 675
675 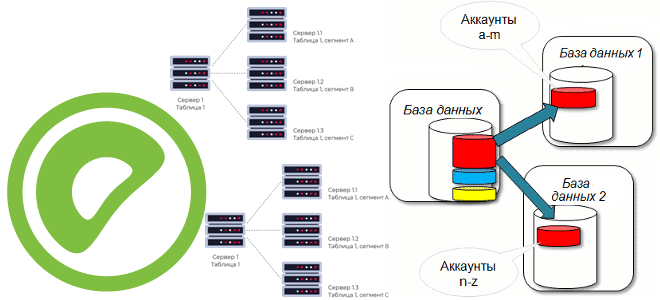
В этой статье для дата-инженеров и ИТ-архитекторов поговорим про шардирование баз данных и разберем, как этот способ горизонтального масштабирования системы реализуется в MPP-СУБД Greenplum, при чем здесь ключ дистрибуции и как его задать.
Что такое шардирование БД и как оно работает
Чтобы повысить производительность приложения через увеличение пропускной способности СУБД без вертикального масштабирования, можно применить масштабирование, распараллелив базу данных. Это называется шардированием (sharding) и означает разделение объектов базы данных на независимые сегменты, каждый из которых управляется своим экземпляром сервера, обычно размещаемым на отдельном вычислительном узле. В отличие от простого разделения на разделы (партиционирование), где разные части объектов базы данных хранятся под управлением единого экземпляра СУБД, шардирование это в чистом виде распределенные вычисления. Поэтому шардирование сложнее в реализации, т.к. требует множества компонентов, чтобы приложения работали со всеми сегментами так, будто это по-прежнему единая БД.
Поскольку шардирование означает разделение набора данных и нагрузки по нескольким узлам СУБД, нужно понимать, по какому принципу реализуется это разделение. Как правило, данные разделяются по какому-то признаку, т.е. ключу: записи с одинаковым значением ключа шардирования группируются в единый набор данных, который хранится на одном вычислительном узле, что облегчает обработку. При выборе ключ шардирования следует учитывать его кардинальность, т.е. множественность связей (1-1, 1-n, n-n) и неизменяемость, а также частоту использования в SQL-запросах. Корректный выбор ключа шардирования обеспечит равномерное распределение данных по узлам кластера, что повысит производительность операций чтения и снизит нагрузку на балансировщик.
Шардирование также называют горизонтальным партиционированием, поскольку логически независимые строки таблицы БД группируются в разделы и хранятся на разных, физически и логически независимых серверах базы данных. Напомним, один физический узел кластера может содержать несколько серверов баз данных. Часто в качестве ключа шардирования используется хэш функции от идентификационных данных клиента, чтобы однозначно привязать заданного клиента и все его данные к отдельному и заранее известному экземпляру баз данных (шарду), обеспечив горизонтальную масштабируемость. Также в качестве ключа шардирования можно использовать идентификатор поля таблицы.
Таким образом, в отличие от вертикального масштабирования, шардирование позволяет увеличить мощность системы без наращивания вычислительных возможностей, которые ограничены физически (максимальное число CPU на один сервер, объем памяти, пропускная способность шины и пр.).
Кроме того, шардирование снижает затраты на согласованное чтение данных: логически независимые серверы БД не требуют взаимной монопольной блокировки, устраняя лимит на количество одновременно обрабатываемых пользовательских запросов в кластере в целом. Не все СУБД поддерживают изначально шардирование, а где-то оно реализовано по молчанию. Например, MPP-СУБД Greenplum на основе PostgreSQL поддерживает автоматическое разделение данных, позволяя параллельно обрабатывать множество аналитических запросов. Как это реализовано, рассмотрим далее.
Шардирование в Greenplum
В Greenplum и основанной на ней Arenadata DB реализуется классическая схема шардирования данных, когда каждая таблица разделяет на несколько частей, каждая из которых размещается на отдельном хосте-сегменте кластера. При этом любой SQL-запрос на запись или чтение данных использует все сегменты кластера, реализуя горизонтальное масштабирование. Логика разделения таблицы на сегменты задается ключом дистрибуции, который по умолчанию определяется случайным образом, чтобы равномерно распределить данные по сегментам. Именно дистрибуция (Distribution) определяет, в какие строки таблицы сегментов данные назначаются, а разделение (Partitioning) определяет, как они хранятся в каждом из сегментов. Таким образом, дистрибуция — это физическое разделение хранимых данных, а партиционирование — логическое. Подробно об этом мы писали здесь.
Для оптимизации выполнения операций соединения больших таблиц можно явно определить ключ дистрибуции, чтобы SQL-запрос с оператором JOIN по указанным в ключе полям выполнялся локально на сегменте, это будет быстрее. Чтобы создать таблицу с ключом дистрибуции, следует указать этот столбец как аргумент функции DISTRIBUTED BY в DDL-запросе:
CREATE TABLE tableName ( column1 type1, column2 type2, ... columnN typeN ) DISTRIBUTED BY (column1);
Неверно выбранный ключ дистрибуции приведет к тому, что большая часть данных будет располагаться на одном сегменте, снижая производительность кластера. Это даже может вызвать остановку работы сегмента, когда на его хосте закончится место. Поэтому не рекомендуется использовать в качестве ключа дистрибуции поля с временем и датой, с большим количеством одинаковых или пустых значений. Также ключ разделения (partition key) должен всегда отличаться от ключа дистрибуции (distribution key). Читайте в нашей новой статье про горизонтальное масштабирование кластера GP путем добавления новых узлов.
Освойте администрирование и эксплуатацию Greenplum с Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://habr.com/ru/company/stm_labs/blog/650327/
- https://ru.bmstu.wiki/Шардирование_баз_данных
- https://greenplum.org/relationship-and-difference-between-greenplum-and-postgresql/
- https://cloud.yandex.ru/docs/managed-greenplum/concepts/sharding
- https://docs.arenadata.io/adb/v6.18.2_arenadata30/index/

