 1272
1272 
Содержание
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим ключевые отличия графовых СУБД от реляционных, а также познакомимся с основами Neo4j и ее языком запросов — Cypher. Также вас ждет практический пример построения несложного графа средствами Cypher.
Когда графовые СУБД лучше реляционных и почему
Несмотря на достаточно активное использование NoSQL-технологий для хранения данных с разными структурами, реляционные базы до сих пор остаются самым популярным ИТ-инструментом. Реляционная СУБД, где данные структурированы в связанные таблицы, состоит из ограничений внешнего ключа и потому идеально подходит для обработки транзакций. Однако, если отношения между данными сложнее чем просто связи по ключу, а закономерности их связей неясны, реляционные СУБД становятся неэффективны.
В отличие от SQL-СУБД, графовые базы данных состоят из промаркированных вершин со свойствами, связанных между собой различными отношениями. Отношения постоянно хранятся в базе данных, что ускоряет обход графа и сокращает время вычислений. Это позволяет находить новые закономерности в данных и отвечать на сложные вопросы. При этом совсем не нужно знать точный вопрос, если есть все данные и пути их соединения. Именно поэтому графовые СУБД отлично подходят для исследований связей между данными, например, поиск сообществ в соцсетях, обнаружения мошенничества и формирование рекомендаций. Дополнительную ценность придает возможность визуализации отношений между данными с помощью специальных инструментов, например, Gephi [1]. Подробнее про архитектуру и ключевые принципы работы графовых СУБД читайте в нашей новой статье.
Чтобы обратиться к данным внутри графовой СУБД, используются специальные языки запросов, оптимизированные к парадигме представления данных в виде вершин и ребер графа. Как это работает, мы рассмотрим далее на примере базы данных Neo4j и ее языка запросов Cypher.
Графовая СУБД Neo4j и ее язык запросов Cypher: краткий ликбез
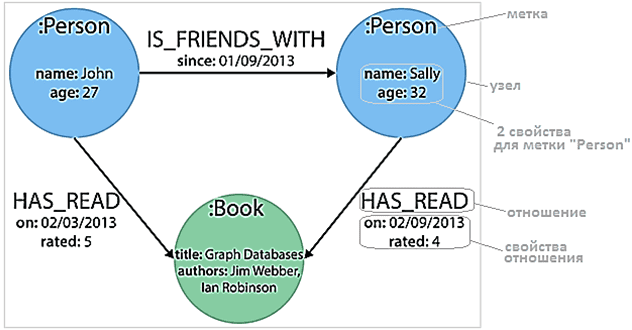
Граф Neo4j состоит из четырех компонентов [2]:
- Узлы (Nodes) – вершины графа, которые представляют объект или сущности. Их можно промаркировать.
- Отношения (Relationships) – связи между любыми двумя узлами. Отношения имеют тип и направление. Типы обеспечивают общую категорию для каждого отношения. Отношения однонаправленны и специфичны: каждый узел может иметь много отношений с другими узлами, чтобы полностью описать контекст.
- Метки или ярлыки (Labels), которые маркируют категорию узлов;
- Свойства (Properties) – конкретная информация каждого узла и отношения.
В качестве примера рассмотрим граф из 3-х узлов, каждый из которых промаркирован меткой с 2-мя свойствами. 2 промаркированных отношения, связывающие эти 3 узла («IS_FRINEDS_WITH» и «HAS_READ»), также имеют свойства, которые дают дополнительную информацию о контексте.
Cypher — это простой язык запросов, оптимизированный для графов, который определяет и использует отношения данных. Он исследует взаимосвязи во всех направлениях, чтобы обнаружить ранее невидимые отношения и кластеры. Хотя команды Cypher немного похожи на SQL , в некоторых случаях они отличаются. Например, инструкция CREATE (n: Person) создаст узел с меткой «Человек» (Person). Если нужно обратиться к этому узлу позже, можно сохранить его в переменной, назвав ее по своему усмотрению, и ссылаться на нее по мере необходимости.
В отличие от SQL-оператора SELECT, который используется для просмотра данных в реляционных СУБД, в Cypher применяется инструкция MATCH, которая сопоставит и вернет все узлы в базе данных. А RETURN указывает, какой результат мы хотим от нашего запроса. Это могут быть узлы, отношения или свойства. Так что это требуется только во время процедуры чтения. Обратите внимание, что здесь необходимо указать переменную, иначе запрос ничего не вернет.
Например, Cypher-код
MATCH (n: Person {name: “Sally”})
RETURN (n)
вернет все узлы с меткой «Человек» с именем Салли. А если вместо возвращения всего узла, нужны его отдельные свойства, их следует указать в инструкции RETURN, например, RETURN (n.name).
Также, подобно SQL, можно использовать условие WHERE для фильтрации запросов, например:
MATCH (n: Person) WHERE n.age>=18 AND n.age<=60 RETURN (n)
Аналогичным образом можно обращаться к отношениям, а также строить сложные запросы с условным поиском отношений между узлами. Вызов db.schema.visualization() покажет все типы отношений между узлами в графе [2].
Примечательно, что Cypher можно использовать и в Apache Spark, чтобы отобрать нужные наборы данных графа из всего объема и сохранить их как новый граф в Neo4j в реальном времени или записать в Hadoop HDFS для пакетной обработки. Также библиотека Cypher для Apache Spark представляет разработчику множество полезных функций [3]:
- сохранение результатов запросов в виде графов в дополнение к базовому табличному представлению в Cypher. Это позволяет создавать сложные запросы, связанные друг с другом в функциональной цепочке графовых алгоритмов. Поддержка нескольких графов позволяет запросам возвращать конкретные графы, которые содержат данные для определенного домена, определенных пользователем разделов или логических СУБД.
- Path Control позволяет пользователю контролировать уникальность пути при определении типов обхода графа по определенным шаблонам;
- регулярные выражения пути применяют синтаксис регулярных выражений, кратко формулируя сложные шаблоны пути при извлечении субграфов с использованием языка GXPath.
В следующий раз мы рассмотрим пример использования Neo4j и Cypher для анализа данных о путешествиях цифровых кочевников. О том, как связать Neo4j с Apache Spark, читайте здесь, а о том, как создать Cypher-запрос к этой графовой СУБД из простого текста с помощью языка разметки Aspen — здесь. Про библиотеку Graph Data Science мы рассказываем в новой статье. А освоить практику применения Apache Spark, Neo4j и Cypher для разработки распределенных приложений и графовой аналитики больших данных вы сможете на курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://payodatechnologyinc.medium.com/what-and-why-of-graph-databases-b3b70ec75c99
- https://payodatechnologyinc.medium.com/diving-into-neo4j-and-its-query-language-cypher-eee6cce6b2af
- https://ru.bmstu.wiki/Cypher_Query_Language

