 1265
1265 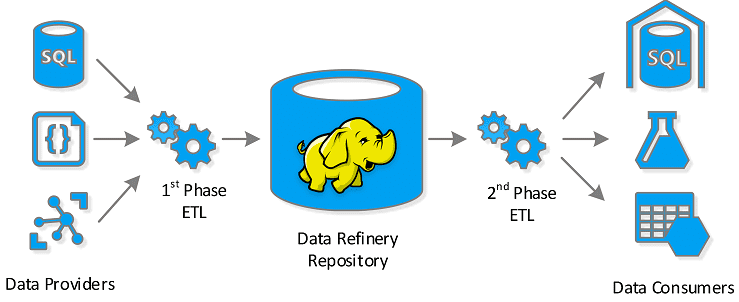
Содержание
Несмотря на очевидные достоинства Apache NiFi, этой Big Data платформе быстрой загрузке и маршрутизации данных, активно применяемой в интернете вещей (Internet of Things, IoT), в т.ч. индустриальном (Industrial Iot, IIoT), также свойственны и некоторые недостатки. Сегодня мы поговорим об альтернативах Apache NiFi: Flume, Sqoop, Chuckwa, Gobblin, Falcon, а также Fluentd и StreamSets Data Collector. Читайте в нашей статье про сходства и отличия этих средств передачи больших данных.
Что такое маршрутизация Big Data и зачем она нужна
Под маршрутизацией данных мы будем понимать процесс сбора информации из различных источников (локальных и облачных файловых хранилищ, баз данных, IoT/IIoT-устройств), их агрегацию по определенным параметрам и дальнейшую передачу в другие системы-приемники (файловые хранилища, базы данных, брокеры сообщений и пр.). Как правило, функция хранения данных не входит в задачи маршрутизатора. Таким образом, маршрутизаторы данных выполняют типичный набор ETL-операций (Extract, Transform, Load).
Вообще в Big Data выделяют 2 режима работы с данными, в т.ч. в отношении их загрузки и маршрутизации [1]:
- пакетный, который используется для очень больших файлов или в ситуациях, не критичных к временной задержке отклика (latency). Файлы, которые нужно передать, собираются в течение определенного периода времени, а затем отправляются вместе в виде пакетов.
- потоковый, когда данные поступают в реальном времени и должны быть загружены во внешнюю систему незамедлительно.
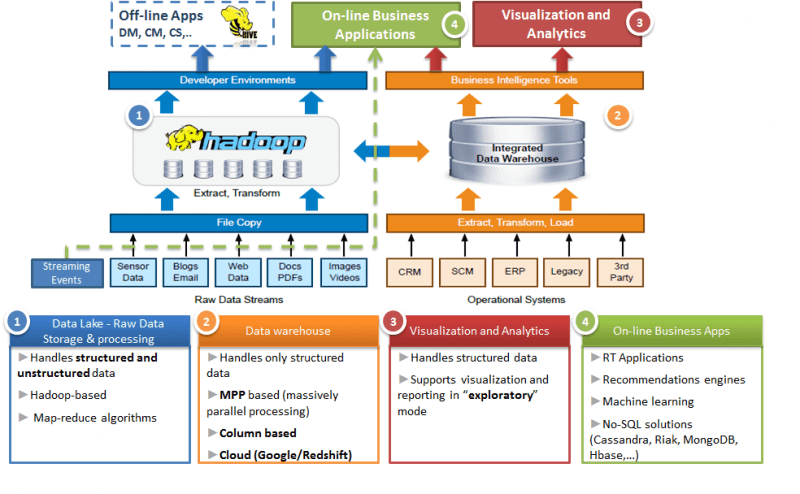
На практике ETL-операции с большими данными, как в пакетном, так и в потоковом режимах, необходимы для загрузки информации в корпоративные хранилища (Data Warehouse, DWH) и озера данных (Data Lake), а также визуального представления информации по разным измерениям OLAP-кубов в витринах данных (дэшбордах) систем бизнес-аналитики (Business Intelligence).
Apache NiFi vs Gobblin и StreamSets Data Collector: краткий обзор средств потокового и пакетного ETL
Некоторые ETL-инструменты Big Data, в частности, Apache NiFi и Gobblin, хорошо работают с обоими режимами передачи данных. Gobblin, как и NiFi, является универсальной системой сбора информации для извлечения, преобразования и загрузки большого объема данных из различных источников данных (баз данных, REST API, серверов FTP/SFTP и т.д.). Обе этих платформы часто используются в задачах интеграции и построения конвейера данных, обеспечивая работу со популярными файловыми форматами Big Data (AVRO, Parquet, JSON), и могут быть развернуты на локальном кластере под управлением YARN/Mesos или в облаке Amazon Web Services (AWS). Однако, Apache Goblin, в отличие от NiFi, поддерживает MapReduce, что обеспечивает отказоустойчивость при работе с HDFS [2].
Тем не менее, несмотря на схожесть в прикладном назначении, Apache NiFi, в отличие от Gobblin, имеет графический интерфейс и оформлен в виде отдельного приложения. Это отличие позволяет работать с Apache NiFi широкому кругу пользователей – от аналитика до администратора Big Data, а не только разработчику или инженеру данных [3].
С точки зрения пользовательского интерфейса Apache NiFi можно сравнить с другим ETL-средством, StreamSets Data Collector – инфраструктурой непрерывного приема больших данных с открытым исходным кодом корпоративного уровня. В рамках наглядного пользовательского интерфейса она позволяет разработчикам, инженерам и ученым по данным легко создавать конвейеры маршрутизации потоковых данных со сложными сценариями загрузки. В качестве приемников и источников информации StreamSets Data Collector интегрирована с Apache Hadoop (HDFS, HBase, Hive), NoSQL-СУБД (Cassandra, MongoDB), поисковыми системами (Apache Solr, Elasticsearch), реляционными СУБД (Oracle, MS SQL Server, MySQL, PostgreSQL, Netezza, Teradata и пр., которые поддерживают JDBC-подключение), системами управления очередями сообщений (Apache Kafka, JMS, Kinesis), локальными и облачными файловыми хранилищами (Amazon S3 и т.д.) [4]. Однако, нельзя сказать, что Apache NiFi полностью заменяет StreamSets Data Collector или наоборот – у этих ETL-инструментов разные варианты использования (use cases) [5], подробнее о которых мы расскажем в новой статье. А чем еще отличаются эти ETL-платформы, читайте здесь.
Также конкурентным преимуществом Apache NiFi можно назвать его легковесный вариант MiNiFi, который часто используется в IoT/IIoT-проектах благодаря своей быстроте и малой ресурсоемкости. Пример прототипа системы Industrial Internet of Things на базе Apache NiFi и MiNiFi мы рассматривали здесь.
Еще стоит отметить возможности передачи данных в комплексных Big Data фреймворках, которые обеспечивают обработку информации и могут работать как в поточном, так и в пакетном режимах. В частности, к таким платформам относятся Apache Flink, Apex и Storm (с помощью высокоуровневого API-интерфейса Trident). Однако, в связи с их многофункциональностью, эти инструменты редко используются только в качестве средства сбора и передачи данных в Big Data и IoT/IIoT-проектах. Поэтому сравнивать их с Apache NiFi и другими подобными решениями несколько некорректно, а, значит, их рассмотрение останется за рамками настоящей статьи.
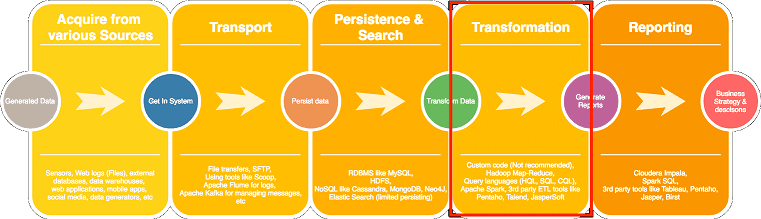
Среди фреймворков пакетной загрузки больших данных из разных источников наиболее популярными считаются следующие проекты фонда Apache Software Foundation (ASF): Chukwa, Sqoop и Falcon, о которых мы рассказываем здесь. А для потоковой передачи часто используются Apache Flume и Fluentd. Подробнее про все эти Big Data маршрутизаторы мы поговорим в следующий раз.
Освойте все тонкости установки, администрирования и эксплуатации платформ маршрутизации больших данных на нашем практическом курсе Кластер Apache NiFi в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.
Источники
- https://moluch.ru/archive/202/49512/
- https://gobblin.readthedocs.io/
- https://stackoverflow.com/questions/49010622/apache-nifi-vs-gobblin
- https://github.com/streamsets/datacollector
- https://statsbot.co/blog/open-source-etl/

