 641
641 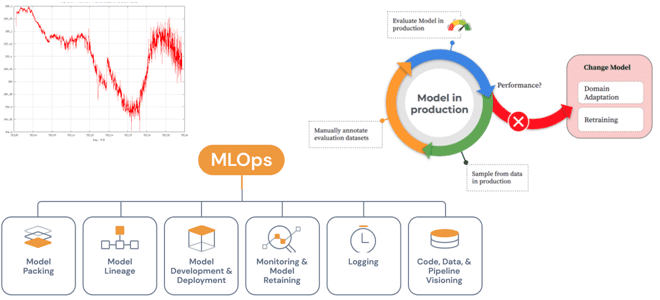
Специально для обучения ML-разработчиков сегодня разберем проблемы развертывания моделей Machine Learning в производстве и способы их решения с помощью MLOps-инструментов. А также поговорим про дрейф данных и его обнаружение методами математической статистики.
Жизненный цикл ML-моделей и MLOps
Каждый проект машинного обучения начинается с данных, подготовка которых занимает большую часть жизненного цикла ML-системы. Можно потратить месяцы на эксперименты с архитектурой нейросети и получить незначительные 2–3% улучшения целевых показателей. А простая очистка данных может дать прирост производительности в несколько раз больше. Но, чтобы управлять данными, их надо собирать и хранить в корпоративном хранилище или озере данных на Apache HDFS, AWS S3 или MinIO. Для этого следует настроить ETL-процессы, которые обеспечивают добавление данных в хранилище. На практике в качестве основных ETL-инструментов часто используются Apache Spark, Kafka, NiFi и AirFlow, а также их коммерческие аналоги.
Кроме того, данные для ML-систем необходимо проанализировать, разметить и контролировать их версии. Для разметки данных в области Computer Vision можно использовать CVAT и Scalabel, для текстов – Prodigy, а для мультиформатной разметки — label-studio. Еще в промышленных системах Machine Learning нужно организовать хранилище фичей (Feature Store) для их повторного использования. Примерами таких баз данных являются Feast, nlatia, Amazon SageMaker Feature Store, а также собственные разработки на базе открытых технологий, о чем мы писали здесь и здесь. Также по мере роста компании и увеличения количества команд необходимо эффективно управлять доступом и контролировать целостность данных, в т.ч. хранимых в Feature Store.
Подготовив данные, можно приступать к проверке гипотез и переходить к экспериментам. На этом этапе очень важна скорость итерации: сколько гипотез можно проверить и сколько экспериментов провести в ограниченный период времени. Поэтому для больших объемов данных необходима масштабируемая воспроизводимость этого этапа. Воспроизводимость экспериментов в большом масштабе является одной из задач концепции MLOps, направленной на сокращение разрыва между разнопрофильными специалистами, занятыми в процессах разработки, развертывания и эксплуатации систем машинного обучения. В частности, в этом случае можно использовать Pytorch-lightning – Python-фреймворк, который входит в состав экосистемы PyTorch. Он абстрагирует низкоуровневые детали, позволяя ML-специалистам фокусироваться на качестве создаваемых моделей, не отвлекаясь на вопросы, как будут проходить эксперименты, как использовать несколько GPU и пр. Впрочем, Pytorch-lightning подходит не всем, и часто команды пишут свои собственные аналогичные решения или используют похожие шаблоны. Для отслеживания и контроля экспериментов также можно использовать следующие MLOps-инструменты:
- TensorBoard, имеющий множество интеграций с различными фреймворками. Он позволяет сохранять результаты в облаке, чтобы облегчить совместную работу ML-специалистов. Но на практике этот фреймворк бывает трудно масштабировать, что усложняет пользовательский опыт работы в нем.
- MLflow Tracking, популярный инструмент для управления всем циклом моделей машинного обучения, что мы рассматривали здесь и здесь. Это инструмент с открытым исходным кодом, который можно поддерживать самостоятельно или использовать управляемое решение от Databricks.
- Также можно попробовать Weights & Biases, Comet.ml и AIM.
В любом случае, при внедрении этих и аналогичных MlOps-инструментов потребуется инфраструктура для разработки ML-моделей, включая кластер с GPU. Можно использовать решения облачных провайдеров: AWS, GCP, Яндекс, VK и пр. Для централизованного запуска экспериментов пригодится Slurm и поды Kubernetes.
После завершения серии экспериментов, которые подтвердили гипотезы, можно реструктурировать код в повторно обучаемый конвейер, чтобы развернуть его в производстве. Для этого используются Docker-контейнеры и средства конвейерной обработки, например, AirFLow, Kubeflow pipelines и Dagster. Самым простым вариантом развертывания является использование интерактивных блокнотов типа Google Colab, Jupyter Notebook, Streamlit, Dash, Fastpages. Эти не очень удобные, но легковесные инструменты являются отличным способом бизнес-валидации ML-моделей, т.е. проверки того, что они действительно приносят компании практическую пользу.
Другим, чуть более сложным, вариантом является обертка ML-модели в собственный микросервис с использованием Python или другого подходящего языка. Для этого часто применяется фреймворк Flask, который позволяет быстро разработать веб-приложение с возможностью его последующего масштабирования. Также можно использовать FastAPI или Aiohttp, если нужна асинхронность. Наконец, для компаний с высокой степенью зрелости MLOps-процессов, можно стандартизировать способ развертывания моделей, используя готовое решение типа Triton Inference Server, KServe, Seldon, TensorFlow Serving, TorchServe и прочие инструменты, которые могут преобразовать ML-модель в формат, понятный серверу вывода, чтобы он мог развернуть ее автоматически. При этом не придется писать свой собственный веб-сервер, достаточно просто сохранить модель в определенном формате. Такие фреймворки дают массу дополнительных возможностей: систему контроля версий для моделей, пояснения к результатам ML-моделей и поддержку нескольких моделей из коробки.
Справедливости ради стоит отметить, что один вариант не исключает другие, и конечный выбор зависит от контекста. Для стартапа из 10 человек, отлично подойдет Flask или FastAPI в качестве стартового решения. Но для крупной корпорации, где в одном только отделе машинного обучения работает более 100 человек, нужен проверенный и надежный способ доставки ML-моделей: Seldon, KServe или другие промышленные аналоги. После развертывания модели в production необходимо отслеживать ее работу, т.е. выполнять мониторинг важных метрик, о чем мы поговорим далее. А в этой статье вы узнаете про типовые шаблоны развертывания ML-системы в производственной среде от инженеров платформы Databricks Lakehouse.
Мониторинг моделей машинного обучения в производстве
Изначально ML-модели обучаются и оцениваются на основе исторических эталонных размеченных данных. Но, как только модель развернута и используется для прогнозирования новых данных, часто трудно убедиться, что она по-прежнему работает правильно. Модели могут со временем ухудшаться из-за изменений во внешнем мире. Более того, в источниках или конвейерах данных производственной модели могут быть ошибки. Поэтому мониторинг прогнозов, сделанных ML-моделями в производственной среде, очень важен и является обязательным условием обеспечения их постоянной производительности и надежности. Как это сделать, мы подробно разбираем в новой статье.
Модели машинного обучения ожидают, что каждая выборка данных объекта (пакет для обучения, проверки, тестирования или входных данных) создается из независимого и идентично распределенного источника. На практике базовый механизм, генерирующий некоторые данные признаков, должен быть одинаковым для всех образцов (обучающий пакет, пакет проверки и т. д.). Это предположение должно сохраняться для всех функций, связанных с любой конкретной проблемой машинного обучения.
Обучающий и тестовый датасеты для любой фичи не зависят друг от друга, но они имеют одинаковое статистическое распределение. Поэтому ML-модель теряет свою прогностическую эффективность, когда изменяется распределение вероятностей любого релевантного входного или выходного признака, или же их обоих. Это означает, что системные переменные претерпевают изменения, т.е. изменяется сама базовая система. Таким образом, надо явно отслеживать метрики производительности модели в production, используя те же метрики, что и на этапе валидации.
При этом следует также определять дрейф в распределении вероятности в производстве по отношению к некоторому эталону, например, входным данным для обучения. Но дрейф данных должен оцениваться одномерно, т.е. отдельно для каждого признака. Одним из интуитивно понятных способов оценки общего дрейфа данных для объектов в целом может быть взвешенное среднее значение дрейфа данных отдельных объектов с важностью объектов в качестве их веса. Однако, важность объектов может измениться. Кроме того, пространство признаков табличных входных данных может обрабатываться отдельно посредством одномерного дрейфа данных, но многомерная подача входных данных глубокого обучения для Computer Vision или NLP не может рассматриваться отдельно. Дрейф данных в глубоком обучении для CV или NLP требует уменьшения размерности, а затем обнаружения многомерного дрейфа.
Такой подход к мониторингу ML-моделей измеряет взаимосвязь между входными данными и целевыми производственными данными в форме совместного распределения вероятностей или условного распределения вероятностей. Это дрейф распределения вероятностей по отношению к некоторому эталону (скажем, тренировочному вводу и цели). Можно сказать, что распределение вероятностей — самый важный компонент для любого расчета дрейфа данных. Измерить его можно на основе статистической разнице энтропии или расстоянии между вероятностными распределениями. Это поможет сравнить дрейф данных с некоторым пороговым значением, чтобы определить значительное расхождение между плановыми и фактическими значениями.
Например, дивергенция Кульбака-Лейблера, часто называемая относительной энтропией, — простой способ сравнения вероятностных распределений одного и того же признака. Для множественного одномерного тестирования используется расхождение Дженсена-Шеннона, а также расстояние Вассерштейна, которое также подойдет и для многомерного тестирования. Также показатели статистической проверки гипотезы различия в распределении необходимо сравнивать с некоторым порогом (критическим значением тестовой статистики или p-значением), чтобы пометить такой дрейф как значительный. Для этого применяется критерий Колмогорова-Смирнова – непараметрический тест на равенство распределений вероятностей для сравнения одной выборки с эталонным распределением или для сравнения двух выборок. Также может использоваться критерий согласия хи-квадрат – тест статистической гипотезы для определения того, может ли (категориальная) переменная происходить из указанного распределения или нет.
Для всех многомерных представлений максимальное среднее несоответствие является популярным методом на основе ядра для многомерного тестирования с двумя выборками. Этот алгоритм применим для многомерного табличного пространства признаков, часто присутствующего в Computer Vision и NLP.
Таким образом, можно выделить 2 подхода к мониторингу ML-моделей в производстве:
- наиболее точный подход — регистрировать прогнозы, сделанные в производственной среде, а затем объединять их с результатами, когда они собираются конвейерами данных. Сравнивая прогнозы с фактическими данными, можно вычислить показатели точности, обеспечивая мониторинг показателей производительности модели.
- Менее точный подход, когда результаты прогнозирования сложно собрать или соединить прогнозы с результатами, можно вести мониторинг распределения фичей и прогнозов, сравнивая их во времени. Это поможет обнаруживать проблематичные сдвиги в фичах, обеспечивая мониторинг дрейфа данных и его прогнозирование.
Впрочем, важно следить не только за качеством данных, но и за качеством самой ML-модели, сохраняя результаты вывода и получая реальные метки для них. Для этого можно использовать комплексные платформы и отдельно взятые MLOps-инструменты, которые охватывают сквозной цикл машинного обучения и поддерживают каждый из шагов. Например, AWS SageMaker и GCP Vertex AI. В любом случае, MLOps автоматизирует несколько процессов, от предварительной обработки данных и экспериментов до мониторинга и возврата к любому из предыдущих шагов.
Как выбрать и внедрить современные инструменты MLOps в реальные проекты аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

