 645
645 
Содержание
Продолжая разбирать тонкости сериализации данных в Apache Kafka на практических примерах, сегодня рассмотрим кейс индийской ИТ-компании Naukri Engineering о повторной обработке сообщений и особенностях форматов. Читайте далее, чем хороши заголовки Kafka и почему их не так просто использовать, а также зачем писать свой сериализатор с десериализатором для достижения 100%-ного SLA.
100% SLA и повторные попытки обработки сообщений в Apache Kafka
В компании Naukri соглашение об уровне обслуживания (SLA, Service Level Agreements) по доставке и потреблению сообщений через кластер Apache Kafka предполагает практически полное отсутствие потерянных данных. Поэтому дата-инженерам необходимо предупредить следующие проблемы на стороне Kafka или у потребителя [1]:
- отказ продюсера. Чтобы не потерять сообщения при сбое producer’а их необходимо записать в резервный кластер Kafka в общий топик резервного копирования (common back up topic) на отдельном кластере и через некоторое время повторить попытку записи в исходный топик основного кластера.
- сбой потребителя. Поместить сообщения, которые не могут быть обработаны при потреблении, в общий топик повторных попыток (common retry topic), чтобы потом снова повторить попытку их обработки.
Изначально в Naukri сообщения были в формате JSON, включая блок метаданных внутри самой записи. Эти метаданные нужны для топиков резервного копирования и повторных попыток, т.к. содержат информацию о groupId и исходных названиях топиков в стандартном виде. Для получения этой информации нужно десериализовать JSON-объект и извлечь нужные сведения из метаданных. Однако, это означает необходимость использования стандартного формата сообщений Kafka, чтобы передать эти метаданные без десериализации сообщения, не заставляя все команды разработчиков менять AVRO-схемы с учетом метаданных. Это можно решить с помощью заголовков Kafka, которые позволяют передавать метаданные, не делая их частью основного сообщения, а прикрепляя в их к нему виде пар ключ-значение. Так можно обрабатывать AVRO-сообщения как байтовые блобы (BLOB, Binary Large Object — двоичный большой объект) — массив двоичных данных, специальный тип данных для хранения изображений и компилированного программного кода.
Здесь используется распространенная для сетевых систем концепция заголовков и полезной нагрузки. Полезная нагрузка, роль которой в Kafka играет само сообщение, предназначена для бизнес-данных, а заголовки обычно используются для транспортной маршрутизации, фильтрации и прочих обслуживающих действий. Заголовки, как правило, представляют собой пары ключ-значение.
Концепция заголовков появилась в Apache Kafka 0.11. Заголовок — это пара «ключ-значение», и в каждое сообщение Kafka можно включить несколько заголовков с ключом, значением и меткой времени. Если значение содержит информацию о схеме, тогда заголовок будет иметь ненулевую схему.
Однако, поскольку сообщения в Kafka сжимаются, изначально добавлять собственные данные к заголовку было невозможно. Обойти это ограничение можно с помощью API-интерфейса Header, который добавляет заголовки к ProducerRecord и ConsumerRecord, а также представляет их сериализаторам и десериализаторам [2, 3, 4].
Именно этот подход использовали разработчики Kafka в компании Naukri, попутно решая проблему отправки данных в общие резервные топики, что мы рассмотрим далее.
Расширение сериализатора и десериализатора AVRO
Еще одной проблемы стала отправка данных в общие резервные топики с разными схемами данных для повторных попыток в случае сбоев на стороне производителя или потребителя. Это обусловлено тем, в Confluent 4.0.0 и Kafka 1.1.0, которые использовались в Naukri, имена схем AVRO связаны с именами топиков. В новых версиях это реализовано по-другому, но обновление всей инфраструктуры для Naukri требовало слишком много изменений. Поэтому было решено расширить стандартный сериализатор AVRO, передавая ему исходное название топика через заголовки Kafka. Это позволяет избежать потери данных при сбое в основном Kafka-кластере, передавая сообщения в общий топик в резервном кластере.
Для расширения сериализатора AVRO с концепцией заголовков написан следующий код:
public class KafkaAvroSerializerWithOriginalTopic extends
KafkaAvroSerializer implements
ExtendedSerializer<Object> {
@Override
public byte[] serialize(String topic, Headers headers, Object data)
{
Header targetTopicHeader = headers.lastHeader(HEADER_NAME_TARGET_TOPIC);
if (targetTopicHeader != null)
{
return super.serialize(new String(targetTopicHeader.value()), data);
}
return super.serialize(topic, data);
}
}
Аналогичным образом был расширен стандартный десериализатор AVRO, чтобы он возвращал объект с десериализованными данными и исходные данные в байтовом формате, считанные потребителем. Так в случае ошибки на стороне потребителя, исходные данные будут помещены в топик повтора вместо повторной сериализации данных. Это позволяет избежать потребителей с другой версией схем, генерирующих излишние исключения. Добавление новых обязательных полей обеспечит прямую совместимость, не затрагивая других имеющихся потребителей. Для этого написан следующий код AVRO-десериализатора:
public class KafkaAvroDeserializerWithOriginalData extends KafkaAvroDeserializer
{
@Override
public Object deserialize(String s, byte[] bytes)
{
try
{
return new AvroConsumerPayload<>(super.deserialize(s, bytes), bytes, true);
}
catch (Exception ex)
{
return new AvroConsumerPayload<>(null, bytes, false);
}
}
}
Таким образом, слушая резервные топики, можно анализировать сообщения на основе JSON и извлекать метаданные. Но если топик содержит несколько сообщений Avro, которые рассматриваются как набор байтовых блобов, их невозможно сериализовать. Решить эту проблему помогут заголовки Kafka, содержащие метаданные с названием исходного топика и groupId, добавляемые при отправке сообщений в резервные топики. Это позволяет возвращать данные в нужный топик на основе данных из заголовка AVRO-сообщения без разбора его содержимого.
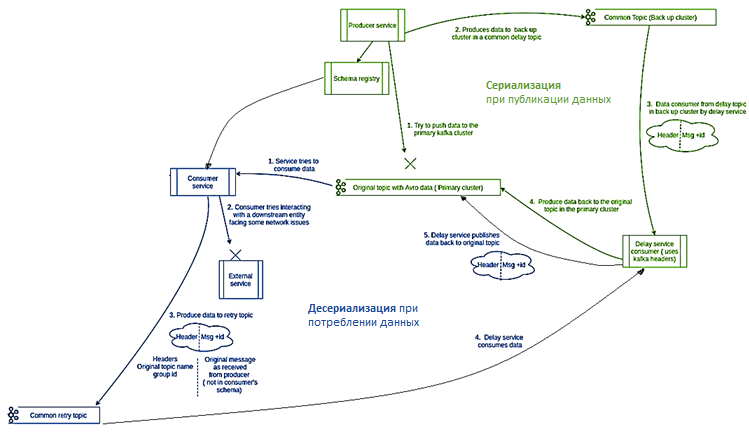
В результате всех вышеописанных манипуляций, компания Naukri смогла гарантировать необходимый уровень SLA для всех своих команд, использующих Apache Kafka в качестве средства оперативного обмена данными [1].
О том, как устроен реестр схем в Apache Kafka, мы писали здесь. А вспомнить особенности формата AVRO поможет эта статья. Больше практических примеров администрирования и эксплуатации Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/naukri-engineering/retry-with-avro-in-kafka-82d9fe9dcc
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-82+-+Add+Record+Headers
- https://www.confluent.io/blog/5-things-every-kafka-developer-should-know/
- https://cwiki.apache.org/confluence/display/KAFKA/A+Case+for+Kafka+Headers

