 1723
1723 
Содержание
В этой статье разберем одну из тем практического обучения администраторов Apache Kafka и рассмотрим разницу между сохранением сообщений и фиксированных смещений в этой Big Data платформе потоковой обработке событий. Читайте далее про конфигурации потребителя и брокера, отвечающие за время хранения сообщений и политику очистки журналов.
Еще раз про offset или как потребители читают сообщения из топиков Apache Kafka
За чтение сохраненных сообщений по порядку из топика Kafka приложением-потребителем отвечают смещения (offset), которые хранятся в топике __consumer_offsets. Этот топик создается автоматически после настройки Kafka-кластера и используется для хранения информации о подтвержденных смещениях для каждого топика по принципу раздел (partition) на группу потребителей (groupID). Данные в этом топике будут периодически сжиматься, поэтому для считывания доступна только последняя информация о смещениях.
Каждая группа потребителей поддерживает свое смещение по разделам топика. Группа потребителей состоит из consumer’ов, которые взаимодействуют, получая данные из некоторых топиков. Разделы всех топиков делятся между потребителями в группе. Когда прибывают новые члены группы, а старые уходят, разделы перебалансируются, чтобы каждый член группы получил пропорциональную долю разделов. Один из брокеров назначается координатором группы и отвечает за управление членами группы, а также за назначение их разделов.
Координатор каждой группы выбирается из лидеров топика внутренних смещений __consumer_offsets. Обычно идентификатор группы хешируется в один из разделов этого топика, а его лидер выбирается в качестве координатора. Таким образом, управление группами потребителей равномерно делится между всеми брокерами в кластере, позволяя масштабировать количество групп за счет увеличения количества брокеров.
Каждый вызов API фиксации приводит к отправке брокеру запроса фиксации смещения. Используя синхронный API, потребитель блокируется до успешного ответа на этот запрос. Это ожидание может снизить общую пропускную способность, т.к. ожидая возврата, потребитель простаивает вместо обработки записей [1]. Когда диспетчер смещения получает запрос на фиксацию смещения (OffsetCommitRequest), он добавляет запрос в специальный сжатый топик Kafka с названием __consumer_offsets. А менеджер смещения отправит потребителю ответ об успешной фиксации смещения только тогда, когда все реплики топика смещения получат информацию об этом смещении [2].
3 важных конфигурации по удержанию сообщений в топике
Настроить политики хранения данных, чтобы контролировать, сколько и как долго данные будут храниться, можно с помощью конфигураций retention.bytes и retention.ms. Например, так можно ограничить использование места для сохранения сообщений, т.е. хранилища, в кластере и соблюдать законодательные требования, такие как GDPR. В частности, конфигурация retention.ms контролирует максимальное время, в течение которого лог будет храниться, прежде удаляться его старые сегменты, чтобы освободить место при использовании политики удаления сообщений. По сути, это SLA о том, как скоро потребители должны прочитать свои данные. Если для retention.ms установлено значение -1, ограничение по времени не применяется.
С конфигурацией retention.ms связаны log.retention.hours, log.retention.minutes, log.retention.ms, которые детализируют время хранения лог-файлов перед их удалением в часах, минутах и миллисекундах соответственно.
Однако, все эти перечисленные параметры относятся к конфигурации самого топика, а не к тому, как потребители считывают из него данные. За это отвечает сохранение подтвержденных смещений потребителей (Committed Offset Retention): как только потребитель Kafka начинает получать данные из топика, он фиксирует смещение последнего полученного сообщения во внутреннем топике брокера __consumer_offsets. Так потребитель сможет определить смещение, с которого он должен начать чтение топика в следующем запросе [2].
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
8 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
С этим связана конфигурация брокера offsets.retention.minutes для группы потребителей, значение которой по умолчанию задано 1440 минут, что составляет сутки (24 часа). Этот период означает время хранения смещений сообщений после того, как группа потребителей станет пустой. Для автономных потребителей (standalone) смещения будут истекать по истечении времени последней фиксации плюс этот период хранения [1]. После этого срока зафиксированное потребителем смещение будет сброшено, и consumer уже не сможет найти его в топике __consumer_offsets. В этом случае потребитель может снова прочитать все данные из топика или записи, определенные параметром конфигурации auto.offset.reset.
Значения свойства потребителя auto.offset.reset могут быть следующие [2]:
- ранее (earliest) – автоматически сбрасывает смещение до самого раннего смещения;
- последнее (latest) — автоматически сбрасывает смещение до последнего смещения;
- никакое (none) – генерация исключения для потребителя, если для его группы не найдено предыдущее смещение;
- другое (anything else) – выброс пользовательского исключения.
С этим свойством может быть связана очень редкая проблема, когда приложение-потребитель не работает более суток. В этом случае, если конфигурация брокера offsets.retention.minutes не настроена, и приложение-потребитель, не работавшее более суток, снова присоединяется к кластеру с последним значением offset.reset, оно считается новым и начинает потреблять сообщения, полученные после успешного повторного присоединения. Это приводит к потере данных. Поэтому на практике важно настроить период простоя, в зависимости от характера приложения и SLA, согласованного с бизнесом [3].
Как log.retention и offsets.retention влияют на топик Kafka: практический пример
Чтобы наглядно проиллюстрировать важность параметров хранения сообщений и смещений, рассмотрим пример, где для конфигураций log.retention.minutes и offsets.retention.minutes заданы значения, равные 7 дней и 5 дней соответственно [2]:
- retention.minutes=10080
- retention.minutes=7200
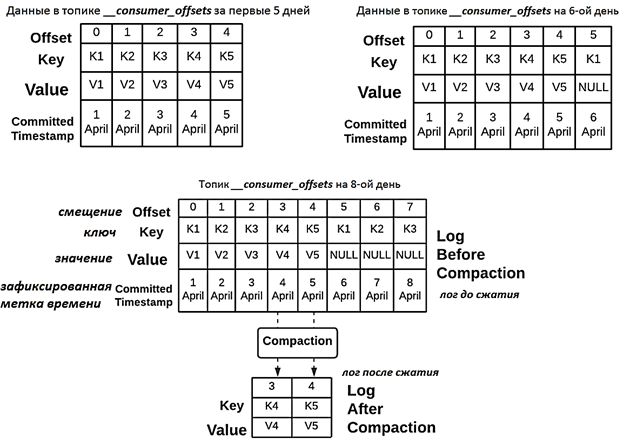
По прошествии периода offsets.retention.minutes на 6-й день значение ключа K1 не было удалено из топика __consumer_offsets, по следующим причинам:
- топик __consumer_offsets имеет политику очистки «компактная», и сжатие не было запущено;
- политика хранения топика __consumer_offsets определяется конфигурацией топика на уровне кластера, то есть log.retention.minutes, значение которого установлено в 7 дней.
Поскольку срок хранения смещения истек на 6-й день, то для ключа K1 смещение было сброшено (установлено в значение NULL). А по истечении периода хранения сообщений, заданного на уровне 7 дней в конфигурации log.retention.minutes, начиная с 8-го дня значения для ключей K1, K2 и K3 будут сброшены. При этом запущен поток очистки лога, в результате чего старые значения топика __consumer_offsets будут сжаты, т.к. его политика очистки (cleanup.policy) определена как компактная (compact).
Рассмотренный пример еще раз подтверждает гибкость настроек Apache Kafka, которые помогают администратору более эффективно использовать ресурсы кластера и решать поставленные бизнесом задачи. Читайте в нашей следующей статье о том, какие технологии обеспечивают быстрое выполнение операций дискового ввода и вывода в Кафка.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Еще больше полезных деталей администрирования кластеров Apache Kafka и использования этого фреймворка для разработки распределенных приложений потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

