 1516
1516 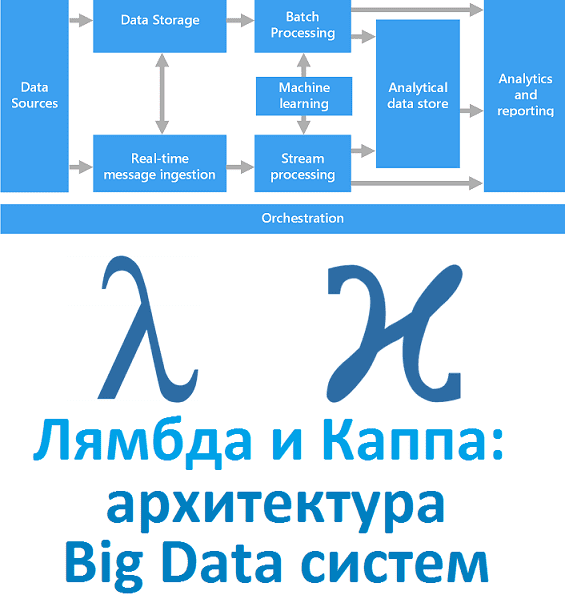
Содержание
Вчера мы рассказали, что такое лямбда-архитектура. Сегодня рассмотрим Каппа — альтернативный подход к проектированию Big Data систем. Читайте в нашей статье, зачем нужна эта концепция, каковы ее достоинства и недостатки, чем Каппа отличается от Лямбда, где это используется на практике и при чем тут Apache Kafka с Machine Learning.
Зачем нужна Каппа-архитектура и как она устроена
При всех достоинствах Лямбда-архитектуры, главным недостатком этого подхода к проектированию Big Data систем считается его сложность из-за дублирования логики обработки данных в холодном и горячем путях. Поэтому в 2014 году была предложена Каппа — альтернативная модель, которая потребляет меньше ресурсов, но отлично подходит для обработки событий в режиме реального времени [1].
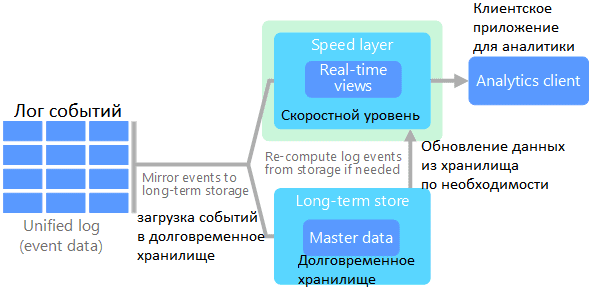
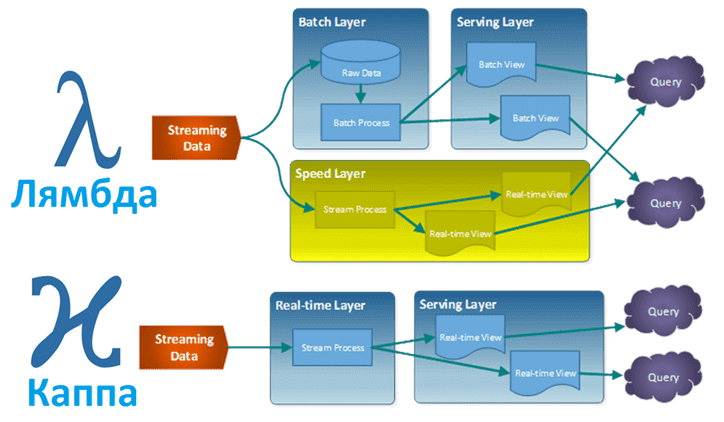
В отличие от лямбда, в Каппа-архитектуре потоковые данные проходят по одному пути. Все данные принимаются как поток событий в распределенном и отказоустойчивом едином журнале – логе событий. Там события упорядочиваются, и текущее состояние события изменяется только при добавлении нового события. Аналогично уровню ускорения лямбда-архитектуры, вся обработка событий выполняется во входном потоке и сохраняется как представление в режиме реального времени. Если необходимо повторно вычислить весь набор данных, как на пакетном уровне в лямбда-архитектуре, поток воспроизводится заново. Для своевременного завершения вычислений используется параллелизм [2].
Функциональное уравнение, которое определяет запрос Big Data, в Каппа-архитектуре будет выглядеть так [1]:
Query = K (New Data) = K (Live streaming data)
Это уравнение означает, что все запросы могут быть обработаны путем применения функции Каппа (К) к real-time потокам данных на скоростном уровне.
Таким образом, можно сказать, что Каппа-архитектура – это упрощение Лямбда-подхода к проектированию Big Data систем, когда из модели удален уровень пакетной обработки данных. При этом каноническое хранилище данных представляет собой неизменяемый журнал только для добавления информации. Из журнала данные сразу передаются в систему потоковых вычислений, по необходимости обогащаясь данными из неканонического хранилища (сервисный уровень). Цель сервисного уровня — предоставить оптимизированные ответы на запросы. Однако эти хранилища не являются каноническими (неизменяемыми): их можно в любой момент стереть и восстановить из канонического Data Store [3].
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
12 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Для реализации Каппа-архитектуры используются следующие технологии Big Data [3]:
- канонические хранилища для постоянного логгирования событий, например, Apache Kafka, Apache Pulsar, Amazon Quantum Ledger Database, Amazon Kinesis, Amazon DynamoDB Streams, Azure Cosmos DB Change Feed, Azure EventHub и другие подобные системы;
- фреймворки потоковых вычислений, например, Apache Spark, Flink, Storm, Samza, Beam, Kafka Streams, Amazon Kinesis, Azure Stream Analytics и другие streaming-системы;
- на сервисном уровне может использоваться практически любая база данных, резидентная (в памяти) или постоянная, в т.ч. хранилища специального назначения, например, для полнотекстового поиска.
Где используется K-подход и причем здесь Apache Kafka
Итак, Kappa-архитектура целесообразна для таких корпоративных моделей обработки данных, где [1]:
- несколько событий или запросов данных заносятся в очередь для обработки в распределенном хранилище файловой системы или в истории;
- порядок событий и запросов не предопределен — фреймворки потоковой обработки могут взаимодействовать с базой данных в любое время;
- требуется устойчивость и высокая доступность, поскольку обработка данных канонического хранилища выполняется для каждого узла системы.
Все эти сценарии отлично покрываются брокером сообщений Apache Kafka — быстрой, отказоустойчивой и горизонтально масштабируемой системой сбора и агрегации больших данных. Поэтому Каппа-архитектура на базе Kafka активно используется LinkedIn и другими Big Data проектами, где требуется сохранить большой объем данных для обслуживания запросов, которые являются простой копией друг друга [1].
Lambda или Kappa: что и когда выбирать
Прежде всего отметим, что при общих целях построения надежной и быстрой системы обработки больших данных, подходы лямбда и каппа не конкурируют друг с другом, а могут использоваться вместе для разных случаев. В частности, для надежной работы с озером данных (Data Lake) на базе Apache Hadoop и моделями машинного обучения для прогнозирования будущих событий на основе исторических данных, следует выбрать Лямбда-подход. С другой стороны, если необходимо недорого развернуть Big Data систему для эффективной обработки уникальных событий в реальном времени без исторического анализа, Каппа-архитектура отлично справится с этой задачей. Каппа подходит для тех алгоритмов Machine Learning, которые обучаются в режиме онлайн и не нуждаются в пакетном уровне. Таким образом, для Kappa характерны следующие достоинства [1]:
- повторная обработка данных нужна только при изменении кода;
- требуется меньше ресурсов в связи с одним путем обработки данных;
- на сервисном уровне в качестве неканонического хранилища можно использовать практически любую базу данных.
Тем не менее, отсутствие пакетного уровня может привести к ошибкам при обработке информации или при обновлении базы данных. Поэтому в Каппа-архитектуре возникает потребность в диспетчере исключений для повторной обработки данных или сверки [1]. В следующей статье мы поговорим про процессы и инструменты обеспечения качества больших данных с помощью Apache Spark, Airflow и других Big Data фреймворков. А тему архитектуры продолжим здесь.
Про недостатки лямбда- и каппа-архитектур и их устранение в дельта-модели читайте в нашей новой статье. А как на практике реализовать Лямбда или Каппа-архитектуру больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

