, управляемые оператором, такие как развертывание и обслуживание JobManager или TaskManager. Оператор обеспечивает так называемое «сине-зеленое» развертывание, что считается одной из лучших DevOps-практик и сокращает время простоя за счет запуска двух идентичных производственных сред: синей и зеленой. В любой момент только одна из этих сред активна и обслуживает весь трафик, а старое задание заменяется новым, когда оба запущены и только одно из них обрабатывает данные. Однако, при этом немного снижается скорость отправки новых заданий, которая зависит в основном от количества доступных ресурсов. Сине-зеленое развертывание может занять несколько минут.
Сине-зеленое развертывание дает быстрый способ отката — если что-то пойдет не так, можно переключить маршрутизатор обратно в синюю среду. По-прежнему существует проблема обработки пропущенных транзакций, когда зеленая среда была активной, но в зависимости от дизайна можно передавать транзакции в обе среды так, чтобы синяя среда оставалась резервной, когда зеленая среда активна. Также можно перевести приложение в режим только для чтения перед переключением, запустить его на некоторое время в режиме только для чтения, а затем переключить его в режим чтения-записи. Две среды должны быть разными, но максимально идентичными, хотя могут быть представлены разными аппаратными средствами или виртуальными машинами. Они также могут представлять собой единую операционную среду, разделенную на отдельные зоны с отдельными IP-адресами для двух частей. О том, как дата-инженеры компании Storyblocks применили идею сине-зеленого развертывания к ETL-процессам массовой загрузки данных в корпоративное DWH, используя механизм TaskGroup в Apache Airflow, читайте в нашей новой статье.
При использовании FlinkK8sOperator любая конфигурация Flink-задания управляется так же, как и в кластере YARN, что достигается с помощью шаблонов с ConfigMap, хранящихся в репозитории. Все пользовательские объекты в Kubernetes отлично работают, как и подключения Flink к объектному хранилищу, Kafka или HDFS, в т.ч. с использованием защищенного протокола Kerberos. Однако, в этом решении нет централизованного управления рабочими местами, отсутствует SQL-редактор, нельзя запускать сессионные кластеры, а запуск задания может быть медленным. Наконец, оператор от Lyft до сих пор находится в стадии бета-тестирования, т.е. потенциально может быть источником неведомых ошибок.
Оператор от Google Cloud
Хотя этот Kubernetes-оператор для Apache Flink и находится в Githib-репозитории Google Cloud, он официально не поддерживается этой корпорацией, хотя продолжает активно развиваться. В частности, последняя версия этого решения (0.2.1) в статусе бета-релиза под лицензией Apache 2.0 выпущена в феврале 2021 года. Как и в предыдущем случае, для его установки и развертывания можно использовать манифесты Kubernetes или диаграммы Helm. Оператор создает определение пользовательского ресурса FlinkCluster и запускает под контроллера, чтобы следить за пользовательскими ресурсами. Это позволяет пользователям взаимодействовать с кластером через Kubernetes API и настраиваемые ресурсы Flink для управления кластерами и заданиями.
Как только настраиваемый ресурс FlinkCluster создан и обнаружен контроллером, контроллер создает базовый ресурс Kubernetes, например, под JobManager, на основе спецификации настраиваемого ресурса. Конвейеры CI/CD также настраиваются через диаграммы Helm или манифесты Kubernetes. При этом нужно проверить, запущено ли задание, вызвав Kubernetes API и получив статус модулей Flink и их объекта. Оператор дает возможность перезапускать невыполненные задания с последней точки сохранения, а также настроить пакетное планирование для подов JobManager и TaskManager.
Будучи неофициальным продуктом Google Cloud Platform , оператор поддерживает другие сервисы GCP: коннектор Google Cloud Storage, сервисные аккаунты IAM и пр., а также Python-задания Apache Beam. Однако, здесь нет централизованного управления заданиями, также как и Lyft отсутствует SQL-редактор и присутствует статус бета-релиза.
В заключение отметим еще один способ развертывания Flink-приложений в кластере Kubernetes, предлагаемый разработчиками платформы Ververica, которая коммерциализирует этот фреймворк. Она доступна в виде бесплатной версии Community Edition с ограничением одного пространства имен для заданий и без аутентификации, имеет простой процесс установки, мощный REST API для конвейеров CI/CD и возможность гибкого управления заданиями Flink, включая конфигурацию и состояния. Также здесь имеется наглядный веб-GUI, SQL-редактор и механизм автоматического перезапуска заданий. Однако, использование пользовательских Docker-образов Flink требует нескольких изменений в Docker-файлах и shell-скриптов.
Больше подробностей про администрирование и эксплуатацию Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://getindata.com/blog/flink-on-kubernetes-how-and-why/
- https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/deployment/resource-providers/standalone/kubernetes/
- https://github.com/lyft/flinkk8soperator
- https://martinfowler.com/bliki/BlueGreenDeployment/
- https://github.com/GoogleCloudPlatform/flink-on-k8s-operator

