 1589
1589 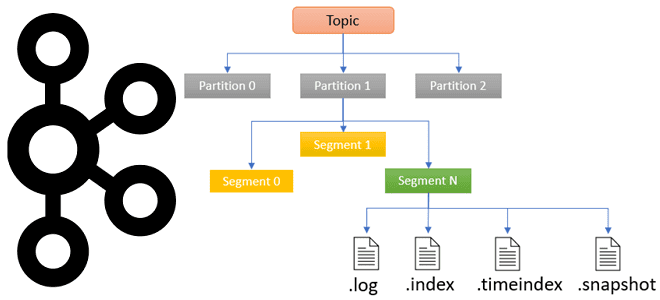
Содержание
Чтобы сделать наши практические курсы по Apache Kafka еще более полезными, сегодня рассмотрим, в каких файлах хранятся сообщения, смещения и состояния продюсера, а также функции работы с ними для потоковой передачи событий.
Средства обработки и хранения данных в Apache Kafka
Прежде, чем погружаться в тонкости хранения данных в Apache Kafka, вспомним ключевые принципы работы этой распределенной платформы потоковой передачи событий. Топик в Apache Kafka – это не физическое, а логическое хранилище сообщений, которые публикует продюсер, чтобы их считали потребители. По сути, топик – это способ сгруппировать потоки сообщений по категориям. Каждый топик может быть разбит на разделы (партиции, partition) – единицы параллелизма, где сообщения упорядочены в порядке их поступления в Kafka. Порядковый номер сообщения (смещение, offset) определяет, когда приложения-потребители считают данные: первыми считываются сообщения, которые получены раньше. Отслеживание смещения позволяет приложениям-потребителям читать сообщения с определенной позиции. Партиционирование топика позволяет выровнять нагрузку в кластере Apache Kafka благодаря равномерному распределению разделов по нескольким узлам (брокерам). Также разделение обеспечивает отказоустойчивость распределенной системы за счет механизма копирования (реплицирования) раздела на несколько брокеров.
У каждого реплицированного раздела есть брокер, который принимает запросы на чтение и запись данных. Такой брокер называется лидер (leader). А брокеры-последователи (followers), которые реплицируют данные лидера, принимают запросы только на чтение сообщений. Значение фактора репликации минус единица определяет количество последователей. Фактор репликации задает общее количество копий данных раздела во всем кластере, включая размещение на брокере-лидере.
Будучи реплицированными по брокерам-последователям и узлу-лидеру, разделы делятся на сегменты. Активный сегмент — это файл, доступный для чтения и записи, т.е. он находится на узле-лидере, а другие файлы сегментов лога используются для чтения и находятся на брокерах-последователях. Файл с расширением .log (лог) представляет собой фактический сегмент, содержащий сообщения до определенного смещения. Имя лог-файла определяет начальное смещение сообщений в этом логе.
Сегмент перестает быть активным, когда заполняется указанным количеством байтов, что настраивается в конфигурации log.segment.bytes или проходит период времени, заданный в конфигурациях log.roll.hours или log.roll.ms. Активный сегмент закрывается, т.е. перестает быть активным, и снова открывается в режиме только для чтения. Создается новый файл активного сегмента в режиме чтения и записи. Сегмент также может быть закрыт, когда файлы с расширениями .index и .timeindex достигли предельного размера, который по умолчанию равен 10 МБ. Что представляют собой эти файлы, и какие данные в них хранятся, мы рассмотрим далее.
А пока отметим, что сегмент с данными может быть удален только, когда он закрыт. Процесс удаления состоит из нескольких шагов: закрыть файл, пометить его как удаленный и удалить файл с диска. Жизненный цикл сообщений контролируется следующими параметрами конфигурации:
- log.retention.bytes — максимальный размер лога перед его удалением;
- log.retention.ms — количество миллисекунд хранения файла лога перед его удалением (в миллисекундах). Если не задано, используется значение в конфигурации retention.minutes. Если установлено значение -1, ограничение по времени не применяется.
- log.retention.check.interval.ms – частота в миллисекундах, с которой очиститель журнала проверяет, подходит ли какой-либо журнал для удаления;
- log.segment.delete.delay.ms — время ожидания перед удалением файла из файловой системы
Топики Kafka с низкой пропускной способностью могут хранить сообщения дольше заданных значений, если не учитывать период хранения на уровне сегмента. Kafka определяет, когда начинает истекать срок действия сообщений, добавляя период хранения на уровне сегмента к отметке времени самого последнего сообщения в этом сегменте. Подробнее о том, как происходит удаление данных из топиков Kafka, читайте в нашей новой статье.
Смещения и обеспечение целостности данных
Файл .index содержит индекс, который сопоставляет логическое смещение, т.е. идентификатор записи, со смещением сообщения в файле .log. Он используется для доступа к записям с нужными смещениями без необходимости сканирования всего файла .log, указывая Kafka, какую часть сегмента следует читать, чтобы найти требуемое сообщение. Файл .timeindex — это еще один индекс, используемый для доступа к записям по отметке времени в журнале.
Файл .snapshot содержит моментальный снимок состояния продюсера относительно идентификаторов последовательности, используемых для предотвращения дублирования сообщений. Он используется, когда после избрания нового лидера в случае сбоя предыдущий возвращается и пытается снова стать лидером. Эпоха лидера используется для последовательного избрания нового лидера в случае неудачи текущего.
Чтобы предотвратить чтение противоречивых данных приложениями-потребителями, Kafka использует механизм водяных знаков (watermark). Потребители могут считывать сообщения только до его верхнего предела, который представляет собой минимальное смещение нижнего конца во всех синхронизированных репликах этого раздела. Этот предел монотонно растет и определяется конфигурацией replica.high.watermark.checkpoint.interval.ms — частота, с которой верхний предел водяного знака сохраняется на диск.
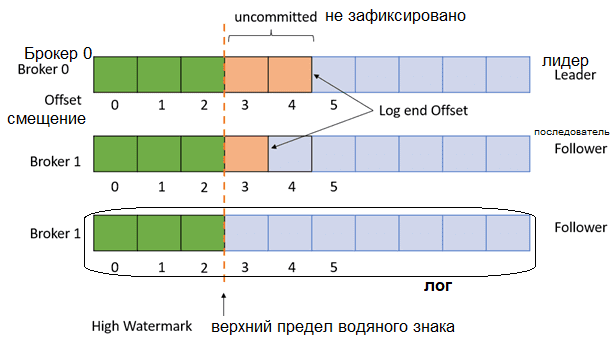
Для проверки целостности сообщения в Apache Kafka есть функция CRC32, которая преобразует строку переменной длины в строку из 8 символов. Эта строка является текстовым представлением шестнадцатеричного значения 32-битной двоичной последовательности. Также рассчитывается функция CRC32 для остальных байтов сообщения. Она называется CRC и используется для проверки целостности сообщения. Сообщение считается неповрежденным, если CRC32 полезной нагрузки сообщения соответствует CRC, которое хранится в самом сообщении. При обнаружении повреждения лог усекается до последнего допустимого смещения.
В заключение отметим, что Kafka использует бинарные форматы Apache AVRO и Protobuf, которые являются протоколами кодирования на основе языка описания интерфейсов IDL (Interface Description Language). В частности, каждый файл Avro IDL определяет один протокол Avro и, таким образом, генерирует в качестве выходных данных файл протокола AVRO в формате JSON с расширением .avpr. Подробнее про сравнение форматов сериализации данных, используемых в Apache Kafka, мы писали здесь.
Больше подробностей про администрирование и эксплуатацию Apache Kafka в системах аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

