 1002
1002 
Содержание
Рассматривать обучение Кафка интереснее на практических примерах. Сегодня мы расскажем, как Apache Kafka применяется в одной из крупнейших промышленных компаний России — ПАО «Северсталь». Эта статья написана на основе выступления Доната Фетисова, главного архитектора «Северсталь Диджитал». Доклад был представлен 7 декабря 2019 года на очередном ИТ-митапе компании Авито по Big Data системам и микросервисам, «Backend United #5: Шаурма».
Цифровизация, АСУТП, IIoT, Big Data и другие ИТ-вызовы современного завода
Начнем с того, что ПАО «Северсталь» — это настоящий промышленный гигант, одна из ведущих вертикально-интегрированных горнодобывающих и сталелитейных компаний в мире. Основные активы предприятия сосредоточены в России, а также на Украине, в Латвии, Польше, Италии и Либерии. Организация производит высококачественный металлопрокат и стальные трубы для строительства, машиностроения, автомобильной и нефтегазовой отраслей. Также ПАО «Северсталь» — это один из крупнейших отечественных производителей железной руды и коксующего угля [1]. Таким образом, это предприятие – классический пример современного завода, где особенно востребованы системы промышленного интернета вещей (Industrial Internet of Things, IIoT). Стоит отметить некоторые особенности производства, которые определяют специфические требования к ИТ-решениям:
- многообразие данных и их большие объемы – Big Data;
- высокая скорость поступления телеметрии и необходимость ее процессинга в реальном времени – потоковая обработка событий;
- обилие автоматизированных систем управления технологическими процессами (АСУТП);
- сложное и разнообразное оборудование;
- необходимость поддерживать высокое качество всего ассортимента продукции;
- большое количество точек, где потенциально может возникнуть дефект;
- непрерывность производственной деятельности в режиме 24/7;
- тесная взаимосвязь технологических и бизнес-процессов – влияние экономики на загрузку производственных мощностей, складские запасы, реализацию и наоборот.
С учетом вышеотмеченных особенностей, ПАО «Северсталь» выделило следующие направления ИТ-проектов для эффективного управления собственным производством и бизнесом [2]:
- предиктивные ремонты технологического оборудования – предсказания и детектирования поломок, а также рекомендации по обслуживанию;
- управление качеством стали – заблаговременное предсказание и детектирование дефектов, а также выявление причин их возникновения;
- автоматизация процессов принятия решения (от технических до управленческих) с помощью советников по технологиям, например, в процессах сушки концентрата, производства окатышей и чугуна, мониторинга качества лома и пр.;
- увеличение объемов производства – унификация продукции и ускорение производственных циклов;
- управление человеческими ресурсами – предупреждение травматизма и снижение текучки кадров.
Таким образом, цифровизация ПАО «Северсталь» включает следующие задачи [2]:
- сохранение как можно большего количества данных во всех активах;
- построение и внедрение моделей машинного обучения (Machine Learning, ML) во всех производственных процессах;
- замена человеческих экспертных мнений решениями, основанными на статистике и ML.
Разумеется, это далеко не весь список компонентов цифровой трансформации, направленной на переход к Industry 4.0 (I4.0). Но данная статья, в первую очередь, посвящена сценариям применения Apache Kafka в промышленном производстве. Поэтому другие темы цифровой трансформации «Северстали» (цифровые двойники, проекты виртуальной реальности, корпоративное озеро данных Data Lake на базе Hadoop и прочие элементы I4.0 [3]) мы рассмотрим отдельно.

4 основных кейса использования Apache Kafka в задачах цифровизации Северстали
В ПАО «Северсталь» Кафка наиболее часто используется следующим образом [2]:
- в качестве протокола взаимодействия между микросервисами;
- как средство сбора и агрегации потоковых изображений с камер видеонаблюдения;
- для оперативного хранения данных с производственных площадок;
- как инструмент сбора и визуализации метрик SCADA-приложений, а также управления технологическими процессами.
Таким образом, на декабрь 2019 года к Kafka в Северстали было подключено 5 активов, более 40 источников данных, которые продуцировали свыше 300 тысяч сигналов объемом около 1М сообщений в секунду или примерно 800 гигабайт в сутки. Таким образом, Кафка помогает наполнять производственной информацией корпоративное озеро данных (Data Lake) на Hadoop-кластере, чтобы строить модели предиктивной аналитики [4]. На сегодняшний день это гибридное хранилище информации емкостью 2 петабайта считается крупнейшим среди промышленных компаний России. Согласно текущим планам цифровизации Северстали, оно должно заполниться в течение 5 лет [3]. Пока в Data Lake на базе Apache Hadoop предприятия накоплено около 220 терабайт (в HDFS) и более 200 таблиц в Hive [2].
Отметим некоторые особенности Кафка в рассматриваемом примере [2]:
- дистрибутив Kafka Confluent с поддержкой от вендора;
- для хранения схем данных используется Schema registry;
- для загрузки данных в HDFS и InfluxDB применяется Kafka Connect – компонент с открытым исходным кодом, платформой для соединения Кафка с внешними системами (базы данных, хранилища ключей, поисковые индексы и файловые системы);
- потоковая обработка данных, например, изображений с камер видеонаблюдения для детектирования дефектов и разрывов цепи конвектора, используется Kafka Streams. Напомним, эта клиентская библиотека позволяет создавать распределенные приложения и микросервисы потоковой обработки событий в реальном времени, когда входные и выходные данные хранятся в кластерах Кафка. В частности, в Северстали Kafka Streams помогает выполнять фильтрацию и агрегацию потоковых данных по фиксированному времени и произвольным триггерам (событиям).
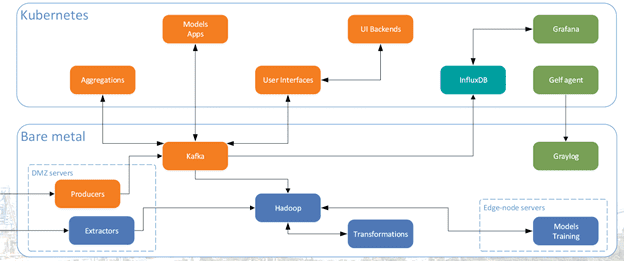
Таким образом, Кафка, по сути, стала одним из основных технических инструментов цифровизации для Северстали . Эта распределенная Big Data платформа интегрирована с IIoT-датчиками, покупными SCADA-системами, собственными АСУТП-решениями, корпоративными информационными системами и базами данных, в частности, Oracle DB и WinCC. Благодаря интерактивному сбору производственных данных в топики Kafka строятся модели машинного обучения для своевременного выявления брака продукции и предупреждения поломок оборудования. Визуализация данных, таких как производственные метрики от SCADA-систем, представлена с помощью Grafana, а за хранение временных рядов отвечает InfluxDB. Для ускорения и унификации процессов разработки и развертывания активно используются DevOps-технологии контейнеризации: Docker, Kubernetes. Корпоративное озеро данных, как мы уже отметили выше, реализовано на кластере Apache Hadoop.
В следующей статье мы продолжим рассматривать опыт компании «Северсталь», разбирая чем отличается директор по цифровизации от CDO и CIO. А как построить собственное IIoT-решение на базе Apache Kafka и эффективно запустить цифровую трансформацию своего бизнеса вы узнаете, пройдя обучение Кафка на специализированных практических курсах в «Школе Больших Данных» — лицензированном учебном центре для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

