 1248
1248 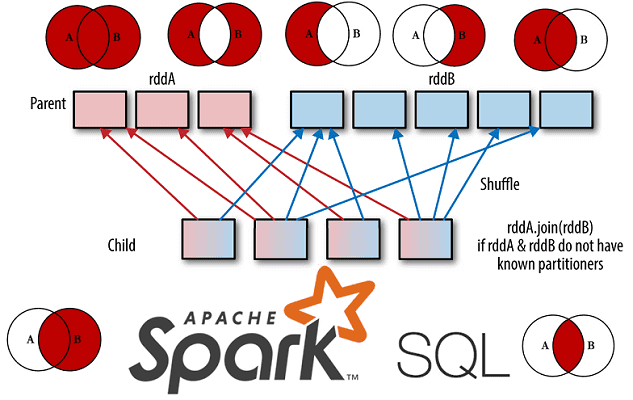
Содержание
Развивая наши новые курсы по Apache Spark, сегодня мы рассмотрим Join-операции в SQL-модуле этого популярного фреймворка для аналитики больших данных. Читайте далее, чем отличаются разные Join-соединения друг от друга, как они реализуются в Spark SQL, какие существуют механизмы для их выполнения и от чего зависит выбор того или иного способа объединения двух наборов Big Data в разных ситуациях.
Основы Join-операций и 3 важнейших аспекта их реализации в Spark SQL
Для начала напомним, как устроены операции соединения через SQL-оператор JOIN и какие они бывают не только в Apache Spark, а вообще. Join предполагает, что каждая запись одного из двух наборов входных данных (таблиц) сопоставляется с каждой другой записью другого набора. В случае совпадения в соответствии с заданным условием JOIN-операция выводит объединенную запись, которая обычно представляет собой комбинацию отдельных сопоставляемых записей из обоих наборов данных. Выполнение операции соединения в Apache Spark зависит от следующих аспектов [1]:
- размер наборов входных данных напрямую влияет на эффективность выполнения и надежность JOIN-соединения;
- условие соединения (clause) – логическое сравнение атрибутов, принадлежащих наборам входных данных. В зависимости от условия соединения, Join-операции делят на эквивалентные (Equi Joins) и неэквивалентные (Non-Equi Join). Equi Join включает одно или несколько условий равенства, которые должны выполняться одновременно. Каждое из них применяется к атрибутам из двух наборов входных данных. Например, (A.x == B.x) или ((A.x == B.x) и (A.y == B.y)) являются условиями Equi Join для атрибутов x и y в двух наборах входных данных, A и B, которые участвуют в операции соединения. Примечательно, что EQUI не является ключевым словом SQL, а просто обозначает специальный вариант записи особого случая типа INNER JOIN, о котором мы поговорим далее. Однако, не совсем корректно называть EQUI JOIN особым случаем, поскольку на практике эта операция чаще всего выполняется путем объединения таблиц на основе отношения первичного/внешнего ключа [2]. Неэквивалентные соединения могут допускать несколько условий равенства, которые не должны выполняться одновременно. В частности, (A.x<B.x) или ((A.x == B.x) и (A.y == B.y)) являются двумя примерами условий неэквивалентного соединения для атрибутов x и y в двух наборах входных данных, A и B, которые соединяются через JOIN.
- тип соединения, который влияет на результат JOIN-операции после применения условия соединения записей входных наборов данных. Обычно типы JOIN-соединения классифицируются следующим образом:
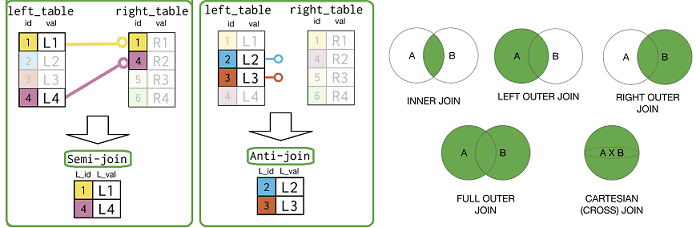
- внутреннее соединение (Inner Join) – выводит только совпавшие по условию соединения объединенные записи из входных наборов данных;
- внешнее соединение (Outer Join) – в дополнение к сопоставленным соединенным записям также выводит несоответствующие записи. Outer Join дополнительно делят на левое, правое и полное, в зависимости от набора входных данных для вывода несовпадающих записей.
- полу-соединение (Semi Join) – выводит отдельную запись, принадлежащую только одному из двух входных наборов данных в совпавшем или в несоответствующем экземпляре. Если запись, принадлежащая одному из входных наборов данных, выводится в несоответствующем экземпляре, Semi Join также называется Anti Join.
- перекрестное соединение (Cross Join) – выводит все соединенные записи, которые возможны путем соединения каждой записи из одного набора входных данных с каждой записью другого набора входных данных.
Отметим, что в ядре фреймворка (Spark Core) стоит обращать внимание на порядок операций, поскольку DAG-оптимизатор, в отличие от SQL-оптимизатора, не может изменять порядок фильтров или сокращать их. В Core Spark Join-соединения являются дорогостоящими, поскольку требуют, чтобы соответствующие ключи от каждого RDD располагались в одном разделе, чтобы их можно было объединить локально. Иначе их необходимо перемешать, чтобы данные с одинаковыми ключами находились в одних и тех же разделах. Это поможет избежать передачи данных по сети. Как и в случае с большинством key-value операций, стоимость соединения возрастает с увеличением количества ключей и расстояния, которое должны пройти записи, чтобы добраться до их нужного раздела. Spark SQL поддерживает те же базовые типы соединений, что и ядро фреймворка, но оптимизатор берет на себя большую часть работы, что лишает разработчика полного контроля. Например, Spark SQL может сам изменить порядок операций, чтобы сделать соединения более эффективными [3].
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
6 апреля, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
5 механизмов выполнения операций соединения в Apache Spark SQL
Разобравшись с основными аспектами выполнения Join-операции, рассмотрим механизмы их выполнения в Apache Spark SQL [1]:
- Широковещательный хеш (Broadcast Hash), где один из двух входных наборов данных транслируется всем исполнителям, для каждого из которых строится хеш-таблица. Далее каждый раздел не транслируемого входного набора данных присоединяется независимо к другому набору данных, доступному в виде локальной хеш-таблицы. Это не требует перетасовки и является наиболее эффективным, однако исполнители должны иметь достаточно памяти для размещения транслируемого набора данных. Поэтому на практике Apache Spark избегает этого механизма, если оба набора входных данных превышают настраиваемый порог.
- Перемешанный хеш (Shuffle Hash), где два набора входных данных выравниваются по выбранной схеме разделения (партиционирования). Если один или оба набора входных данных не соответствуют выбранной схеме разделения, операция перемешивания выполняется перед фактическим соединением для достижения соответствия. После того, как оба набора входных данных соответствуют выбранному выходному разделению, Shuffle Hash выполняет соединение для каждого выходного раздела, используя стандартный подход Hash Join. При этом для каждого выходного раздела хеш-таблица сначала создается из меньшего входного набора данных, а затем соответствующий раздел большего входного набора данных присоединяется к построенной хеш-таблице. По сравнению с Broadcast Hash Join, требования к памяти исполнителей меньше в случае Shuffle Hash Join, т.к. хеш-таблица строится только на определенном разделе меньшего набора входных данных. Поэтому при большом количестве выходных разделов и исполнителей с достаточным объемом памяти, Shuffle Hash Join будет весьма эффективным. Однако, если Spark потребуется выполнить дополнительную операцию перемешивания для одного или обоих входных наборов для соответствия разделению выходных данных, предпочтительнее ранее рассмотренный Broadcast Hash Join.
- Сортировка через слияние (Sort Merge), которая похожа на Shuffle Hash Join. Здесь также два набора входных данных выравниваются по выбранной схеме разделения выходных данных. Если один из них или оба не соответствуют выбранной схеме разделения, операция перемешивания выполняется до фактического соединения, чтобы обеспечить нужное соответствие. После того, как соответствие выбранному выходному разделению для обоих входных наборов данных достигнуто, Sort Merge выполняет операцию соединения для каждого выходного раздела, используя стандартный подход Sort Merge Join. Он вычислительно менее эффективен по сравнению с Shuffle Hash Join и Broadcast Hash Join однако требования к памяти исполнителей значительно ниже. Как и Shuffle Hash Join, если входные наборы данных не соответствуют желаемому разделению выходных данных, то операция перемешивания входов увеличивает накладные расходы.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
- Декартово соединение (Cartesian), которое используется исключительно для выполнения перекрестного соединения между двумя наборами входных данных. Количество выходных разделов всегда равно произведению количества разделов входного набора данных. Каждый выходной раздел сопоставляется с уникальной парой разделов, каждая пара состоит из одного раздела одного и другого раздела второго набора данных. Для каждого из выходных разделов результат вычисляется как декартово произведение данных из двух входных разделов, сопоставленных с выходным разделом. Недостаток этого механизма в том, что Cartesian Join увеличивает количество выходных разделов. Однако, он является единственным, если требуется Cross- соединение.
- Широковещательное соединение вложенного цикла (Broadcast Nested Loop), где один из входных наборов данных транслируется всем исполнителям. После этого каждый раздел не транслируемого набора входных данных присоединяется к транслируемому набору с использованием стандартной Join-процедуры с вложенным циклом, чтобы произвести объединенные выходные данные. С вычислительной точки зрения Broadcast Nested Loop Join наименее эффективен, поскольку для сравнения двух наборов данных выполняется вложенный цикл. Кроме того, это требует большого объема памяти, т.к. один из наборов входных данных должен транслироваться всем исполнителям. Подробнее про это читайте здесь.
Таким образом, Apache Spark SQL выбирает конкретный механизм для выполнения Join-операции на основе следующих факторов:
- параметры конфигурации
- присоединиться к подсказкам
- размер наборов входных данных
- тип соединения
- условие соединения (Equi или Non-Equi Join).
Чтобы обеспечить гибкость настроек для завершения механизма соединения, Join API в Apache Spark SQL Spark предоставляет так называемые подсказки (hints): broadcast, merge, shuffle_hash и shuffle_replicate_nl. В частности, Broadcast Hash Join применим только к условию Equi Join и не применим к типу Full Outer Join. Broadcast предоставляется в левом наборе входных данных при типах соединения Right Outer, Right Semi или Inner: левый входной набор данных может быть передан в широковещательном режиме в соответствии с конфигурацией spark.sql.autoBroadcastJoinThreshold, которая по умолчанию равна 10 МБ. Аналогично для правого набора входных данных, но с типом соединения Left Outer, Left Semi или Inner [1]. Подробнее об этом читайте в нашей новой статье.
Разумеется, нужный механизм выполнения операций соединения не является единственным методом оптимизации таких SQL-запросов. К примеру, в источнике [4] приведен интересный кейс по оптимизации соединений в Apache Spark с использованием UDF-функции withColumn(), которая добавляет новый столбец в DataFrame, изменения значения существующего. Это позволило сократить время исполнения запроса более чем в 10 раз, с 90 до 7 минут. Про особенности JOIN-операций с потоками больших данных в Apache Spark Structured Streaming читайте в нашей новой статье. А почему в левом внешнем соединении могут отсутствовать ожидаемые записи, мы рассказываем здесь.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Узнайте больше про особенности Apache Spark SQL для аналитики больших данных и разработки распределенных приложений на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- https://towardsdatascience.com/demystifying-joins-in-apache-spark-38589701a88e
- http://datareview.info/article/8-sposobov-obedineniya-join-tablic-v-sql-chast-1/
- https://www.oreilly.com/library/view/high-performance-spark/9781491943199/ch04/
- https://flomin-dan.medium.com/optimizing-your-spark-joins-in-an-unfashionable-manner-e273ede0ca13

