878
878 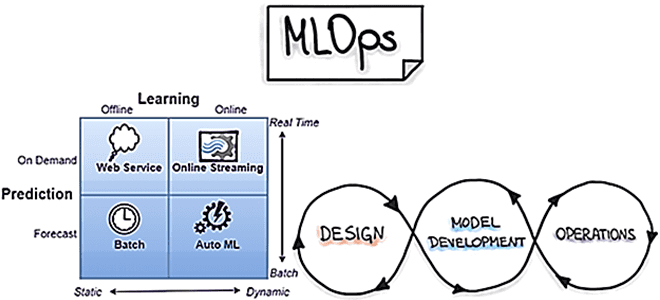
Содержание
Сегодня рассмотрим наиболее распространенные в MLOps стратегии развертывания, т.е. подходы к внедрению моделей машинного обучения в производство. Выбор стратегии зависит от бизнес-требований и от контекста применения результатов ML-моделирования. Какие бывают стратегии и как они реализуются: краткий ликбез с примерами для ML-инженеров и MLOps-специалистов.
Пакетное прогнозирование и веб-сервисы для MLOps
Это самая простая форма стратегии развертывания ML-систем, которая используется в онлайн-соревнованиях и научных исследованиях. Здесь планируется выполнение кода с ML-прогнозированием в определенное время и вывод результатов в базу данных или файловые системы. Например, можно написать программный код на Python и запланировать его выполнение с помощью Cron, но это требует дополнительных усилий для проверки, аудита и мониторинга.
Вместо этого можно написать пакетное задание Spark и запланировать его в YARN, дополнив средствами ведения логов для мониторинга и повторных попыток в случае сбоя. Здесь возможно использование Apache AirFlow и его аналогов в виде Perfect и Dagster, которые позволяют планировать и отслеживать выполнение пакетных заданий в пользовательском веб-интерфейсе. Наконец, ML-платформы Kubeflow, MLFlow и Amazon Sagemaker также предоставляют возможности пакетного развертывания и планирования.
Еще одной популярной стратегией развертывания ML-систем является их реализация в виде веб-сервисов, которые принимают входные параметры и выводят результаты. Прогнозы выполняются почти в режиме реального времени, за один раз строится только 1 прогноз по обработке одной записи. Поэтому, в отличие от пакетных заданий, которые обрабатывают много записей за раз, веб-сервисы не требуют много ресурсов.
Самый простой способ реализовать ML-систему в виде веб-сервиса – это написать сервис и поместить его в Docker-контейнер для интеграции с существующими продуктами. На практике здесь чаще всего применяется минималистичный фреймворк Flask для создания веб-приложений на языке Python. Далее можно развернуть Flask-приложение на Heroku, Azure, AWS, Google Cloud или облачной платформе PythonAnywhere. Аналогично вместо Flask можно использовать Django или Falcon, Starlette, Sanic, FastAPI и Tornado. В частности, FastAPI, веб-фреймворк для разработки RESTful API на Python вместе с сервером Uvicorn сегодня становится особенно популярным из-за минимальных требований к коду и возможности автоматической генерации программной документации в форматах OpenAPI (Swagger) и ReDoc.
Оба рассмотренные подхода широко используются на практике, однако, им свойственны некоторые недостатки:
- производительность пакетных заданий зависит от объема обрабатываемых данных;
- типовые проблемы веб-сервисов, включая обработку сбоев и повторных попыток. Если вызовы модели Machine Learning являются асинхронными, веб-сервис может потерпеть сбой из-за нехватки памяти на серверах в случае резкого увеличения объема данных, например, во время перезапуска.
Обойти отмеченные проблемы помогут следующие MLOps-стратегии развертывания.
Потоковая аналитика в реальном времени и AutoML
Потоковая обработка данных предполагает вычисления в реальном времени. Запросы на загрузку ML-модели и данных поступают в виде потока событий, например, из топиков Kafka, чтобы запускать данные по мере их поступления в систему, которая является асинхронной, отказоустойчивой, воспроизводимой и масштабируемой. В этом подходе ML-система управляется событиями и позволяет повысить производительность вычислений. Для реализации системы машинного обучения с использованием этой стратегии чаще всего применяются фреймворки Apache Spark или Flink, которые позволяют интегрировать ML-модели, написанные с использованием Scikit-Learn или Tensorflow, отличных от встроенных библиотек Spark MLlib или Flink ML. Также можно использовать сторонние Java-библиотеки, такие как MLeap или JPMML.
Еще одной актуальной сегодня тенденцией является автоматизированное машинное обучение (AutoML). Эта стратегия внедрения актуальна для сред, где поведение ML-модели меняется очень быстро, поэтому нужна модель машинного обучения, которая может учиться на новых примерах почти в реальном времени. При этом очень важна архитектура модели Machine Learning, поскольку из-за быстроты изменений невозможно каждый раз создавать ее новые экземпляры. Кроме того, эта не масштабируется по горизонтали, и нужно иметь один экземпляр модели, который потребляет новые данные по мере их появления, выдавая наборы изученных параметров за API. При этом модель, как самая важная часть процесса, масштабируется только по вертикали и ее может быть даже невозможно распределить между потоками. Например, эту стратегию развертывания используют сервисы Uber Eats, предложения соцсети LinkedIn по связям, поисковые системы Airbnb, дополненная и виртуальная реальность, человеко-машинные интерфейсы и беспилотные автомобили.
Реализовать эту MLOps-стратегию можно даже в рамках простой Python-библиотеке Sklearn. В ней есть несколько алгоритмов, поддерживающих инкрементное онлайн-обучение с использованием метода partial_fit: SGDClassifier, SGDRegressor, MultinomialNB, MiniBatchKMeans, MiniBatchDictionaryLearning. В Spark MLlib есть по крайней мере 2 ML-алгоритма для поддержки онлайн-обучения: StreamingLinearRegressionWithSGD и StreamingKMeans.
Впрочем, машинное обучение в реальном времени тоже имеет ряд характерных проблем. Поскольку данные часто меняются, ML-модель реагирует на новые данные и изменяет свое поведение. Поэтому нужен обязательный оперативный мониторинг, чтобы управлять поведением данных. Например, в рекомендательной системе реакция одного пользователя может влиять на результаты прогнозирования для других потребителей. Но есть вероятность, что эти данные могут быть мошенническими, поэтому их следует удалить из обучающих данных.
Заботиться об этом при пакетном обучении относительно легко, а вводящие в заблуждение шаблоны данных и выбросы можно очень легко удалить из обучающего датасета. Но в реальном времени это намного сложнее, и создание конвейера мониторинга такого поведения данных может сильно повлиять на производительность системы Machine Learning из-за размера обучающих данных.
В заключение отметим еще несколько других стратегий развертывания: SQL-запросы, RPC-сервер, многоуровневое хранилище или база данных в качестве хранилища модели. Впрочем, все они представляют собой комбинации или варианты вышерассмотренных четырех стратегий. Все эти стратегии развертывания можно комбинировать между собой, формируя подход в соответствии с потребностями бизнеса. Например, если данные часто меняются, но нет платформы онлайн-обучения, можно выполнять пакетное обучение каждый час одновременно с онлайн-прогнозированием. Читайте в нашей новой статье примеры практической реализации MLOps на открытых инструментах.
Узнайте, как внедрить лучшие практики MLOps с Apache Spark и другими инструментами аналитики больших данных, на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники