 1236
1236 
Содержание
Один из факторов повышенной надежности Apache Kafka обеспечивается записью сообщений на жесткий диск. Однако, операции ввода-вывода (IO, input-output) с дисковым пространством считаются медленными и часто являются узким местом во всей системе. Спустившись на уровень операционной системы и ядра, сегодня рассмотрим, как Kafka справляется с этим ограничением, позволяя быстро обрабатывать огромные объемы данных в режиме реального времени.
Слишком много копий: традиционная передача данных по сети
Брокер Kafka можно рассматривать как процесс JVM, выполняющийся на машине, которая обслуживает запросы хранения и выборки данных от клиентов – производителей (producer) и потребителей (consumer). Сами данные хранятся в определенных каталогах, определенных в log.dirs, которые обычно представляют собой список точек монтирования диска конкретного узла кластера, т.е. брокера Kafka. Чтобы обеспечить высокую скорость операций записи на диск и чтения, Kafka использует не классическую передачу данных, а технологию под названием «Zero-copy» [1], когда ЦП не копирует данные из одной области памяти в другую, а работает с прямым доступом к памяти (DMA, direct memory access) и отображением в памяти (memory mapping) [2], а также со страничным кэшем. Далее мы рассмотрим, как это устроено.
Напомним, чтобы прочитать файл с жесткого диска и отправить его по сети, традиционная передача данных использует 4 переключения контекста между пользовательским режимом (контекст приложения) и режимом ядра (контекст ядра). Это означает, что непосредственное копирование данных будет выполнено 4 раза, включая следующие этапы [1]:
- Вызов File.read() переключает контекст из пользовательского режима в режим ядра, и копирование данных выполняется DMA-механизмом, который считывает содержимое файла и сохраняет его в буфер адресного пространства ядра;
- Данные из буфера адресного пространства ядра копируются в пользовательский буфер (буфер приложения), возвращая результат вызова File.read() и переключая контекст обратно в пользовательский режим;
- Вызов Socket.send() переключает контекст в режим ядра, где выполняется третье копирование данных из пользовательского буфера в буфер ядра. Возврат вызова Socket.send() вновь переключает контекст в пользовательский режим.
- Четвертая копия данных выполняется механизмом DMA, передавая данные из буфера ядра (буфера сокета) в буфер контроллера сетевого интерфейса (NIC, network interface controller), чтобы отправить их по сети.
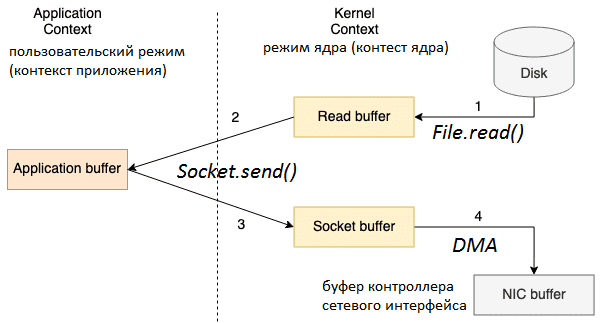
Если размер запрашиваемых данных превышает размер буфера ядра, между ядром и пользовательским пространством, копий будет еще больше. Уменьшить количество операций копирования можно с помощью технологии Zero-copy, которую мы рассмотрим далее.
Нулевое копирование и сетевая передача данных в UNIX-системах
Нулевое копирование выполняется без второй и третьей копий данных за счет непосредственной передачи из буфера чтения в буфер сокета. В UNIX-подобных операционных системах такая оптимизированная передача данных обрабатывается системным вызовом sendfile(), который копирует данные между двумя файловыми дескрипторами [1]. Производительность повышается благодаря переходу ЦП к другим задачам во время копирования данных, которое выполняется параллельно в другой части машины, и снижения переключений контекста (между режимами ядра и пользователя). Эффективность использования системных ресурсов растет, т.к. ЦП применяется для сложных вычислительных задач, а не простых операций копирования [2].
Системный вызов sendfile() копирует данные между одним дескриптором файла и другим сразу внутри ядра, что намного эффективнее комбинации вызовов read() и write(), требующих передачи данных в пользовательское пространство и чтения из него.
Что касается передачи данных по сети, то sendfile() можно использовать и для отправки файлов в сокет TCP. Если необходимо сперва отправить данные заголовка перед содержимым файла, пригодится параметр TCP_CORK протокола TCP, чтобы минимизировать количество пакетов и настроить производительность [3].
Таким образом, JVM-приложение должно использовать метод transferTo() класса FileChannel, который вызывает системный вызов, если нулевое копирование поддерживается базовой операционной системой. Так вызов FileChannel.transferTo() сокращает количество переключений контекста в 2 раза: с 4 до 2-х, также уменьшая количество копий. Если контроллер сетевого интерфейса не поддерживает операции агрегации данных, как в версиях ядрах Linux до 2.4, то потребуется выполнить копирование из буфера чтения в буфер сокета. Но оба этих буфера относятся к контексту ядра и обрабатываются механизмом DMA, а потому выполняются быстро. Если NIC поддерживает операции агрегации, в буфер сокета записываются только дескрипторы с информацией о местоположении и длине данных, а сами данные передаются непосредственно из буфера чтения в сетевой адаптер [1].
Сетевая передача и запись данных на диск в Apache Kafka
Для обеспечения высокой скорости записи и чтения данных, Apache Kafka активно использует страничный кэш операционной системы для хранения недавно использованных данных. Напомним, в страничном кэше (page cashe) содержатся страницы памяти, полностью заполненные данными из файлов, к которым только что производился доступ. Перед выполнением операции страничного ввода-вывода, например, read(), ядро проверяет наличие данных, которые нужно считать, в страничном кэше. Если они там присутствуют, то ядро может быстро возвратить требуемую страницу памяти [4].
Таким образом, несмотря на то, что Apache Kafka записывает сообщения на жесткий диск, а не оперирует данными в памяти, в отличие от Spark, ей важен объем ОЗУ на узлах-брокерах. Страничный кэш находится в неиспользуемых частях ОЗУ и используется для хранения страниц данных, которые были недавно прочитаны или записаны на диск. Дополнительный рост скорости обеспечивает стандартизированный двоичный формат сообщений, единый для продюсера, брокера и потребителя: данные от продюсера к брокеру передаются и сохранятся там как есть, без каких-либо изменений, отправляясь потребителям по запросу.
При этом, когда брокер получает данные от продюсера, они немедленно записываются в постоянный журнал файловой системы, но не сразу записываются на диск. Данные будут перенесены в страничный кэш ядра, и операционная система будет решать, когда произвести очистку в зависимости от настроенных параметров ядра vm.dirty_ratio, vm.dirty_background_ratio и vm.swappiness.
Так благодаря технологии zero-copy в Apache Kafka, данные копируются в страничный кэш строго однократно и повторно используются при каждом использовании вместо хранения в памяти и копирования в пользовательское пространство при каждом чтении. Это позволяет использовать сообщения со скоростью, близкой к пределу сетевого подключения. А комбинация страничного кэша и системного вызова sendfile() означает, фактическое отсутствие дисковых операций в кластере Kafka, из-за того, что потребители, в основном, будут работать с данными из кэша.
Получается, в случае 3-х потребителей с разными group.id, запрашивающих данные из конкретного топика на брокере будут скопированы с диска в страничный кэш только один раз и отправлены по сети каждому потребителю. А если в этот топик недавно были записаны сообщения, то чтение с диска не потребуется, т.к. эти данные будут присутствовать в страничном кэше. Причем операции записи и чтения для раздела топика обрабатываются только его лидером, а записи продюсеров записываются в сегмент файла только для добавления (append-only segment file). И частые операции чтения и записи в одном и том же топике Kafka будут быстрыми, поскольку эти файловые сегменты будут в страничном кэше.
В заключение рассмотрим связь SSL-шифрования с технологией и нулевое копирование. Поскольку SSL позволяет шифровать данные на лету, то по сети передаются не совсем те же данные, что хранятся на брокере Kafka. Поэтому при включении SSL технология zero-copy теряется, т.к. брокеру необходимо расшифровать и зашифровать данные. Таким образом, повышение уровня безопасности с помощью SSL-шифрования приведет к некоторому росту накладных расходов и снижению производительности Apache Kafka [1].
Еще больше тонкостей администрирования кластеров Apache Kafka и использования этого фреймворка для разработки распределенных приложений потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://andriymz.github.io/kafka/kafka-disk-write-performance/
- https://ru.wikipedia.org/wiki/Zero-copy
- https://man7.org/linux/man-pages/man2/sendfile.2/
- https://it.wikireading.ru/1948

