 1493
1493 
Содержание
Пропускная способность информационной системы на базе Apache Kafka говорит о том, сколько данных могут быть обработаны за определенный период времени. Несмотря на потоковую передачу событий, здесь работает классический закон обратной зависимости скорости обработки данных от их объема. Разбираемся, как найти баланс между производительностью и задержкой.
Еще раз о пропускной способности Apache Kafka: 2 конфигурации продюсера
Мы уже писали, что пакетные сообщения позволяют приложению-продюсеру Kafka повысить пропускную способность всей системы потоковой передачи событий за счет сокращения количества сетевых запросов при отправке данных. Но платой за это является рост задержки. По сути, оптимизация пропускной способности предполагает увеличение объема данных, пересылаемых между продюсерами и потребителями Kafka в течение заданного периода времени. Есть несколько способов увеличить пропускную способность распределенного приложения при использовании Kafka в качестве брокера обмена сообщениями:
- изменение количества разделов топика;
- сжатие сообщений;
- выделение дополнительной памяти;
- регулирование параметров подтверждения отправки (acks) в конфигурациях продюссера.
Также можно объединить сообщения, публикуемые в едином разделе топика Kafka, в один запрос, что мы и рассмотрим далее. Отправка того же объема данных за меньшее количество запросов, хотя и с большими размерами пакетов, повышает производительность как клиента, так и сервера. Снижается нагрузка на продюсеров и на ЦП для обработки меньшего количества запросов.
Чтобы объединить сообщения в пакет, приложение-продюсер должно подождать настраиваемый период времени, пока собираются сообщения для отправки. Это время ожидания и является той самой задержкой, за счет повышения которой растет пропускная способность всей системы. Сообщения считываются потребителем пакетами по мере того, как он опрашивает раздел топика Kafka.
В конфигурации продюсера Kafka за пакетирование сообщений отвечают следующие параметры:
- size — размер пакета, в который объединяются сообщения для записи в Kafka, является пороговым значением, которое после достижения или превышения которого начинается отправка пакетного запроса. По умолчанию значение batch.size равно 16 КБ (16384 байта)
- ms — время задержки в миллисекундах перед отправкой сообщений в топик Kafka, чтобы объединить записи в пакет. Этот параметр задает верхнюю границу задержки для пакетной обработки: как только размер сообщений превысит заданный объем пакета batch.size, они будут отправлены немедленно. По умолчанию значение linger.ms равно 0, что означает немедленную передачу сообщений брокерам.
Настройка большего размера пакета обычно приводит к тому, что отправляется меньше запросов. Продюсер будет ожидать количество миллисекунд, заданное в linger.ms, перед упаковкой сообщений в пакет для отправки в топик Kafka.
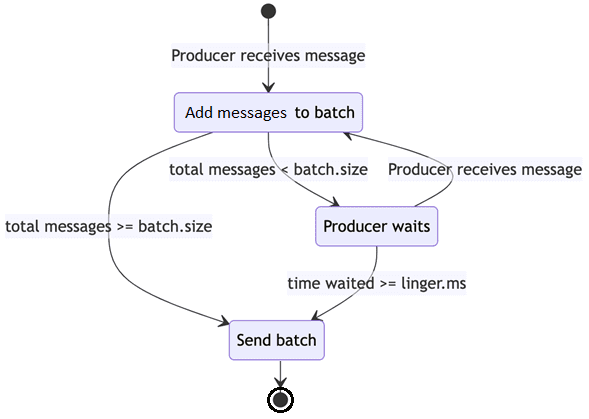
Получается, если задать ненулевое значение задержки linger.ms, можно сократить количество этих накладных расходов и уменьшить передачу данных по сети, т.к. снижается количество байтов, отправляемых брокеру. Однако, если приложение создает меньший объем данных, размер пакета batch.size может быть не достигнут в течение периода времени, заданного в linger.ms. Если размер пакета не достигается в настроенном окне, возникает дополнительная задержка, поскольку продюсер откладывает отправку каждого запроса. Продюсер может просто пытаться опубликовать одно сообщение в этом окне, и в этом случае размер пакета batch.size будет равен единице. В этом случае с linger.ms, установленным в 5 миллисекунд, возникнет задержка в 5 миллисекунд для этой и любой подобной отправки. Таким образом, чтобы определить оптимальные значения для конфигураций Kafka-продюсера batch.size и linger.ms, необходимо учитывать несколько факторов, о которых мы поговорим далее.
Тонкости настройки и тесты производительности
Итак, объем создаваемых сообщений и их фактические размеры являются ключевыми факторами для настройки пропускной способности Kafka. Также важны количество разделов в топике и наличие в сообщениях ключа. Если продюсер отправляет сообщения циклическим перебором в разные разделы, они будут группироваться в отдельные запросы, что замедляет достижение пакетом значения, заданного в конфигурации batch.size.
Если используется ключ сообщения, который обеспечивает запись сообщений в один и тот же раздел, и в окне linger.ms будет создано много таких сообщений, они будут объединены в пакет. Для сообщений с нулевым ключом можно использовать доступную с версии 2.4 стратегию «липкого разделителя» (Sticky Partitioner), чтобы гарантировать, что сообщения группируются вместе и отправляются в один раздел. Затем следующий пакет для сообщений с нулевым ключом может быть отправлен в другой раздел, чтобы обеспечить равномерное распределение нагрузки с оптимальной пакетной обработкой. Подробнее об этом мы рассказывали здесь.
Если источник данных также использует сжатие сообщений, это тоже повлияет на время достижения предела batch.size, поскольку размеры сообщений становятся меньше. Помимо риска возникновения задержки при настройке большего размера пакета во время его наполнения, необходимо выделить больше памяти для обработки сообщения. С другой стороны, небольшой размер пакета или небольшое окно, заданное в linger.ms, могут снизить пропускную способность по мере увеличения количества запросов на создаваемые сообщения. В частности, linger.ms, по умолчанию установленный в 0, почти отключает пакетную обработку, хотя не полностью обеспечивает 100% real time из-за времени, нужного для создания и отправки запроса продюсером.
Чтобы сравнить, какие оптимальные значения параметров конфигурации могут быть установлены, можно провести экспериментальное тестирование с библиотекой микробенчмаркинга JMH. JMH Microbenchmarking предоставляет средства для запуска эталонных тестов производительности пользовательского кода. Она имеет подробную документацию с множеством наглядных примеров. В частности, для приложений Kafka есть возможность запускать тесты в контексте Spring Boot, чтобы тестировать отдельные компоненты по мере их запуска в рабочей среде. Это дает все преимущества автосвязывания Spring, чтобы извлекать компоненты так же, как это делает приложение, например, полностью настроенный источник данных, без необходимости самостоятельной разработки всего шаблонного кода.
Также с JMH Microbenchmarking можно создать проект, чтобы упростить тестирование производительности SQL-запросов и увидеть эффект даже их небольших изменений, таких как добавление или удаление условий WHERE или сортировок ORDER BY, а также индексы в базе данных. Например, добавление индекса для повышения производительности чтения может происходить за счет записи в ту же таблицу. Также можно проанализировать влияние добавления одного индекса на два столбца по сравнению с добавлением одного составного индекса ключа на столбцы.
Для проверки гипотез о влиянии параметров конфигурации на пропускную способность Apache Kafka с помощью библиотеки JMH Microbenchmarking можно создать и запустить тесты на генерацию сообщений с различными значениями batch.size и linger.ms. Тесты должны отправлять сообщения ожидаемого размера и с ожидаемой нагрузкой, отражающей производственную, чтобы получить объективную основу для настройки этих параметров в реальных условиях для достижения максимальной пропускной способности при минимальной задержке.
Таким образом, использование пакетной обработки сообщений в продюсерах Kafka – отличный способ оптимизации пропускной способности всей системы потоковой передачи событий. Но стоит помнить, что повышение пропускной способности может привести к росту задержки передачи данных, поэтому администратору Kafka-кластера и дата-инженеру важно понимать количество и размер сообщений, чтобы правильно настроить параметры продюсера, ответственного за пакетную обработку. Как это было использовано в кейсе Walmart, читайте в нашей новой статье. А здесь вы узнаете, как повысить пропускную способность интеграционной платформы Kafka Connect.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

