 1142
1142 
Содержание
Сегодня рассмотрим важную тему из курсов для разработчиков и администраторов Apache Kafka: как сэкономить место на диске и увеличить пропускную способность всей Big Data системы на базе этой платформы потоковой обработки событий. Читайте далее, зачем добавлять задержку перед отправкой сообщений брокеру, как кодеки сжатия помогут снизить затраты на облачный Kafka-кластер и предупредить проблему нехватки места на жестком диске, а также чем AVRO лучше JSON.
Почему нужно уменьшать размер сообщений Kafka и как это сделать: 3 простых способа
Администраторы кластера Apache Kafka часто сталкиваются с отказами узлов по причине нехватки места на жестких дисках. Эта проблема возникает из-за сохранения сообщений в популярных форматах AVRO и JSON. В JSON-файле каждое поле модели данных хранится в строке из-за чего имена полей повторяются, увеличивая размер сообщения в топике Kafka. Несмотря на то, что хранение данных сегодня намного дешевле, чем 5-10 лет назад, есть несколько причин, почему все же следует сокращать потребление дискового пространства в Apache Kafka [1]:
- эффективная эксплуатация аппаратного обеспечения;
- увеличение количества сообщений, которые могут быть отправлены брокерам в рамках той же пропускной способности;
- снижение затрат на облачные сервисы, ценообразование которые рассчитывается на основе количества и объема передаваемых/хранящихся данных.
Сохранение данных в топике Kafka можно представить следующим образом:
- «полезные данные», т.е. непосредственно сама запись (record) в виде пары «ключ-значение»;
- упаковка нескольких записей в единый пакет (record batch) для передачи брокеру;
- служебные данные или накладные расходы пакета записей (record batch overhead) – 61 байт метаданных о записях (версия сообщения, количество записей, алгоритм сжатия, транзакция и пр).
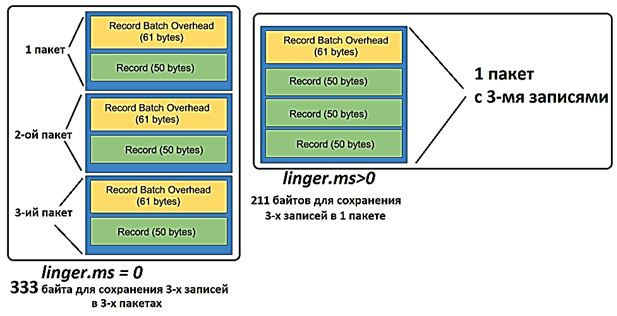
Накладные расходы на пакетную запись постоянны и не поддаются уменьшению. Однако, можно оптимизировать размер пакета записей тремя способами:
- задержка (lingering) перед отправкой сообщений в топики Kafka, чтобы объединить записи в пакет;
- сжатие данных (compression) с помощью различных кодеков – gzip, snappy и пр.;
- схема сериализации/десериализации для пар ключ-значение, из которых состоит сама запись, в частности, использование AVRO-формата вместо JSON.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
5 октября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Зачем настраивать linger.ms для продюсеров и при чем здесь размер метаданных
Как мы уже отмечали в недавней статье про отказоустойчивость продюсеров Kafka, параметр linger.ms входит в ТОП-10 важных конфигураций отправителя сообщений. Обычно продюсер группирует все записи, поступающие между передачами запроса, в один пакетный запрос, если сообщения приходят быстрее, чем могут быть отправлены. Уменьшить количество запросов можно, добавив искусственную задержку, чтобы вместо немедленной отправки записи продюсер ожидал какое-то время и упаковал несколько сообщений воедино. Параметр linger.ms задает верхнюю границу задержки для пакетной обработки: как только размер сообщений превысит заданный объем пакета batch.size, они будут отправлены немедленно. По умолчанию значение linger.ms равно 0, что означает немедленную передачу сообщений брокерам [2]. А, поскольку, при каждой записи в топик Kafka сообщение включает 61 байт служебной информации о метаданных, record batch overhead создается всякий раз при отправке данных от продюсера. Таким образом, задав ненулевое значение задержки linger.ms можно сократить количество этих накладных расходов и уменьшит передачу данных по сети, снизив количество байтов, отправляемых брокеру [1]. Подробнее про сценарии пакетной обработки и их реализацию в Apache Kafka читайте в нашей новой статье.
Сжатие данных: за и против
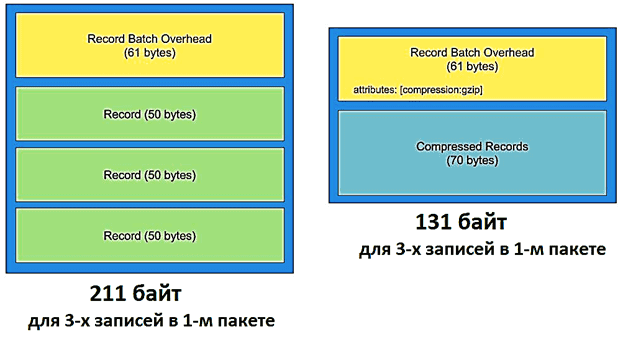
Сжатие помогает уменьшить объем данных, которые будут храниться на жестком диске или отправлены по сети за счет увеличения загрузки ЦП. Поэтому при использовании этого метода стоит помнить про компромисс между большим количеством операций ввода-вывода и загрузкой ЦП. Продюсер Kafka перед отправкой пакета записей брокеру может сжать данные, чтобы уменьшить размер пакета. Разумеется, сжимается только часть самих данных, а размер служебных метаданных не меняется, оставаясь равным 61 байт, куда также записывается бит флага для типа сжатия. Этот флаг будет использоваться во время распаковки данных на стороне потребителя. Подробнее о том, как устроено сжатие сообщений в Apache Kafka, читайте в нашей новой статье.
Алгоритмы сжатия особенно эффективны для данных с большим количеством дублирующейся информации. Например, в JSON-формате вероятно наличие полей с одинаковыми именами в соседних записях. Чем больше записей в пакете, тем сильнее данные будут сжаты. Поэтому продюсер Kafka сжимает все записи в одном пакете вместе вместо сжатия каждой записи по отдельности. Apache Kafka поддерживает различные алгоритмы сжатия, задать которые можно в конфигурации продюсера compress.type: gzip, snappy, lz4 и zstd. В примере для пакета с 3-мя записями по 50 байтов каждая алгоритм snappy сжал их общий размер более, чем в 2 раза: со 150 байт до 70 байт [1]. Обратной стороной такой оптимизации идет увеличение загрузки ЦП на стороне потребителя за счет распаковки сжатых данных.
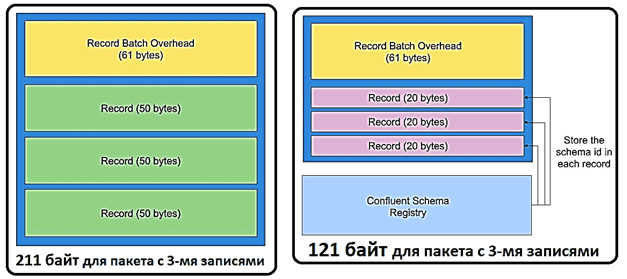
Почему Kafka любит формат AVRO
Использование схемы для хранения записей Kafka позволяет уменьшить их размер. Например, в хранение имени каждого поля вместе с данными увеличивает общий размер JSON-файла. А если хранить данные в формате AVRO, можно сохранить схему один раз и многократно использовать ее для создания записей. Удалить схему непосредственно из сообщения с возможностью обращения к ней позволяет реестр схем Kafka (Schema Registry), о котором мы рассказывали здесь. Поэтому, если внутри одного пакета не слишком много записей, формат Avro может значительно уменьшить размер сообщения [1].
Резюмируя все рассмотренные способы оптимизации сохранения сообщений в топиках Apache Kafka, можно сделать вывод, что наилучшие результаты дает искусственная задержка отправки с linger.ms, сжатие с помощью кодека gzip и использование AVRO-формата вместо JSON.
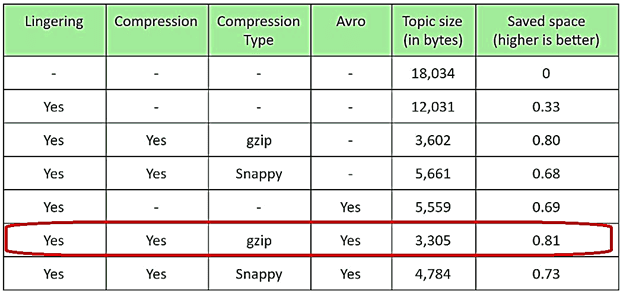
Читайте в нашей следующей статье о проблемах межкластерных транзакций в Apache Kafka и способах ее решения с помощью утилиты MirrorMaker и не только. А особенности хранения, потребления и очистки сообщений в топиках мы разбираем в этом материале.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

