 1419
1419 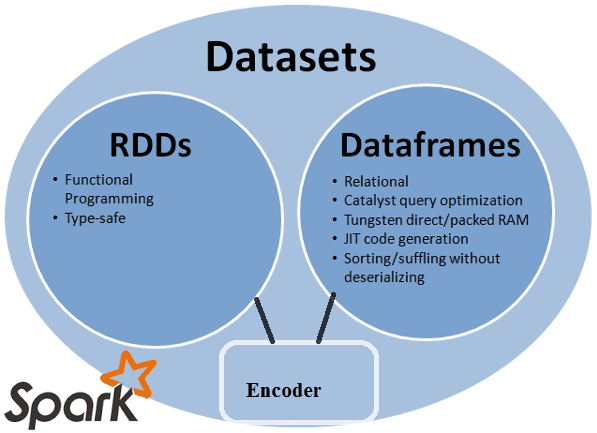
Содержание
В прошлый раз мы рассмотрели понятия датафрейм (DataFrame), датасет (DataSet) и RDD в контексте интерактивной аналитики больших данных (Big Data) с помощью Spark SQL. Сегодня поговорим подробнее, чем отличаются эти структуры данных, сравнив их по разным характеристикам: от времени возникновения до специфики вычислений.
Критерии сравнения структур данных Apache Spark
Прежде всего, определим, по каким параметрам мы будем сравнивать DataFrame, DataSet и RDD. Для этого выделим несколько точек зрения:
- данные – представления, форматы, схемы;
- вычисления – сериализация, отложенные (ленивые) вычисления, операции агрегирования, использование памяти;
- разработка – поддерживаемые языки программирования, безопасность типов при компиляции, оптимизация, сборка мусора (Garbage Collection), неизменность (Immutability) и совместимость (Interoperability), область применения.
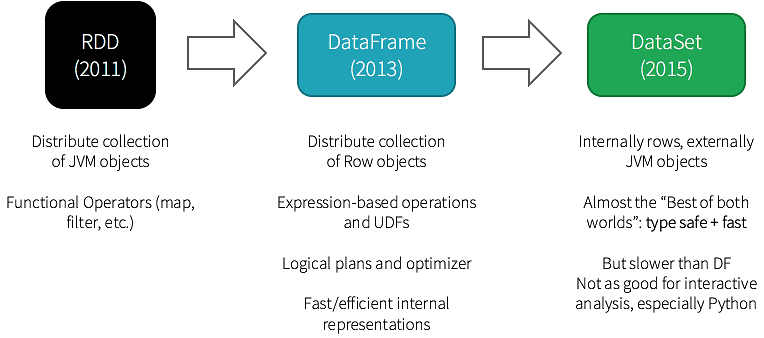
Перед тем, как приступить к сравнению RDD, DataFrame и DataSet по вышеперечисленным критериям, отметим разный порядок появления этих структур данных в Apache Spark [1]:
- RDD появился с первого релиза фреймворка (Spark 0);
- Датафрейм впервые был представлен в Spark 1.3;
- Датасет стал доступен в версии 1.6.
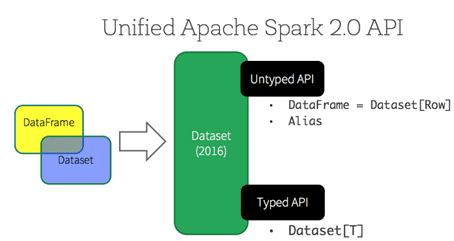
Стоит также сказать, что, начиная с релиза 2.0 (2016 г.), DataSet API можно рассматривать с 2-х позиций: строго типизированный и нетипизированный. Таким образом, концептуально DataFrame является коллекцией универсальных объектов DataSet[Row], где Row – это универсальный нетипизированный JVM-объект. DataSet, напротив, представляет собой набор строго типизированных объектов JVM, определяемых классом в Scala или Java [2].
Данные в RDD, DataFrame и DataSet: представления, форматы и схемы
Начнем с представления данных [1]:
- RDD – это распределенная коллекция данных, расположенных по нескольким узлам кластера, набор объектов Java или Scala, представляющих данные. RDD работает со структурированными и с неструктурированные данными. Также, как DataFrame и DataSet, RDD не выводит схему загруженных данных и требует от пользователя ее указания.
- DataFrame – это распределенная коллекция данных в виде именованных столбцов, аналогично таблице в реляционной базе данных. DataFrame работает только со структурированными и полуструктурированными данными, организуя информацию по столбцам, как в реляционных таблицах. Это позволяет Spark управлять схемой данных.
- DataSet – это расширение API DataFrame, обеспечивающее функциональность объектно-ориентированного RDD-API (строгая типизация, лямбда-функции), производительность оптимизатора запросов Catalyst и механизм хранения вне кучи. DataSet эффективно обрабатывает структурированные и неструктурированные данные, представляя их в виде строки JVM-объектов или коллекции. Для представления табличных форм используется кодировщик (encoder).
RDD, DataFrame и DataSet по-разному используют схемы данных [1]:
- в API RDD проекции схемы используются явно, поэтому требуется определять схему данных вручную;
- датафрейм автоматически определяет схему данных из файлов и представляет их в виде таблиц, например, через мета-хранилище Apache Благодаря этому возможно подключение стандартных SQL-клиентов к Apache Spark.
- датасет также, благодаря встроенному движку Spark SQL (engine) автоматически обнаружит схему данных.
Как реализуются вычисления в Apache Spark
Напомним, сериализация представляет собой процесс перевода данных из формата – структуры, семантически понятной человеку, в двоичное представление для машинной обработки [3]. Это необходимо для хранения объекта на диске или в памяти и его передаче по сети. В этом отношении рассматриваемые структуры данных Apache Spark также отличаются друг от друга:
- RDD-коллекция сериализуется каждый раз, когда Spark требуется распределить данные внутри кластера или записать информацию на диск. Затраты на сериализацию отдельных объектов Java и Scala являются дорогостоящими, т.к. выполняется отправка данных и структур между узлами [1].
- DataFrame может сериализовать данные в хранилище вне кучи (т.е., в памяти) в двоичном формате, а затем выполнить много преобразований непосредственно в этой памяти без кучи. Это возможно из-за того, что в датафреймах Spark понимает схему данных. Благодаря инструменту Tungsten не требуется использовать сериализацию Java для кодирования данных, т.к. этот механизм явно управляет памятью и динамически генерирует байт-код для оценки выражений [4]. Благодаря динамической генерации байт-кода с сериализованными данными можно выполнить много операций, не требуя десериализации для небольших вычислений [1].
- DataSet API обрабатывает преобразование между объектами JVM в табличное представление c использованием вышеупомянутого безопасного двоичного формата Tungsten. Это позволяет выполнить операцию с сериализованными данными, эффективно используя память, т.к. предоставляется доступ к индивидуальному атрибуту по требованию без десериализации всего объекта [1].
Таким образом, из-за особенностей сериализации, датасет, датафрейм и распределенная коллекция данных по-разному потребляют память: DataFrame и DataSet обрабатываются быстрее, чем RDD. Это сказывается и при выполнении простых операций группировки и агрегирования. В частности, API RDD выполняет их медленнее. Из-за этого DataFrame оптимально использовать для генерации агрегированной статистики для больших наборов данных, а DataSet – для быстрого выполнения операций агрегации на множестве массивов Big Data [1]. Такая ситуация обусловлена тем, что API-интерфейсы DataFrame и Dataset построены на основе движка Spark SQL, который использует Catalyst для создания оптимизированного логического и физического плана запросов. В этих API-интерфейсах для R, Java, Scala или Python все запросы типов отношений подвергаются одному и тому же оптимизатору кода, обеспечивая эффективность использования пространства и скорости. При том, что строго типизированный API Dataset оптимизирован для задач разработки, нетипизированный набор данных (DataFrame) обрабатывается еще быстрее и подходит для интерактивного анализа [2]. Подробнее про оптимизацию и другую специфику, важную с точки зрения Big Data разработчика, мы поговорим в нашей следующей статье. А о самом SQL-оптимизаторе Catalyst мы рассказываем здесь.
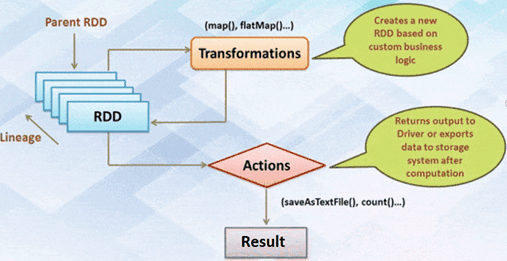
Наконец, поговорим про отложенные (ленивые) вычисления, которые откладываются до тех пор, пока не понадобится их результат. Эти операции реализуются с RDD, DataFrame и DataSet практически одинаково. Например, при работе с RDD результат вычисляется не сразу – вместо этого просто запоминается преобразование, примененное к некоторому базовому набору данных. А само преобразование Spark выполняет только тогда, когда для действия необходимо отправить результат. В DataFrame и DataSet вычисления происходят только тогда, когда появляется действие, к примеру, результат отображения, сохранение вывода [1].
Читайте в нашей следующей статье про разницу RDD, DataFrame и DataSet с точки зрения разработчика.
Больше практических деталей по применению Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники
- https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-DataFrames-and-DataSets/
- https://ru.wikipedia.org/wiki/Сериализация
- https://databricks.com/glossary/tungsten

